AccVideo:通过知识蒸馏技术,将HunyuanVideo模型生成速度提高了 8.5 倍,同时保持生成质量视频扩散模型是一种强大的生成模型,能够生成高质量的视频内容。然而,传统的视频扩散模型在生成视频时需要大量的迭代去噪步骤,这使得生成过程非常缓慢且计算成本高昂。例如,HunyuanVideo 模型在单个...视频模型# AccVideo# HunyuanVideo# 知识蒸馏1年前05330
基于 GenAI 的视觉内容创作控制框架ZenCtrl:利用单张主体图像生成多视角、多样化场景的高分辨率图像,无需额外微调ZenCtrl 是一款基于 GenAI 的视觉内容创作控制框架,专注于利用单张主体图像生成多视角、多样化场景的高分辨率图像,无需额外微调。它通过精细的控制能力和模块化设计,为创作者提供了一个强大且灵活...图像模型# OminiControl# ZenCtrl# 图像控制框架11个月前05550
阿里巴巴发布 QVQ-Max:能看、能理解、能思考的视觉推理模型阿里巴巴推出一款名为 QVQ-Max 的全新视觉推理模型,这是其 Qwen模型系列中的最新成员。QVQ-Max 的独特之处在于它能够理解照片和视频的内容,并对这些信息进行分析和推理,从而提供解决方案...多模态模型# QVQ-Max# 视觉推理模型# 阿里巴巴1年前02840
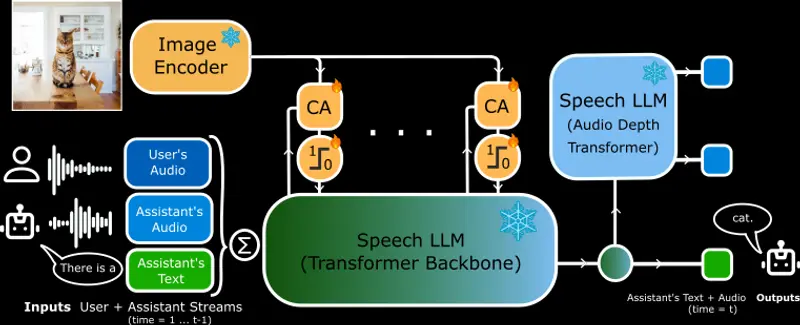
Kyutai发布首个开源实时语音模型MoshiVis,开启视觉与语音交互新时代在AI领域,将实时语音交互与视觉内容相结合一直是一个极具挑战性的课题。传统系统通常依赖于多个独立组件来实现语音活动检测、语音识别、文本对话和文本转语音合成,这种分段式的方法不仅容易引入延迟,还难以捕捉...语音模型# MoshiVis# 语音模型1年前02090
