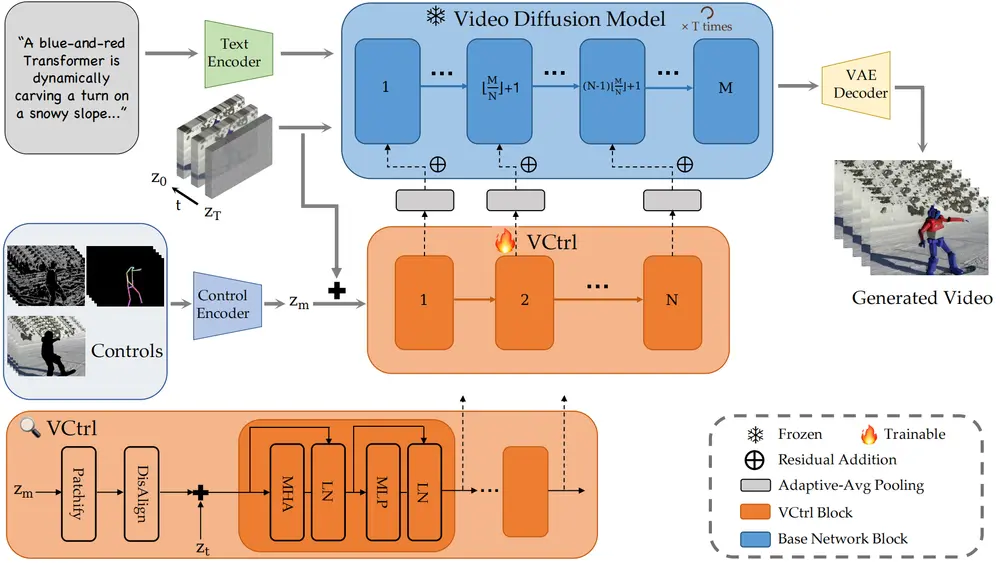
通用视频生成控制模型PP-VCtrl:引入辅助条件编码器,能够灵活对接各类控制模块在数字创意蓬勃发展的当下,视频生成技术已成为内容创作的核心驱动力之一。然而,尽管文本到视频的扩散模型取得了显著进展,但在精确控制生成内容的时空特征方面仍存在诸多挑战。广告创意、影视后期制作、直播带货...视频模型# PP-VCtrl# 视频生成控制模型1年前05830
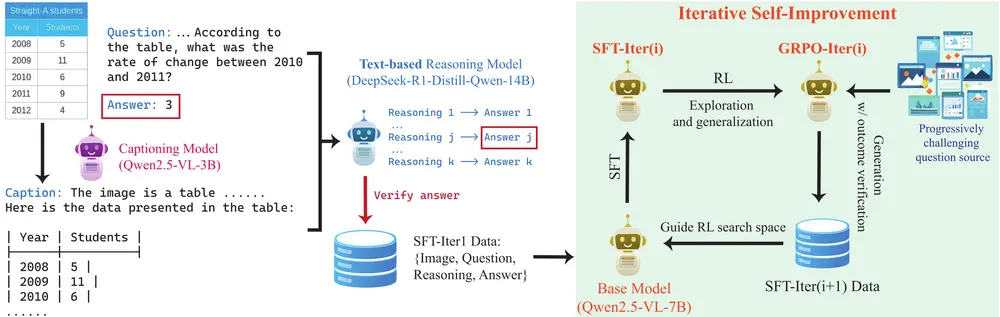
OpenVLThinker:通过迭代自我改进的方法,将复杂的推理能力(如自我验证和自我修正)整合到大型视觉语言模型中加州大学洛杉矶分校的研究人员推出OpenVLThinker,通过迭代自我改进的方法,将复杂的推理能力(如自我验证和自我修正)整合到大型视觉语言模型(LVLMs)中,并评估其在多模态推理任务中的表现。 ...多模态模型# OpenVLThinker# 多模态推理模型1年前03750
腾讯混元项目组推出高效课程强化学习方法FASTCURL:通过逐步扩展上下文窗口的策略,加速了类似 R1 的推理模型的强化学习训练效率,并提升其在复杂推理任务中的性能腾讯混元项目组推出提出了一种名为 FASTCURL 的高效课程强化学习方法,通过逐步扩展上下文窗口的策略,加速了类似 R1 的推理模型的强化学习训练效率,并提升了其在复杂推理任务中的性能。 它们还发布...大语言模型# FASTCURL# FastCuRL-1.5B-Preview# 混元1年前03920
