字节跳动推出基于Flux的通用框架UNO:支持虚拟试穿、风格化生成、产品设计等功能字节跳动近日推出了UNO,这是一个强大的通用框架,能够从单一主体到多主体进行定制化演进。UNO不仅展示了出色的泛化能力,还能将多样化的任务统一在一个模型之下,为图像生成领域带来了新的突破。 项目主页...图像模型# FLUX# UNO# 字节跳动10个月前06420
IDAdapter:根据单张面部照片和文本提示,生成多种风格、角度和表情的个性化图像,而无需在推理阶段进行任何微调来自北京大学、InsightFace和格灵深瞳推出IDAdapter,它能够根据单张面部照片和文本提示,生成多种风格、角度和表情的个性化图像,而无需在推理阶段进行任何微调。 论文 IDAdapter通...图像模型# IDAdapter# 个性化图像12个月前06410
Fal.ai平台推出新DiT模型AuraFlow:支持文字,百分百开源Stability AI因为Stable Diffusion 3 Medium模型的许可证问题备受诟病,虽然后来更改了许可证,但此模型在人物尤其是躺倒后人物的糟糕表现还是不受开源社区待见。不少人开始转...图像模型# AuraFlow# DiT模型# Fal.ai12个月前06400
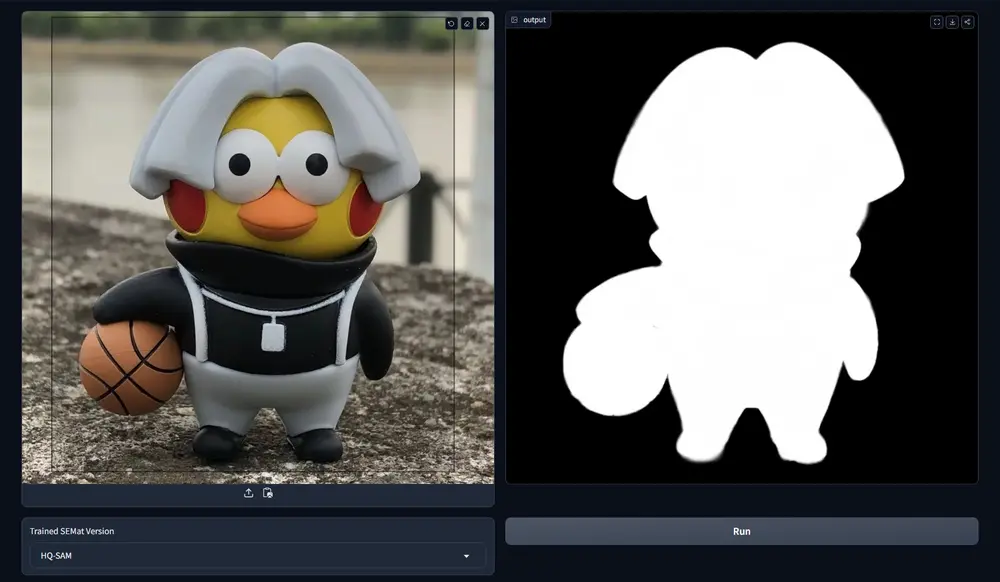
新型图像抠图方法SEMat:能够在复杂的自然场景中实现更精确的前景对象抠图近年来,交互式分割模型(如 SAM)在图像分割任务中取得了显著进展。然而,这些模型在应用于交互式抠图任务时面临挑战,尤其是在处理复杂和遮挡场景时。现有的方法通常在合成数据上训练模型,但这些模型难以泛化...图像模型# SEMat# 图像抠图12个月前06220
欧美漫画及插画风格SDXL模型:CHEYENNE_CHEYENNE_是一款专门针对欧美漫画及插画风格生成的SDXL模型。不论你是专业插画家、漫画家,还是热衷于视觉艺术表达的爱好者,CHEYENNE都将为你的创意世界打开全新维度! 模型下载地址 CH...图像模型# CHEYENNE# SDXL模型# 插画12个月前06160
黑森林实验室正式发布图像编辑模型FLUX.1 Kontext [dev]截至今日,所有高性能的生成式图像编辑模型均为专有工具。今天,这一局面发生了改变。 黑森林实验室(Black Forest Labs)发布了 FLUX.1 Kontext [dev],这是 FLUX.1...图像模型# FLUX.1 Kontext [dev]# 图像编辑模型# 黑森林实验室7个月前05890
