解决高分辨率生成痛点:CineScale 新范式优化扩散模型,支持 8K 图像与 4K 视频合成视觉扩散模型虽已取得显著进展,但受限于“高分辨率训练数据稀缺”与“计算资源消耗大”,多数模型只能在低分辨率(如512×512)下训练,导致生成高保真图像、视频时容易出现“重复模式”“细节模糊”等问题...视频模型# CineScale# 高分辨率生成5个月前03190
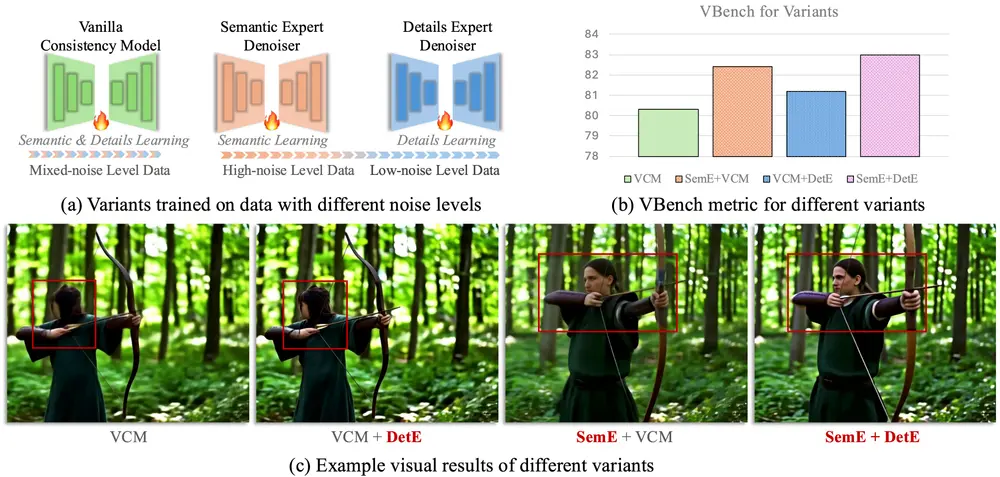
DCM:双专家一致性模型,实现高效高质量视频生成扩散模型在图像和视频合成任务中展现出卓越性能,但其依赖多步迭代去噪的过程,导致计算成本高昂。为解决这一问题,一致性模型(Consistency Models) 在加速扩散模型方面取得了重要进展。 然而...视频模型# DCM# 一致性模型8个月前03190
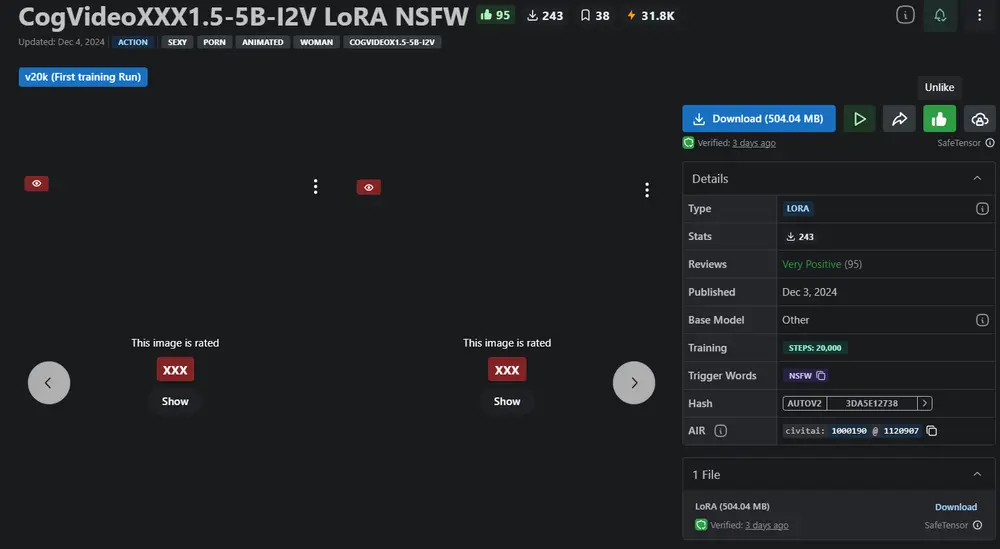
CogVideoXXX1.5-5B-I2V LoRA NSFW :基于 CogVideoX1.5-5B 的LoRA模型,专门针对NSFW内容进行了训练CogVideoXXX1.5-5B-I2V LoRA NSFW 是一个基于 CogVideoX1.5-5B 的LoRA模型,专门针对NSFW内容进行了训练。该模型在处理NSFW内容时表现出色,但也具备...视频模型# CogVideoX1.5-5B# LoRA模型12个月前03190
