阿里开源Ovis-Image:7B 参数实现高质量文本渲染的文生图模型,海报 / UI 设计秒生成Ovis-Image 是由阿里巴巴国际数字商务团队开发的 70亿参数 文本到图像(Text-to-Image)生成模型,专注于解决文生图系统中长期存在的文本模糊、拼写错误、排版失真等痛点。该模型在保持...图像模型# Ovis-Image# 文生图模型2个月前02210
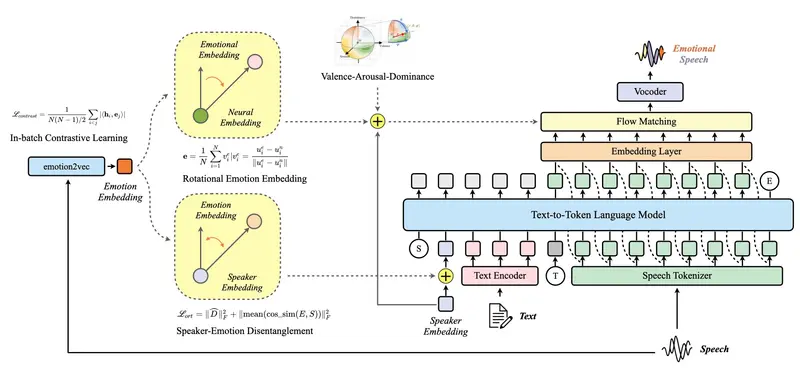
阿里开源Marco-Voice:说话人-情感独立调控,语音克隆相似度0.8275碾压同类阿里巴巴国际数字商务团队推出的开源语音合成框架 Marco-Voice,以“说话人-情感解耦”为核心创新,整合语音克隆、情感可控合成、跨语言生成三大功能,构建了统一且高效的文本转语音系统。该框架通过批...语音模型# Marco-Voice# TTS2个月前0330
DeepSeek V3.2正式发布:推理能力追平GPT-5,首个思考+工具调用开源模型经过两个多月测试,DeepSeek 正式推出 V3.2 系列模型,包括平衡型主力版本 DeepSeek V3.2 与极致推理增强版 DeepSeek V3.2 Speciale。前者以“推理能力不逊 ...大语言模型早报# DeepSeek V3.22个月前01310
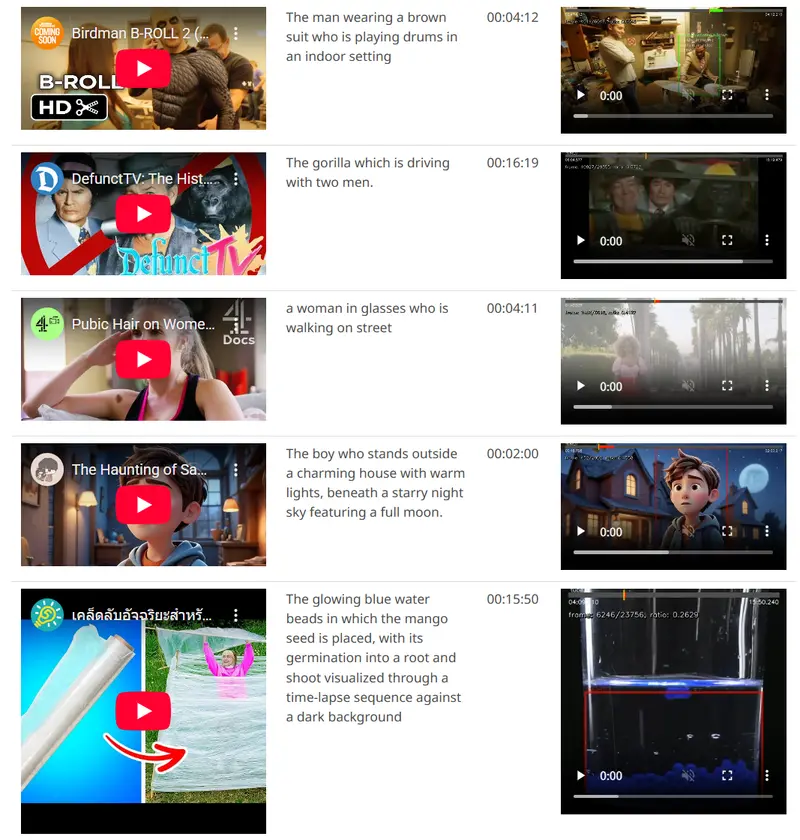
字节跳动发布Vidi2:攻克细粒度时空定位,视频检索性能领先GPT - 5字节跳动智能创作团队推出的第二代多模态视频模型Vidi2,凭借在时空定位、时间检索和视频问答三大核心能力上的突破,打破了传统视频模型在长视频理解和精细交互上的局限。该模型不仅在核心任务中实现对Gemi...多模态模型# Vidi2# 多模态视频模型# 字节跳动2个月前01180
Meta AI发布SAM 3:支持文本/图像双提示,图像视频分割性能翻Meta 近日推出 Segment Anything 系列新一代模型——SAM 3,首次实现文本、图像示例双提示驱动的开放式概念分割,可精准识别并分割“带红色条纹的雨伞”等细粒度概念,在图像与视频分割...多模态模型# Meta AI# SAM 3# 分割模型2个月前0180
Meta AI发布SAM 3D:单图生成3D模型,开源全工具链+商业落地同步推进Meta AI近日推出 Segment Anything 模型家族的全新成员——SAM 3D,这是首个具备常识级 3D 理解能力的模型,可直接将普通 2D 照片转化为细节丰富的 3D 重建结果。此次发...3D模型# Meta AI# SAM 3D2个月前0420
