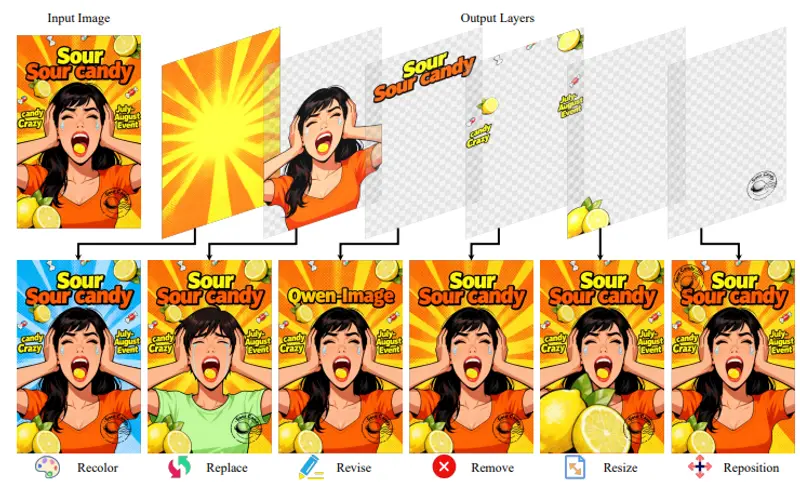
港科大与阿里推出Qwen-Image-Layered:将单图分解为可编辑RGBA图层,实现像素级精准编辑在传统图像编辑中,若想修改照片中的某个物体(如移动人物、更换背景、调整颜色),往往需要复杂的抠图、蒙版或手动重绘——操作繁琐,且容易破坏整体一致性。 由香港科技大学(广州)、阿里巴巴与香港科技大学联合...图像模型# Qwen-Image-Layered# RGBA图层# 编辑模型4个月前01890
MotionEdit:首个专注动作编辑的图像生成基准与训练框架当前主流的图像编辑模型在处理静态属性(如颜色、纹理、物体替换)时已相当成熟,但在修改图像中主体的动作、姿势或交互行为时仍面临显著挑战。例如,让一个人从“站立”变为“坐下”,或让其“拿起桌上的杯子”,现...图像模型# MotionEdit# 图像编辑4个月前0780
扩散模型加速框架Glance:仅用 1 张图 + 1 GPU 小时,将扩散模型加速至 8 步武汉大学、新加坡国立大学、中南大学、电子科技大学和微软的研究人员推出一个用于加速扩散模型(Diffusion Models)的轻量级框架 Glance,通过“慢-快”(Slow-Fast)的阶段感知...图像模型# Glance# 加速框架4个月前01290
阿里开源Ovis-Image:7B 参数实现高质量文本渲染的文生图模型,海报 / UI 设计秒生成Ovis-Image 是由阿里巴巴国际数字商务团队开发的 70亿参数 文本到图像(Text-to-Image)生成模型,专注于解决文生图系统中长期存在的文本模糊、拼写错误、排版失真等痛点。该模型在保持...图像模型# Ovis-Image# 文生图模型4个月前03000
阿里通义发布Z-Image-Turbo:60 亿参数高效图像模型,支持中英双语文本渲染与亚秒级生成在图像生成模型多依赖“大参数堆料”的行业趋势下,阿里通义MAX项目组推出的Z-Image,以60亿参数的轻量化体量实现了颠覆性突破。这款通过系统性优化打造的图像生成基础模型,不仅在照片级真实感生成、中...图像模型# Z-Image-Turbo4个月前03840
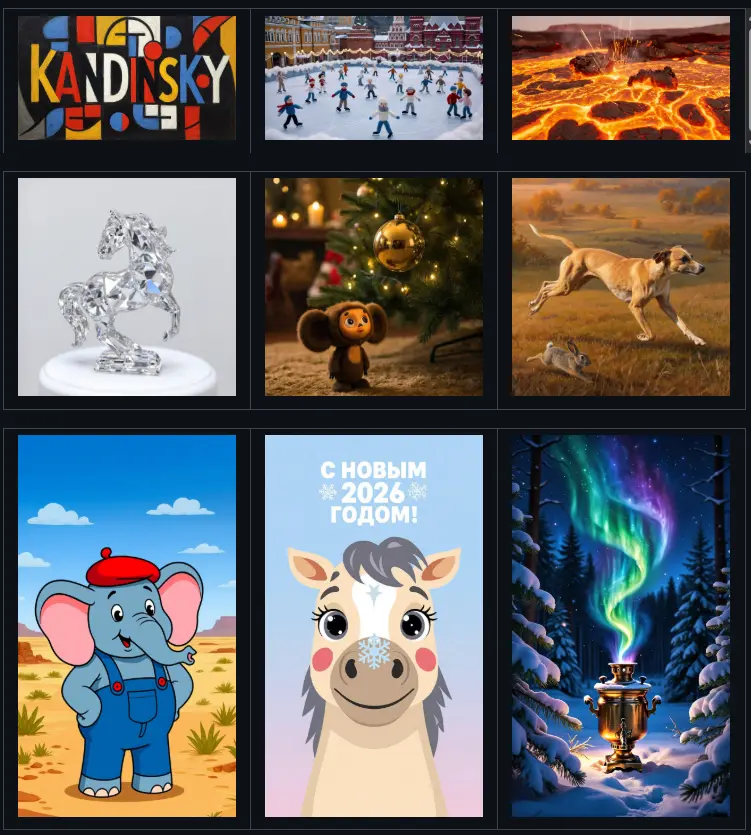
Kandinsky 5.0 全系列开源:190亿参数视频Pro+轻量版,支持中俄双语+5-10秒HD生成来自俄罗斯的AI企业Sber AI,正式推出新一代扩散模型家族 Kandinsky 5.0,以“全场景覆盖+开源开放”为核心亮点,涵盖视频生成(T2V/I2V)、图像生成(T2I)、图像编辑三大核心能...图像模型视频模型# Kandinsky 5.04个月前01960