智谱AI推出图像生成模型 CogView3 以及 CogView-3Plus清华和智谱 AI的研究团队开源了图像生成模型 CogView3 以及CogView-3-Plus ,CogView3 是一个基于级联扩散的文本生成图像系统,采用了接力扩散(relay diffusio...图像模型# CogView-3Plus# CogView3# 图像生成12个月前05860
基于扩散的肖像动画生成新方法JoyVASA:用于生成音频驱动的面部动画,包括面部动态和头部运动音频驱动的肖像动画在基于扩散模型的推动下取得了显著进展,提高了视频质量和唇同步的准确性。然而,这些模型的复杂性增加导致了训练和推理的低效,以及对视频长度和帧间连续性的限制。为了解决这些问题,京东健康国...图像模型# JoyVASA# 肖像动画12个月前05840
Nunchaku发布量化版Qwen-Image模型,支持高效图像生成Nunchaku 官方宣布,其基于Qwen-Image的四个量化版本模型已正式上线 Hugging Face和魔塔!这些模型专为高效文本到图像生成而优化,尤其在复杂文本渲染方面表现突出。 Huggin...图像模型# Nunchaku# Qwen-Image6个月前05760
新型文生图模型YaART:利用人类反馈的强化学习与人类偏好进行对齐来自俄罗斯Yandex、斯科尔科沃科学技术学院、莫斯科国立大学和高等经济学院的研究团队推出新型的、适用于生产环境的文本到图像级联扩散模型YaART(Yet Another Art Rendering ...图像模型# YaART# 文生图模型12个月前05690
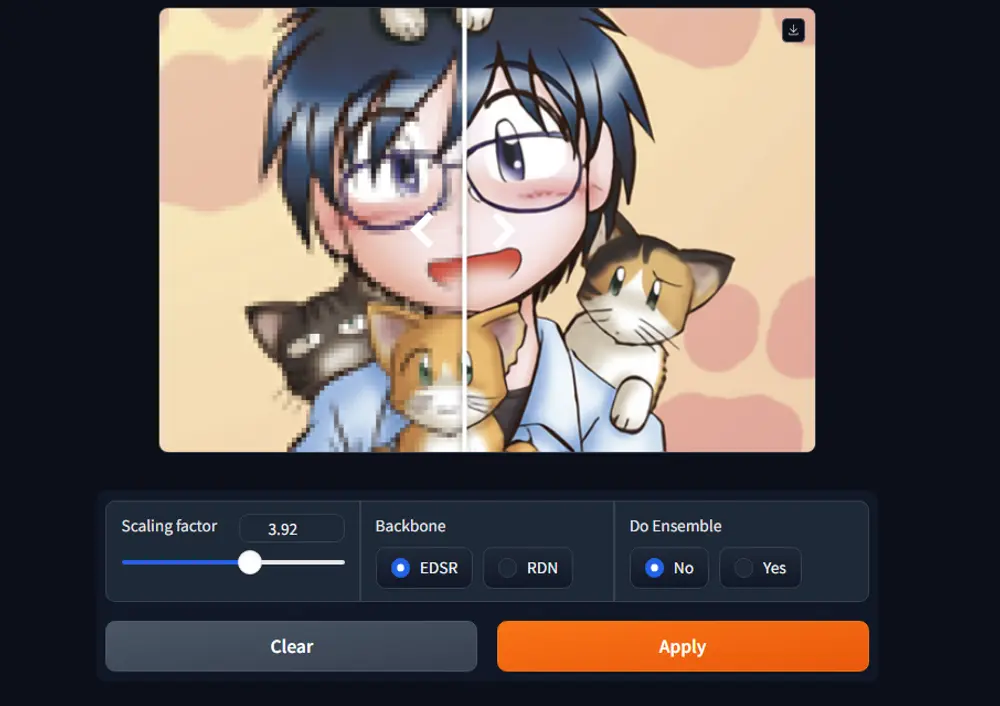
基于神经热场的无混叠任意尺度超分辨率(ASR)方法Thera:实现高质量的图像超分辨率重建苏黎世联邦理工学院和苏黎世大学的研究人员推出一种基于神经热场(Neural Heat Fields)的无混叠任意尺度超分辨率(ASR)方法Thera,该方通过结合神经场(Neural Fields)和...图像模型# Thera# 图像放大# 图像高清11个月前05680
MagicTailor框架:让用户对生成的图像中的特定视觉元素进行精确控制近年来,文本到图像(T2I)扩散模型取得了显著进展,能够从简单的文本提示中生成高质量的图像。然而,这些模型在精确控制特定视觉概念生成方面仍然面临挑战。现有的方法可以通过参考图像学习复制给定的概念,但缺...图像模型# MagicTailor# 图像定制12个月前05600




![黑森林实验室正式发布图像编辑模型FLUX.1 Kontext [dev]](https://pic.sd114.wiki/wp-content/uploads/2025/06/1750964036-1750964036-FLUX.1-Kontext-2.webp~tplv-o4t1hxlaqv-image.image)