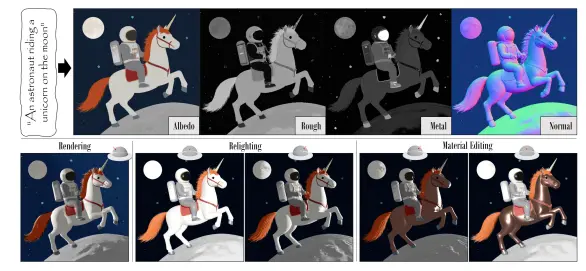
昆仑万维开源图生视频模型SkyReels-A2,基于阿里Wan2.1微调而成昆仑万维在上个月推出面向 AI 短剧创作的视频生成模型 SkyReels-V1后,又在近期开源SkyReels-A2,可以将任意视觉元素(如人物、物体、背景等)根据文本提示组装成合成视频,同时严格保持...视频模型# SkyReels-A2# Wan2.1# 昆仑万维1年前03970
新型多模态生成模型UniDisc:基于离散扩散过程的统一生成模型,能够同时理解和生成文本和图像卡内基梅隆大学的研究人员推出新型多模态生成模型 UniDisc(Unified Multimodal Discrete Diffusion),UniDisc 是一个基于离散扩散过程的统一生成模型,能够...图像模型# UniDisc# 多模态生成模型1年前04720
IntrinsiX:能够直接从文本描述生成高质量的物理基础渲染(PBR)图像传统的文生图模型(如 Stable Diffusion)能够根据文本描述生成高质量的 RGB 图像,但这些图像通常包含固定的光照效果(如反射、阴影、高光),这限制了它们在需要 PBR 地图(如游戏、V...图像模型# IntrinsiX# PBR1年前02990
自回归模型Lumina-mGPT 2.0:支持文生图、多轮图像编辑、可控生成等上海人工智能实验室和香港中文大学的研究人员之前推出了新型多模态自回归模型Lumina-mGPT,研究团队在今天推出了一种独立的、仅解码器的自回归模型Lumina-mGPT 2.0,从头开始训练,统一了...图像模型# Lumina-mGPT 2.0# 自回归模型1年前04040
Tessa-T1:专为 React 前端开发打造的推理模型在前端开发领域,React 一直是构建现代 Web 应用的核心框架之一。然而,随着项目复杂度的增加,手动编写和优化 React 组件变得越来越耗时且容易出错。为了提升开发效率并简化前端工作流程,Tes...大语言模型# Qwen2.5-Coder# Tessa-T1# 推理模型1年前02650
腾讯推出AnimeGamer:通过多模态大语言模型实现无限动漫生活模拟近年来,图像和视频合成技术的发展为生成游戏带来了新的可能性。特别是将动漫电影中的角色转化为可互动、可玩的实体,让玩家能够以自己喜爱的角色身份沉浸在动态的动漫世界中,通过语言指令进行生活模拟。这种游戏被...多模态模型# AnimeGamer# 多模态大语言模型# 无限动漫生活模拟1年前04820
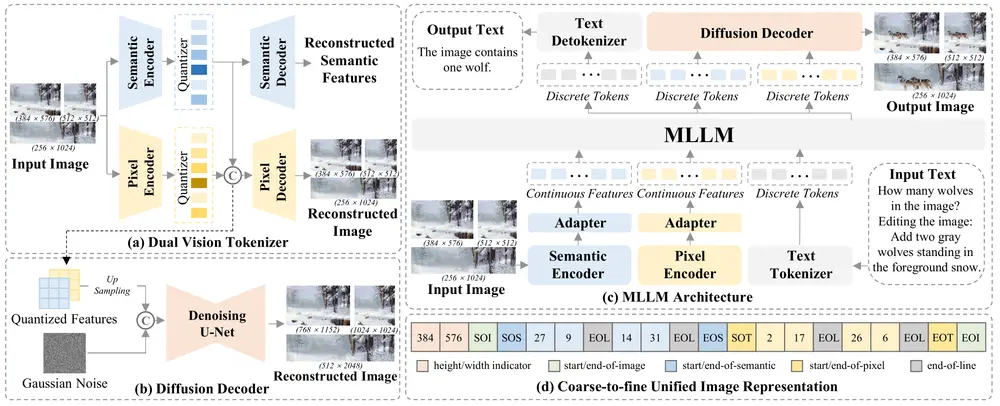
