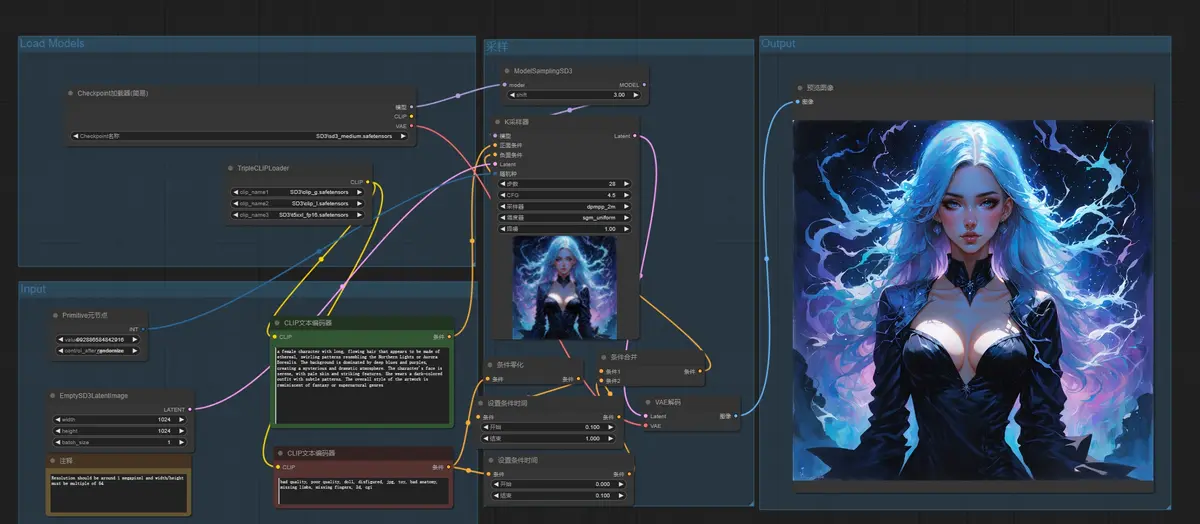
Stability AI释出Stable Diffusion 3 Medium模型,8G显存显卡即可使用Stability AI终于在6月12日释出了万众期待的Stable Diffusion 3模型,不过此次释出的仅是 20 亿个参数的Stable Diffusion 3 Medium 模型,该型号尺...图像模型# SD3模型# Stability AI# Stable Diffusion 3 Medium12个月前05,0480
Illustrious XL v2.0正式发布,支持1024x1536原生分辨率生成在开源AI绘画模型领域,Flux模型是众多衍生开发的基础。然而,在二次元领域,尤其是日式风格方面,情况有所不同。目前,大量用户依然以SDXL模型为基础进行衍生开发。在开源社区中,Pony、Illust...图像模型# Illustrious XL v2.0# SDXL# 二次元11个月前02,5360
高级插图模型Illustrious:专门针对插画和动画任务进行了优化,主要用于生成动漫风格的图像OnomaAI 研究小组推出一个高级插图模型Illustrious,它主要用于生成动漫风格的图像。Illustrious XL是一个基于SDXL的模型,专门针对插画和动画任务进行了优化。它是基于 Ko...图像模型# Illustrious# Illustrious XL# 插图模型12个月前01,2190
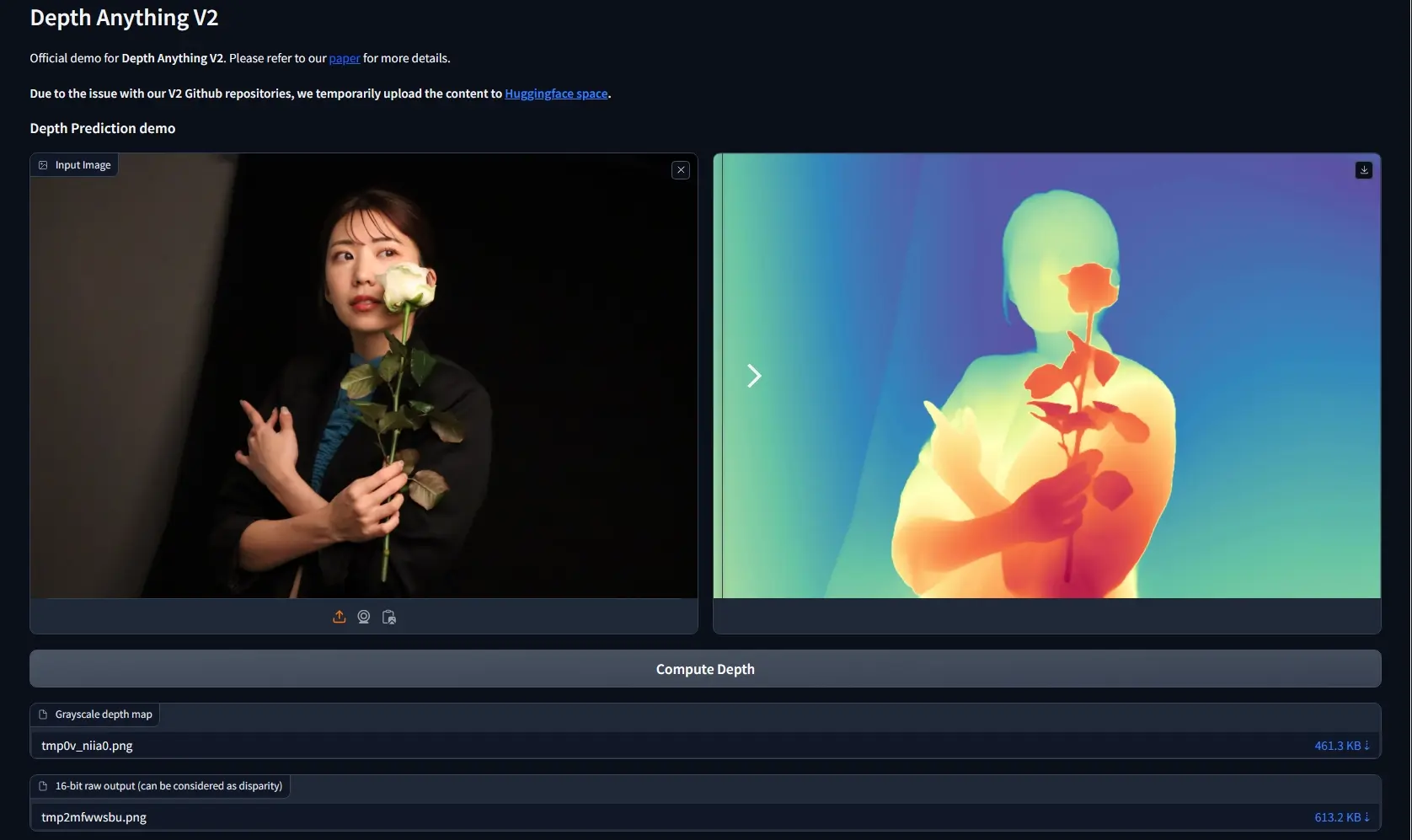
单目深度估算模型Depth Anything V2:通过分析单张图片来预测物体距离来自香港大学和TikTok的研究人员推出单目深度估算模型Depth Anything的升级版Depth Anything V2,让计算机通过分析单张图片来预测物体距离的技术,这在自动驾驶、3D建模和虚...图像模型# Depth Anything V2# 单目深度估算模型12个月前01,2070