黑森林实验室发布FLUX.2 :支持400万像素编辑+10图参考,开放权重模型刷新视觉AI上限在视觉AI领域,能够真正适配现实世界创意工作流的工具,往往比单纯的“演示级模型”更具价值。近日,黑森林实验室正式推出新一代视觉智能系统 FLUX.2,不仅在图像生成质量、细节还原度上实现突破,更以多参...图像模型# FLUX.2# 黑森林实验室4个月前01120
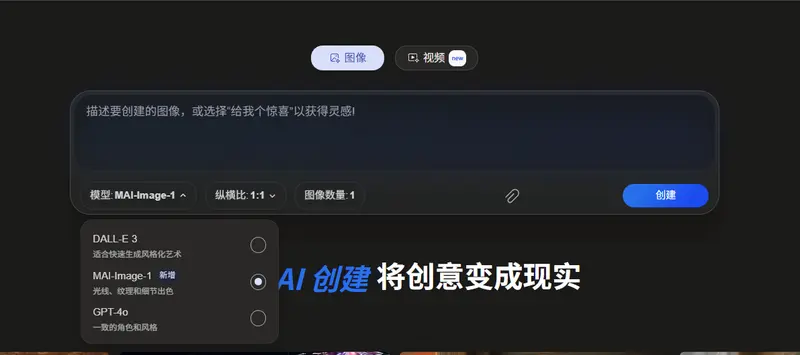
微软在Bing平台推出AI图像生成模型MAI-Image-1尽管微软已全面接入OpenAI最新前沿模型,该公司仍在自主研发AI模型,通过差异化产品与服务更好地满足用户需求。今年初,微软曾宣布首批两个自研AI模型:MAI-Voice-1与MAI-1-previe...图像模型# MAI-Image-1# 微软5个月前0480
BRIA 发布 FIBO:用 JSON 精确控制光线、构图与相机参数的文生图模型BRIA 开源发布了其首个文本到图像模型 FIBO —— 一个专为专业图像生成工作流设计的 JSON 原生、结构化提示驱动 的开源模型。与主流强调“想象力”的生成模型不同,FIBO 的核心目标是 可控...图像模型# BRIA# FIBO# 文生图模型5个月前01440
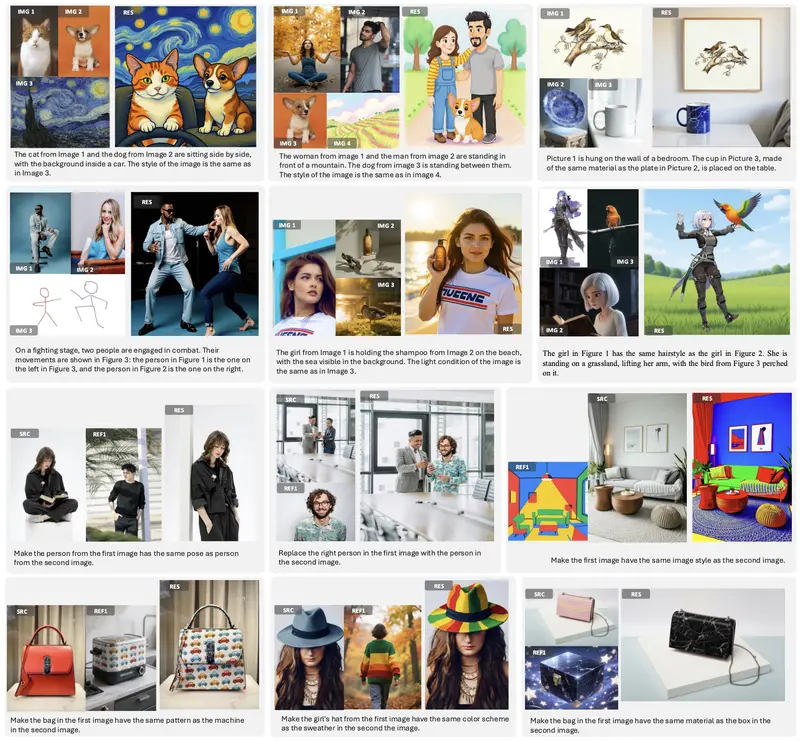
DreamOmni2:支持图文指令的统一图像生成与编辑模型香港中文大学、香港科技大学与字节跳动联合推出开源模型 DreamOmni2,旨在突破当前 AI 图像编辑与生成的两大瓶颈:纯文本指令表达力有限,以及现有模型难以处理抽象概念(如风格、纹理、妆容等)。 ...图像模型# DreamOmni2# 图像生成6个月前01860
英伟达提出 DC-Gen:用于加速扩散模型的后训练框架,生成速度快 53 倍在文生图领域,高分辨率输出(如 4K)正成为标配。然而,随之而来的计算成本和推理延迟问题日益凸显——以当前领先的 FLUX.1-Krea-12B 模型为例,在英伟达H100 GPU 上生成一张 4K ...图像模型# DC-Gen# 文生图模型# 英伟达6个月前03710
腾讯混元发布 HunyuanImage-3.0:800亿参数开源原生多模态模型,实现“语义理解-图像生成”的深度融合腾讯混元项目组正式发布并开源HunyuanImage-3.0——当前开源社区规模最大、性能最强的文生图模型。该模型总参数量突破800亿,推理时每token仅激活130亿参数(兼顾性能与效率),基于原生...图像模型# HunyuanImage-3.0# 腾讯混元6个月前07810