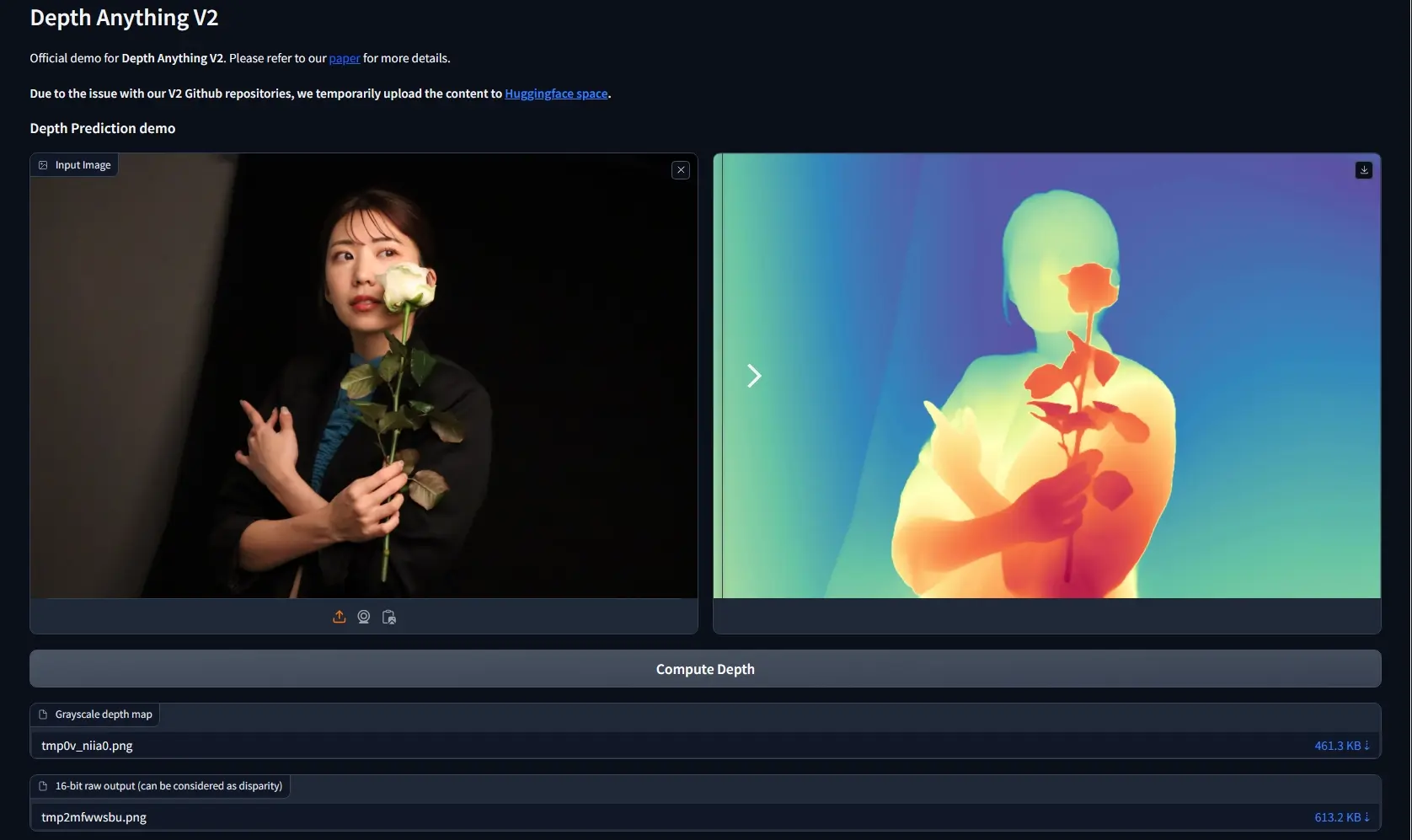
卡内基梅隆大学的研究人员推出新型多模态生成模型UniDisc(Unified Multimodal Discrete Diffusion),UniDisc 是一个基于离散扩散过程的统一生成模型,能够同时理解和生成文本和图像。它在多模态领域(如图像字幕生成、问答和图像生成)中表现出色,特别是在联合文本和图像生成任务中展现了显著的优势。
- 项目主页:https://unidisc.github.io
- GitHub:https://github.com/alexanderswerdlow/unidisc
- 模型:https://huggingface.co/aswerdlow
- Demo:https://huggingface.co/spaces/aswerdlow/unidisc_demo
例如,用户希望生成一个描述“在巴黎街头漫步的女性”的图像。用户可以提供以下输入:
- 文本描述:“一位女性在巴黎街头漫步,背景是塞纳河和奥赛博物馆。”
- 图像:一张巴黎街头的照片。
UniDisc 将这些输入转化为一个联合的文本和图像生成任务,生成一张符合描述的图像,同时生成对应的文本描述,如:“一位穿着时尚的女性在巴黎街头漫步,背景是塞纳河和奥赛博物馆。” 这种联合生成能力使得 UniDisc 在处理复杂的多模态任务时表现出色。

主要功能
- 多模态生成:能够同时生成文本和图像,适用于图像字幕生成、文本到图像生成等任务。
- 联合 inpainting:支持在文本和图像领域同时进行 inpainting(修复或填充缺失部分),即使在未明确优化此目标的情况下也能表现出色。
- 可控生成:通过分类器自由引导(Classifier-Free Guidance, CFG)技术,用户可以在生成过程中灵活调整生成内容的质量和多样性。
- 高效推理:在给定的计算预算下,UniDisc 能够生成更高质量和多样化的结果,同时保持较高的推理效率。

主要特点
- 统一的离散扩散模型:UniDisc 基于离散扩散过程,通过随机掩码(masking)的方式对数据进行噪声处理,并学习从掩码序列恢复到干净序列。