字节跳动推出新型蒸馏模型Hyper-SD:基于SD1.5和SDXL1.0基础模型提炼字节跳动在推出文生图模型SDXL-Lightning后,又推出了新的蒸馏模型Hyper-SD,它有效地结合了ODE轨迹保留和重构的优点,同时在步骤压缩过程中保持了接近无损的性能。与SDXL-Light...图像模型# Hyper-SD# 字节跳动# 蒸馏模型12个月前01,1830
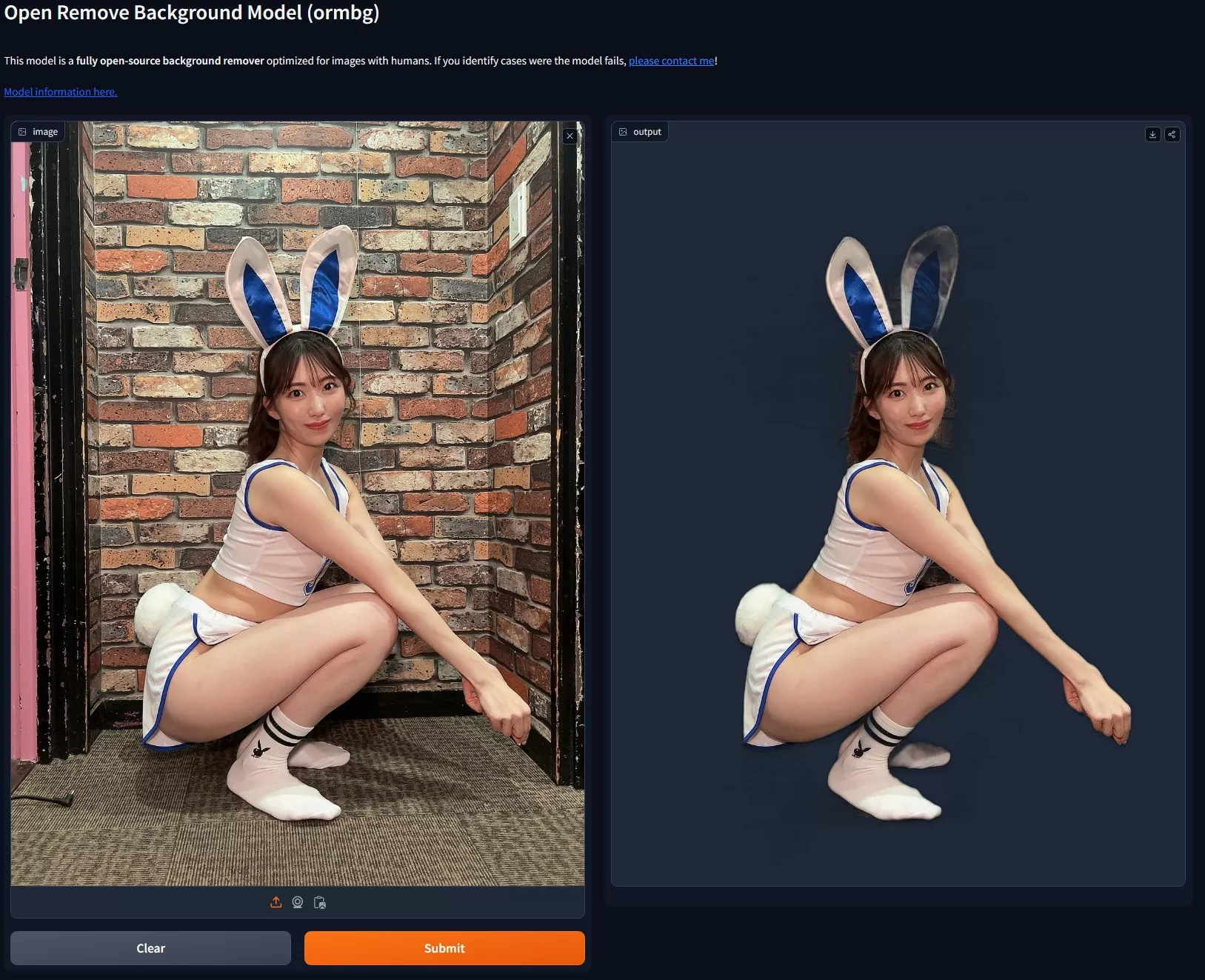
全新开源背景移除模型ormbg:专门针对含有人物的图像进行了优化ormbg是一个基于基于高度准确的二分类图像分割(DIS)的全新开源背景移除模型,它专门针对含有人物的图像进行了优化,此模型类似于 RMBG-1.4,但提供了开放的训练数据和流程,且商业使用免费。它提...图像模型# DIS# ormbg# 背景移除模型12个月前01,1690
虚拟服装试穿Magic Clothing:根据特定的服装和文本提示来生成穿着这些服装的定制化角色图像小i研究院发布了OOTDiffusion的分支版本Magic Clothing,它能够根据特定的服装和文本提示来生成穿着这些服装的定制化角色图像。这项技术的核心在于高度的图像可控性,即在生成的图像中保...图像模型# Magic Clothing# 虚拟服装试穿12个月前01,1170
图像编辑框架ByteEdit:提升基于扩散模型的生成性图像编辑任务的性能字节跳动推出图像编辑框架ByteEdit,这是一个精心设计的创新反馈学习框架,旨在增强生成图像编辑任务的效果、提升遵从度,并加速处理速度。它专门用于提升基于扩散模型的生成性图像编辑任务的性能。Byte...图像模型# ByteEdit# 图像编辑框架12个月前01,0790