Ideogram 3.0发布:更真实、更创意、更一致的生成式设计体验Ideogram在今天正式发布了其最新模型Ideogram 3.0,这款最新的AI生成模型不仅在图像质量和文本渲染方面取得了重大突破,还通过强大的风格控制功能和高效的设计能力,为创作者和专业人士提供了...图像模型# AI绘画# Ideogram# Ideogram 3.01年前05970
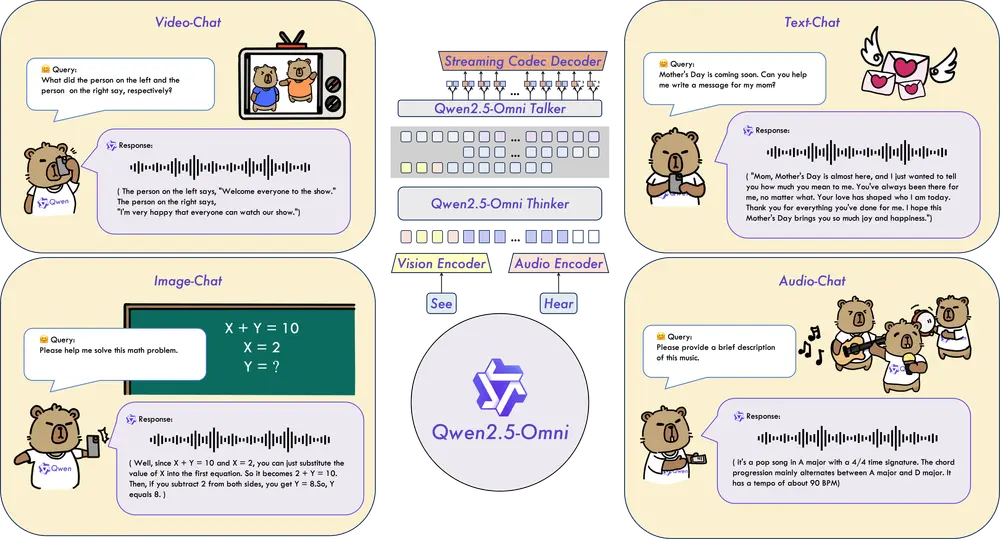
阿里通义实验室发布新一代端到端多模态旗舰模型Qwen2.5-Omni阿里通义实验室发布了 Qwen2.5-Omni,这是 Qwen 模型家族中的新一代端到端多模态旗舰模型。Qwen2.5-Omni 专为全方位多模态感知设计,能够无缝处理文本、图像、音频和视频等多种输入...多模态模型# Qwen2.5-Omni# 多模态模型1年前02670
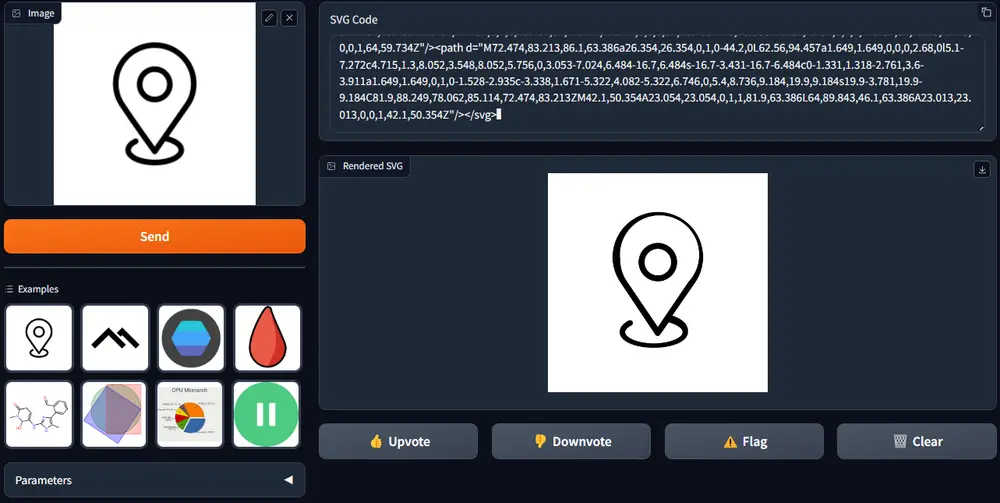
StarVector:利用多模态大语言模型(MLLM)从图像和文本生成SVG代码ServiceNow Research、魁北克人工智能研究所、加拿大 CIFAR 人工智能主席、不列颠哥伦比亚大学、高等工程技术学院和苹果的研究人员推出StarVector,利用多模态大语言模型(ML...图像模型# StarVector# SVG代码# 多模态大语言模型1年前04870
谷歌发布了新推理模型Gemini 2.5系列:其特色在于回答问题前会进行“思考”过程本周二(2025年3月25日),谷歌发布了新推理模型Gemini 2.5系列,其特色在于回答问题前会进行“思考”过程。为了启动这一系列,谷歌推出了Gemini 2.5 Pro Experimental...大语言模型# Gemini 2.5# 思考模型# 推理模型1年前01980