StreamDiT:实现实时流式文本到视频生成的新一代扩散模型近年来,随着基于变换器(Transformer)的扩散模型向数十亿参数扩展,文本到视频(Text-to-Video, T2V)生成技术取得了显著进展。尽管当前模型已能生成高质量视频内容,但它们通常只能...视频模型# StreamDiT# 流式视频生成模型7个月前03180
阿里旗下PAI项目组开源了视频生成模型Wan 2.1 的控制模型Wan2.1-Fun系列,支持Canny、Depth、Pose、MLSD等多种模式阿里旗下PAI项目组开源了视频生成模型Wan 2.1 的控制模型,支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制。 模型地址:https://huggingf...视频模型# Wan 2.1# Wan2.1-Fun-1.3B-Control# Wan2.1-Fun-1.3B-InP10个月前03180
腾讯发布一种在 MM-DiT 架构下无需额外训练的多提示长视频生成方法DiTCtrl随着视频生成模型的发展,基于DiT架构如 Sora 和 MM-DiT 在单提示视频生成任务中取得了显著进展。然而,这些模型在处理多个顺序提示时面临诸多挑战,难以生成连贯且自然过渡的场景。具体来说: 严...视频模型# DiTCtrl12个月前03160
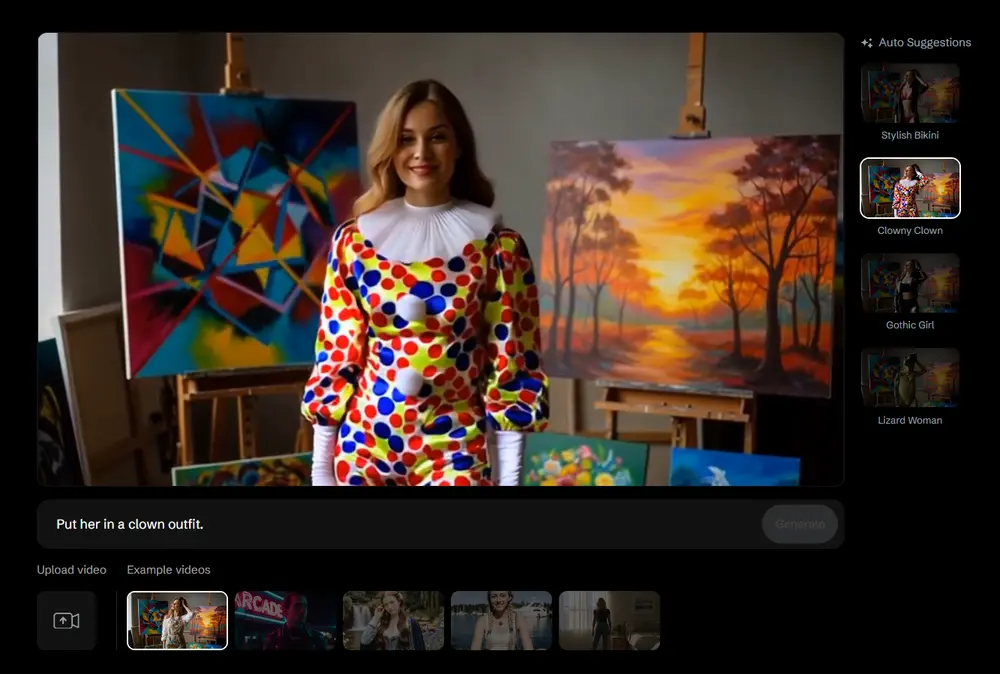