新型文生图模型CoMat:更好地理解和执行文本描述,提高了文本到图像生成的质量和准确性来自香港中文大学、商汤科技和上海人工智能实验室的研究人员推出新型文生图模型CoMat,这是一种具有图像到文本概念匹配机制的端到端扩散模型微调策略。开发团队借助图像字幕模型来评估图像与文本的对齐程度,并...图像模型# CoMat# 文生图模型12个月前01,0600
Chroma 模型家族正式发布:基于 FLUX.1-schnell,8.9亿参数开源无限制,4大分支适配不同需求开发者 lodestones 近期宣布,基于 FLUX.1-schnell 构建的 8.9 亿参数生成模型 Chroma 已完成全部基础训练,正式开放供开发者与研究者使用。作为完全遵循 Apache ...图像模型# Chroma# FLUX.1 [schnell]5个月前01,0470
Stable Diffusion 1.5Stable Diffusion 1.5 是由 Runway ML 开发,基于 Stable Diffusion 1.2 版本,于2022年10月发布,并进行了以下改进: 使用了更大的模型:Stabl...图像模型# Runway ML# Stable Diffusion 1.5# 模型12个月前01,0350
SDXL系列新模型SDXL Flash:高速且保证质量的SDXL模型Stable Diffusion Community是一个非官方、非盈利性质的组织,它们主要目标是尽可能改进 SD 模型并让每个人都可以使用它们,近期它们推出了新的SDXL系列模型SDXL Flash...图像模型# SDXL Flash# sdxl-flash-mini# 高速模型12个月前01,0260