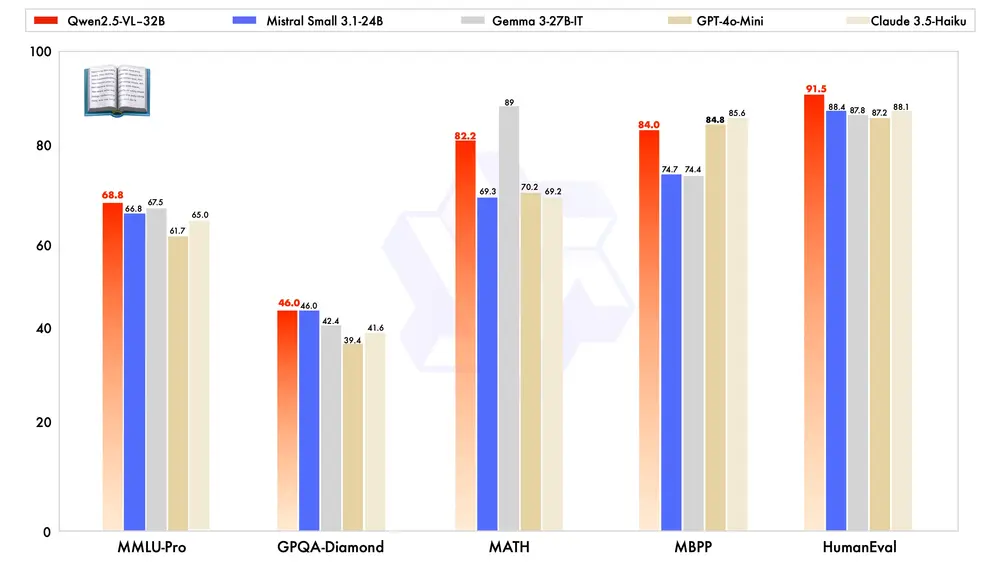
阿里通义实验室开源32B参数的多模态模型 Qwen2.5-VL-32B-Instruct今年一月底,阿里通义实验室推出了 Qwen2.5-VL 系列模型,凭借其卓越的性能和广泛的应用潜力,迅速获得了社区的广泛关注和积极反馈。在此基础上,团队通过强化学习持续优化模型,并于近期开源了备受期待...多模态模型# Qwen2.5-VL-32B-Instruct# 多模态模型# 阿里通义实验室1年前03300
阿里巴巴推出全身虚拟形象解决方案TaoAvatar:在AR设备上实时运行一个会说话的全身虚拟人阿里巴巴的研究人员推出一种名为 TaoAvatar 的技术,用于创建逼真的、全身的、会说话的虚拟形象(avatar),并能够在增强现实(AR)设备上实时运行。TaoAvatar 基于 3D 高斯点绘制...3D模型# TaoAvatar# 虚拟形象# 阿里巴巴1年前02630
个性化图像生成和编辑方法SISO:适合在只有单张主题图像的情况下使用巴伊兰大学和英伟达的研究人员推出一种无需训练的方法SISO,用于从单张主题图像进行个性化图像生成和编辑。SISO 是一种无需训练的方法,通过优化与输入主题图像的相似度分数来实现图像的个性化生成和编辑...图像模型# SISO# 图像生成# 图像编辑1年前02080
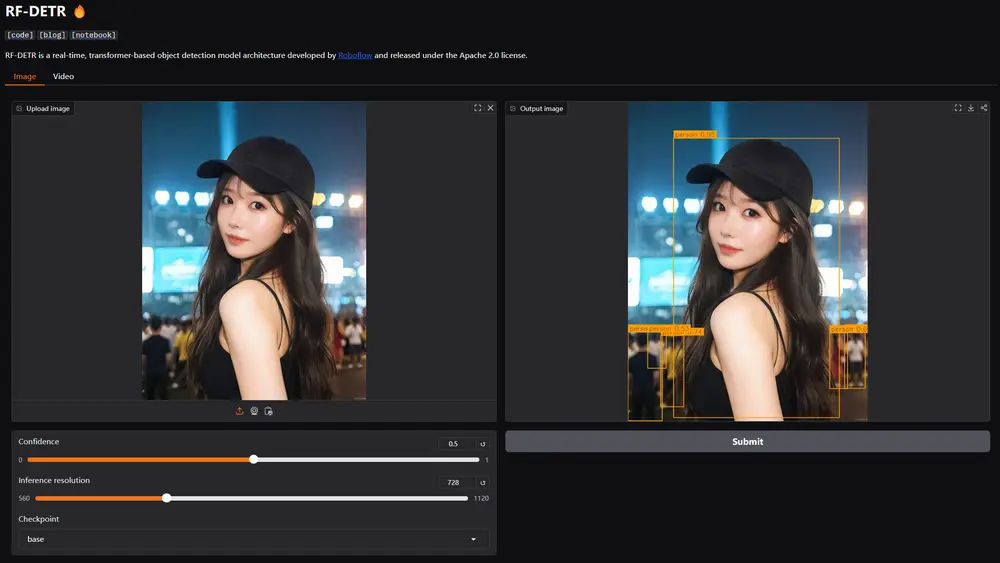
Roboflow开源基于Transformer的实时目标检测模型 RF-DETRRoboflow 近日正式发布了 RF-DETR,一种基于Transformer的实时目标检测模型。RF-DETR 在多个现实世界数据集上的表现超越了所有现有的目标检测模型,并且是首个在 COCO 数...多模态模型# RF-DETR# Roboflow# 实时目标检测模型1年前02710