- 多模态联合建模:UniDisc 能够同时处理文本和图像,使用统一的词汇表和自注意力机制,实现文本和图像的联合生成。
- 高效训练和推理:尽管离散扩散模型在训练效率上略低于自回归(AR)模型,但 UniDisc 在推理阶段表现出更高的效率和更好的质量控制。
- 灵活的生成策略:UniDisc 支持多种采样策略,如置信度采样(confidence-based sampling)和随机采样(random sampling),用户可以根据需求选择合适的策略。
工作原理
UniDisc 的工作原理基于离散扩散模型的核心思想。它通过以下步骤实现多模态生成:
- 数据预处理:将文本和图像分别通过各自的 tokenizer 转换为离散的 token 序列。
- 噪声注入:使用吸收型掩码(absorbing mask)对 token 序列进行随机掩码,模拟噪声数据。
- 联合建模:通过一个双向解码器(decoder-only transformer)学习从掩码序列恢复到干净序列,同时处理文本和图像 token。
- 生成过程:在推理阶段,从一组掩码 token 开始,逐步解码,通过多次迭代的去噪过程生成最终的文本和图像。
- 分类器自由引导(CFG):在生成过程中,通过 CFG 技术调整生成内容的质量和多样性,实现更灵活的控制。
应用场景
- 图像字幕生成:根据输入的图像生成详细的文本描述,适用于图像标注和内容理解。
- 文本到图像生成:根据文本描述生成对应的图像,可用于创意设计、广告制作等领域。
- 视频生成:通过生成一系列图像和对应的文本描述,可以用于视频内容的生成。
- 多模态问答:结合图像和文本信息,生成更准确的问答内容,适用于智能客服和教育领域。
- 图像修复和编辑:通过联合 inpainting 能力,修复图像中的缺失部分或编辑图像内容。
UniDisc 通过其强大的多模态生成能力和高效的推理机制,为多模态任务提供了一个灵活且高效的解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...