SteadyDancer:用 I2V 范式解决首帧失真,生成身份一致的高保真人像动画人体图像动画技术迎来颠覆性突破!南京大学、腾讯与上海AI实验室联合推出的SteadyDancer框架,通过彻底摒弃传统参考图到视频(R2V)范式,转向图像到视频(I2V)全新思路,从根源上解决了长期困...视频模型# SteadyDancer2个月前01070
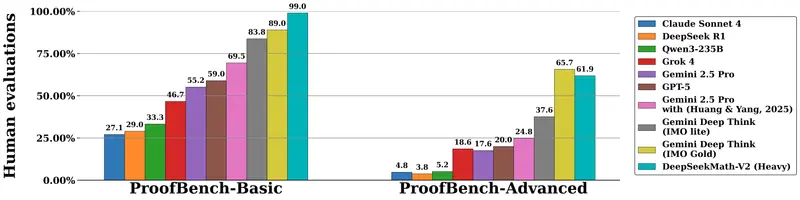
685B参数DeepSeekMath-V2开源!IMO/CMO金牌+Putnam近满分,颠覆数学推理范式数学推理领域迎来里程碑式突破!DeepSeek AI 正式发布开源数学模型 DeepSeekMath-V2,这款基于 685B 参数专家混合(MoE)架构的模型,不仅在 IMO 2025、CMO 20...大语言模型# DeepSeek# DeepSeekMath-V2# 深度求索2个月前0240
阿里通义发布Z-Image-Turbo:60 亿参数高效图像模型,支持中英双语文本渲染与亚秒级生成在图像生成模型多依赖“大参数堆料”的行业趋势下,阿里通义MAX项目组推出的Z-Image,以60亿参数的轻量化体量实现了颠覆性突破。这款通过系统性优化打造的图像生成基础模型,不仅在照片级真实感生成、中...图像模型# Z-Image-Turbo2个月前02920
腾讯开源HunyuanOCR:以1B参数覆盖9大场景,支持百种语言在OCR领域常陷入“大参数换高性能”的内卷时,腾讯混元于11月25日开源的HunyuanOCR,以1B的轻量化参数实现了颠覆性突破。这款依托混元原生多模态架构打造的端到端OCR专家模型,不仅在多项权威...多模态模型# HunyuanOCR2个月前0240
腾讯开源HunyuanVideo-1.5:83亿参数实现顶级画质,14G显存消费级显卡即可运行在视频生成模型多追求大参数堆料的当下,腾讯混元项目组推出的HunyuanVideo-1.5走出了一条“小而精”的差异化路线。这款仅搭载83亿参数的轻量级视频生成模型,不仅实现了开源领域顶尖的视觉质量与...视频模型# HunyuanVideo-1.5# 腾讯2个月前0790
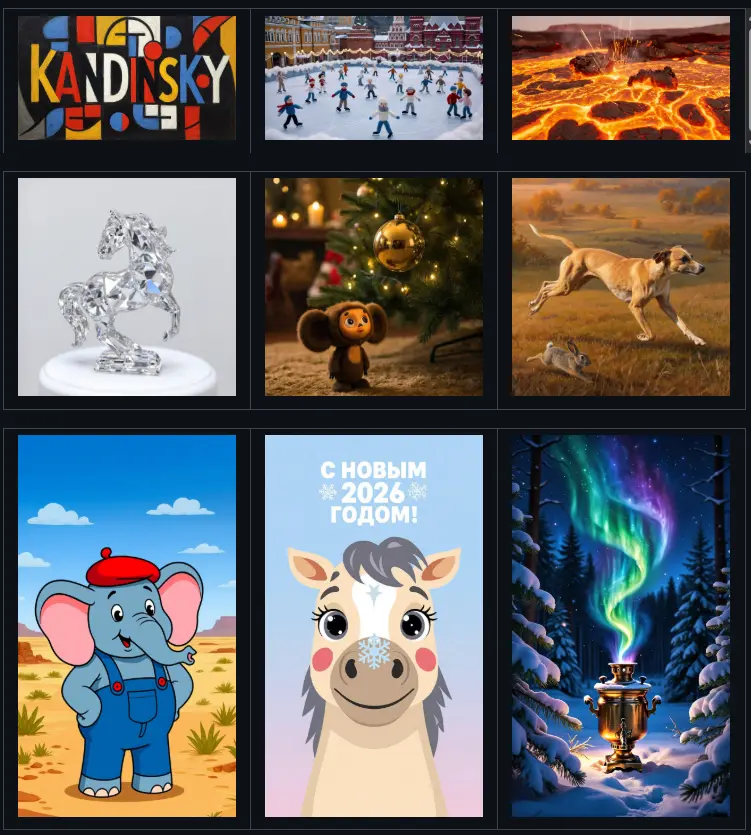
Kandinsky 5.0 全系列开源:190亿参数视频Pro+轻量版,支持中俄双语+5-10秒HD生成来自俄罗斯的AI企业Sber AI,正式推出新一代扩散模型家族 Kandinsky 5.0,以“全场景覆盖+开源开放”为核心亮点,涵盖视频生成(T2V/I2V)、图像生成(T2I)、图像编辑三大核心能...图像模型视频模型# Kandinsky 5.02个月前0910