DecartAI推出 Lucy Edit Dev:全球首个开源、支持自由文本提示的指令引导视频编辑模型DecartAI推出 Lucy Edit Dev ——全球首个开源、支持自由文本提示的指令引导视频编辑模型。它允许用户仅通过自然语言描述,即可完成复杂的视频修改任务,如更换服装、替换角色、插入物体或更...视频模型# Lucy Edit Dev# 视频编辑模型4个月前03090
新型3D感知视频扩散模型Diffusion as Shader:通过3D控制信号实现多样化且精确的视频生成控制香港科技大学、浙江大学、香港大学、南洋理工大学、武汉大学和德克萨斯A&M大学的研究人员推出新型3D感知视频扩散模型Diffusion as Shader (DaS) ,旨在通过3D控制信号实现多样化且...视频模型# Diffusion as Shader# 视频生成控制12个月前03090
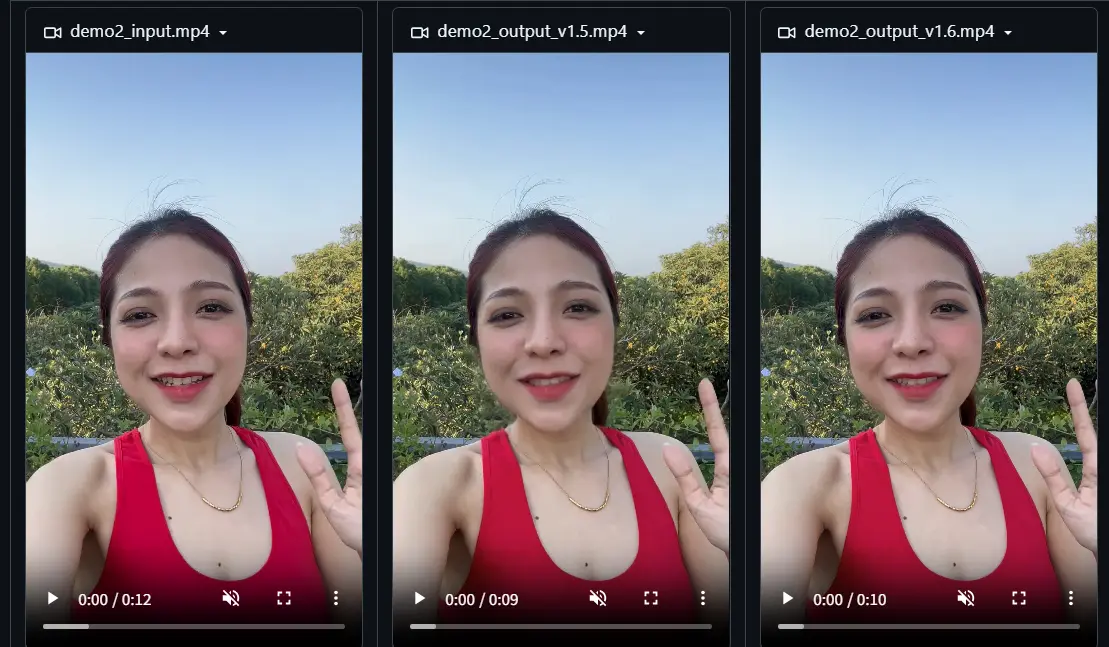
字节跳动发布 LatentSync 1.6:聚焦高分辨率视频生成,解决模糊问题字节跳动发布了其对口型视频生成模型 LatentSync 的新版本 1.6,重点解决了此前版本中生成牙齿和嘴唇区域模糊的问题。 模型:https://huggingface.co/ByteDance...视频模型# LatentSync 1.6# 字节跳动8个月前03060
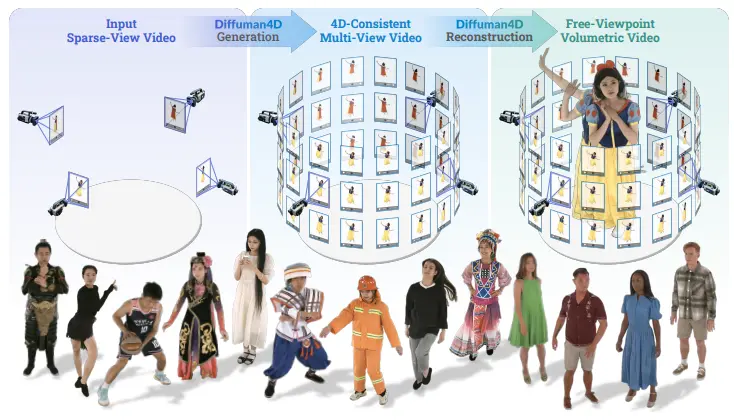