增强版多模态大语言模型ILLUME+ :通过双视觉标记化和扩散解码器来提升深度语义理解和高保真图像生成的能力近年来,多模态大语言模型(MLLMs)在图像理解、生成和编辑任务中取得了显著进展。然而,现有的统一模型在同时处理这三种任务时面临挑战。例如,早期的模型(如 Chameleon 和 EMU3)使用 VQ...多模态模型# ILLUME# 图像生成# 多模态大语言模型1年前05870
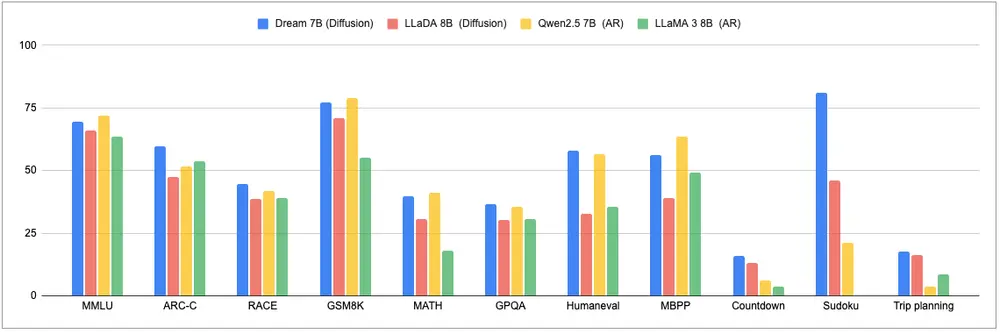
香港大学与华为合作发布扩散大语言模型 Dream 7B香港大学与华为诺亚方舟实验室携手,正式发布了迄今为止最强大的开放扩散(Diffusion)大语言模型——Dream 7B。这一模型不仅在性能上大幅超越现有的扩散语言模型,还在通用能力、数学能力和编码能...大语言模型# Dream 7B# 华为诺亚方舟实验室# 扩散大语言模型1年前06560
多语言、多任务 ASR 模型Dolphin:支持东亚、南亚、东南亚和中东地区的 40 种东方语言,同时也支持 22 种中国方言近年来,自动语音识别(ASR)技术取得了显著进展,这主要得益于模型架构的改进和大规模数据集的可用性。然而,现有的多语言 ASR 模型(如 Whisper)在处理东方语言时表现不佳,且存在可重复性问题 ...语音模型# ASR 模型# Dolphin# 语音识别1年前07590
EasyControl 框架:基于扩散变换器(DiT架构)的图像生成模型提供高效且灵活的条件控制能力Tiamat AI、上海科技大学、新加坡国立大学和Liblib AI的研究人员推出 EasyControl 框架,为基于扩散变换器(DiT架构)的图像生成模型提供高效且灵活的条件控制能力。它通过一系列...图像模型# DiT架构# EasyControl1年前03390
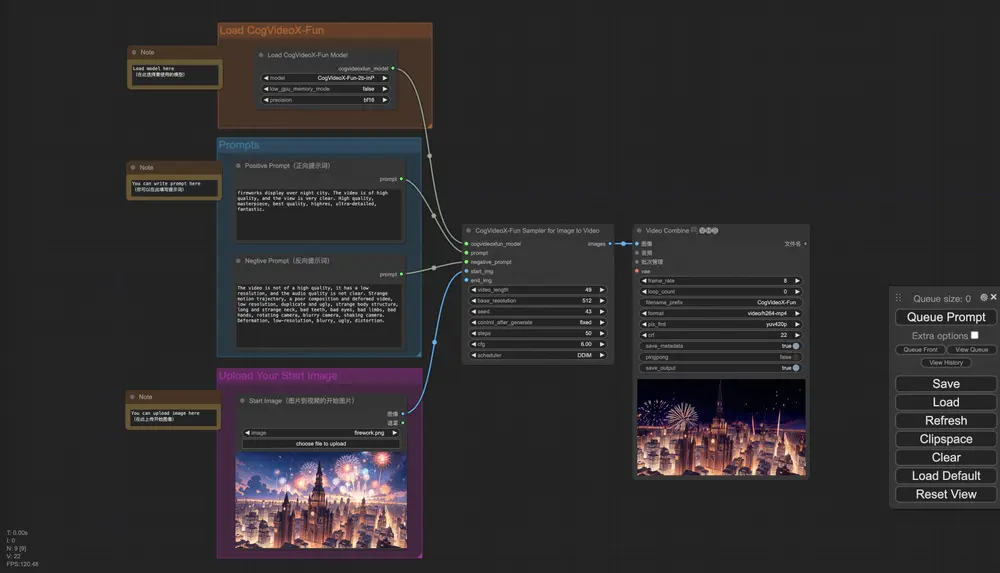
阿里旗下PAI项目组开源了视频生成模型Wan 2.1 的控制模型Wan2.1-Fun系列,支持Canny、Depth、Pose、MLSD等多种模式阿里旗下PAI项目组开源了视频生成模型Wan 2.1 的控制模型,支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制。 模型地址:https://huggingf...视频模型# Wan 2.1# Wan2.1-Fun-1.3B-Control# Wan2.1-Fun-1.3B-InP1年前03320
字节跳动与浙大联合发布轻量高效TTS模型MegaTTS3字节跳动和浙江大学的研究人员推出的一款轻量级TTS模型:MegaTTS3,0.45B,高质量语音克隆,支持中英文以及中英文混合,支持口音强度控制,后面会支持更细粒度的发音和时长调整。 GitHub:h...语音模型# MegaTTS3# TTS模型# 字节跳动1年前04870