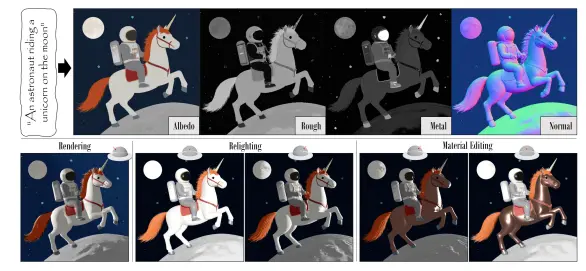
MARBLE:基于 CLIP 空间的图像材质编辑新方法在计算机视觉与图形学领域,图像中对象材质的编辑是一项具有挑战性的任务。传统方法往往依赖复杂的建模与渲染流程,而近年来,借助预训练扩散模型与语义嵌入空间(如CLIP)的技术逐渐成为研究热点。 项目主页...图像模型# MARBLE# 图像材质编辑8个月前02770
全新CLIP架构改进方案 CLIP-fine-tune-registers-gatedCLIP(对比语言-图像预训练)是 OpenAI 开发的一种多模态模型,通过对比学习在大量图像-文本对上训练,将图像和文本嵌入到同一个共享空间中,便于零样本任务。然而,CLIP 在处理全局信息时存在一...图像模型# CLIP# CLIP-fine-tune-registers-gated11个月前02740
基于DiT模型的多领域程序化序列生成框架MakeAnything:根据文本描述或图像生成分步骤的教程新加坡国立大学的研究团队推出 MakeAnything,这是一个基于DiT模型的多领域程序化序列生成框架,能够根据文本描述或图像生成分步骤的教程,也就是生成一致性图片序列。 GitHub:https...图像模型# DiT模型# MakeAnything12个月前02670
开源版GPT‑4o?新型多模态生成模型 Liquid,用一个模型搞定视觉与语言任务在OpenAI旗下GPT‑4o凭借原生生成及编辑图像功能,火爆网络后,大家都在期待有相对应的开源模型推出。而将视觉和语言任务高效整合一直是研究的热点。华中科技大学、字节跳动和香港大学的研究人员推出了新...图像模型# GPT‑4o# OpenAI# 多模态生成模型10个月前02630
字节跳动推出新型图像编辑方法 SuperEdit :通过改进监督信号来提升基于指令的图像编辑性能字节跳动和佛罗里达中央大学计算机视觉研究中心的研究人员推出新型图像编辑方法 SuperEdit ,通过改进监督信号来提升基于指令的图像编辑性能。 项目主页:https://liming-ai.gith...图像模型# SuperEdit# 图像编辑# 字节跳动9个月前02580
对角蛇形扫描自回归图像生成框架DAR:用于生成高质量图像的新型自回归模型传统的自回归图像生成方法(如VQGAN)通常按照光栅扫描(raster scan)顺序生成图像令牌。这种方式在行末换行时会导致相邻令牌之间的欧几里得距离过大,从而影响生成效果。例如,当生成一张256...图像模型# DAR# 自回归模型10个月前02550
IntrinsiX:能够直接从文本描述生成高质量的物理基础渲染(PBR)图像传统的文生图模型(如 Stable Diffusion)能够根据文本描述生成高质量的 RGB 图像,但这些图像通常包含固定的光照效果(如反射、阴影、高光),这限制了它们在需要 PBR 地图(如游戏、V...图像模型# IntrinsiX# PBR10个月前02530
基于图像编辑模型的 FE2E:革新单目密集几何预测在单目深度估计、表面法线预测等密集几何预测任务中,如何在有限标注数据下实现高精度的零样本泛化,一直是三维视觉的核心挑战。 近年来,研究者尝试利用文本到图像生成模型(如Stable Diffusion...图像模型# FE2E# 图像编辑5个月前02510
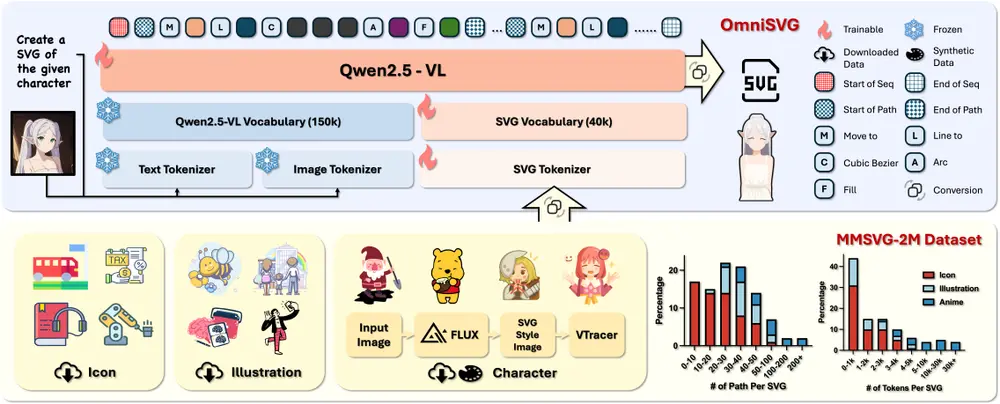
基于视觉语言模型的端到端多模态 SVG 生成框架OmniSVG:能够生成从简单图标到复杂动漫角色的高质量 SVG 图形复旦大学和阶跃星辰的研究人员推出基于视觉语言模型(VLMs)的端到端多模态 SVG 生成框架OmniSVG,能够生成从简单图标到复杂动漫角色的高质量 SVG 图形,支持文本到 SVG、图像到 SVG ...图像模型# OmniSVG# SVG# 视觉语言模型6个月前02510
基于蒸馏的多功能图像生成模型DMM:通过蒸馏模型合并技术实现多功能图像生成在文本到图像(Text-to-Image, T2I)生成领域,开发者通常会基于强大的基础模型(如Stable Diffusion 1.5)进行微调,以适应特定风格或场景的需求。例如,某些模型专注于生成...图像模型# DMM# 图像生成模型# 蒸馏模型10个月前02490
英伟达提出 DC-Gen:用于加速扩散模型的后训练框架,生成速度快 53 倍在文生图领域,高分辨率输出(如 4K)正成为标配。然而,随之而来的计算成本和推理延迟问题日益凸显——以当前领先的 FLUX.1-Krea-12B 模型为例,在英伟达H100 GPU 上生成一张 4K ...图像模型# DC-Gen# 文生图模型# 英伟达4个月前02450
Soul AI推出新型推出新型图像生成模型 TransDiff :将自回归(AR)Transformer 和扩散模型相结合,用于高质量的图像生成Soul AI推出新型图像生成模型 TransDiff ,该模型将自回归(AR)Transformer 和扩散模型相结合,用于高质量的图像生成。TransDiff 通过将输入编码为高级语义特征,并利用...图像模型# TransDiff# 图像生成模型7个月前02420