新型扩散模型 Diffuman4D :从稀疏视角视频中生成高质量、4D 一致的人体自由视角视频浙江大学和蚂蚁研究的研究人员推出新型扩散模型 Diffuman4D ,从稀疏视角视频中生成高质量、4D 一致的人体自由视角视频。该模型通过引入滑动迭代去噪过程和基于人体骨骼的姿态条件机制,显著提升了生...视频模型# Diffuman4D# 人体自由视角视频7个月前03010
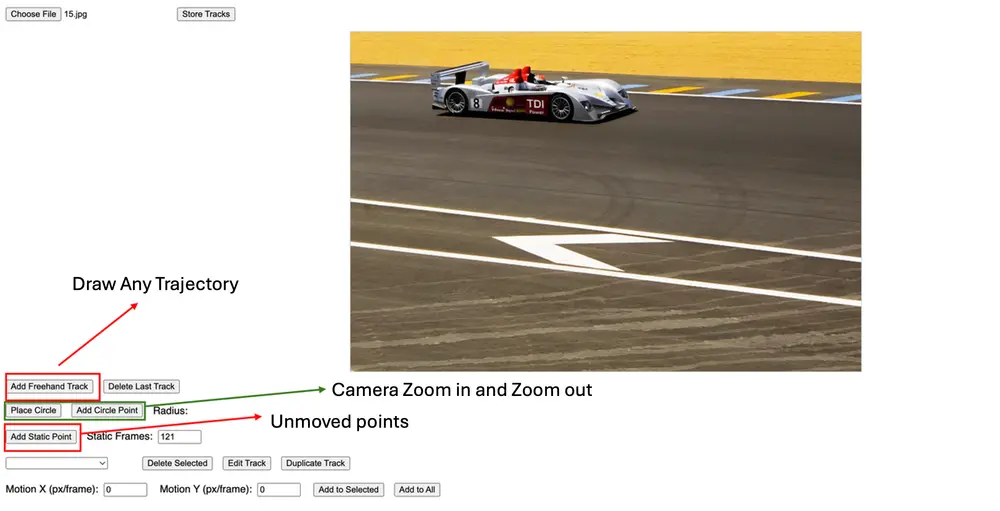
字节跳动推出全新视频生成框架 ATI:用“画轨迹”控制视频运动,对象、视角、局部变形一应俱全!字节跳动 AI 实验室发布了一项令人眼前一亮的视频生成技术 —— ATI(Any Trajectory Instruction),它让普通人也能通过“画轨迹”的方式,精准控制视频中物体的运动、镜头的移...视频模型# ATI# ATI-Wan2.1 14B# 字节跳动8个月前03000
阶跃星辰开源300 亿参数文生视频模型Step-Video-T2V:能够生成长达 204 帧的高质量视频由前微软全球副总裁、微软亚洲互联网工程院首席科学家姜大昕创办的AI公司阶跃星辰,开源了一款强大的文生视频模型——Step-Video-T2V。该模型拥有 300 亿参数,能够生成长达 204 帧的高质...视频模型# Step-Video-T2V# Step-Video-T2V-Turbo# 文生视频模型12个月前02980