URAE:基于 Flux的超高分辨率图像生成的高效解决方案在图像生成领域,高分辨率图像的生成一直是一个极具挑战性的问题,尤其是在训练数据和计算资源有限的情况下。新加坡国立大学的研究人员推出了一种名为 URAE(Ultra-Resolution Adaptat...图像模型# FLUX# URAE1年前04140
Yandex Research推出分层蒸馏框架SWD:加速扩散模型(如FLUX和SD3.5)的生成过程Yandex Research 推出了一种名为 “Scale-wise Distillation of Diffusion Models (SWD)” 的新型框架,通过分层采样策略加速扩散模型(DMs...图像模型# FLUX# SD3.5# SWD1年前06180
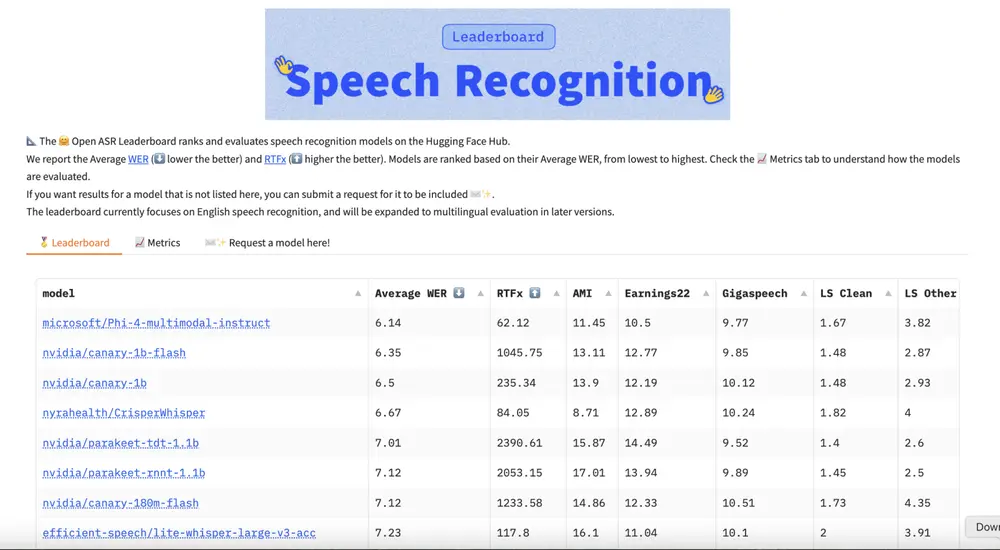
英伟达开源多语言语音识别和翻译模型:Canary 1B Flash 和 Canary 180M Flash在促进全球交流的进程中,多语言语音识别和翻译技术扮演着至关重要的角色。然而,开发能够实时准确地转录和翻译多种语言的模型面临着诸如处理语言细微差别、确保高准确性与低延迟以及实现跨设备高效部署等挑战。为应...语音模型# Canary 180M Flash# Canary 1B Flash# 多语言语音识别1年前04740
腾讯推出混元自研深度思考模型 T1 正式版:吐字快、能秒回,擅长超长文处理腾讯正式推出了其自主研发的深度思考模型——混元 T1 正式版。这款模型以其快速响应、擅长处理超长文本及强大的推理能力而著称,标志着腾讯在AI领域的又一重要进展。 项目主页:https://tencen...大语言模型# 混元 T1# 腾讯1年前03040
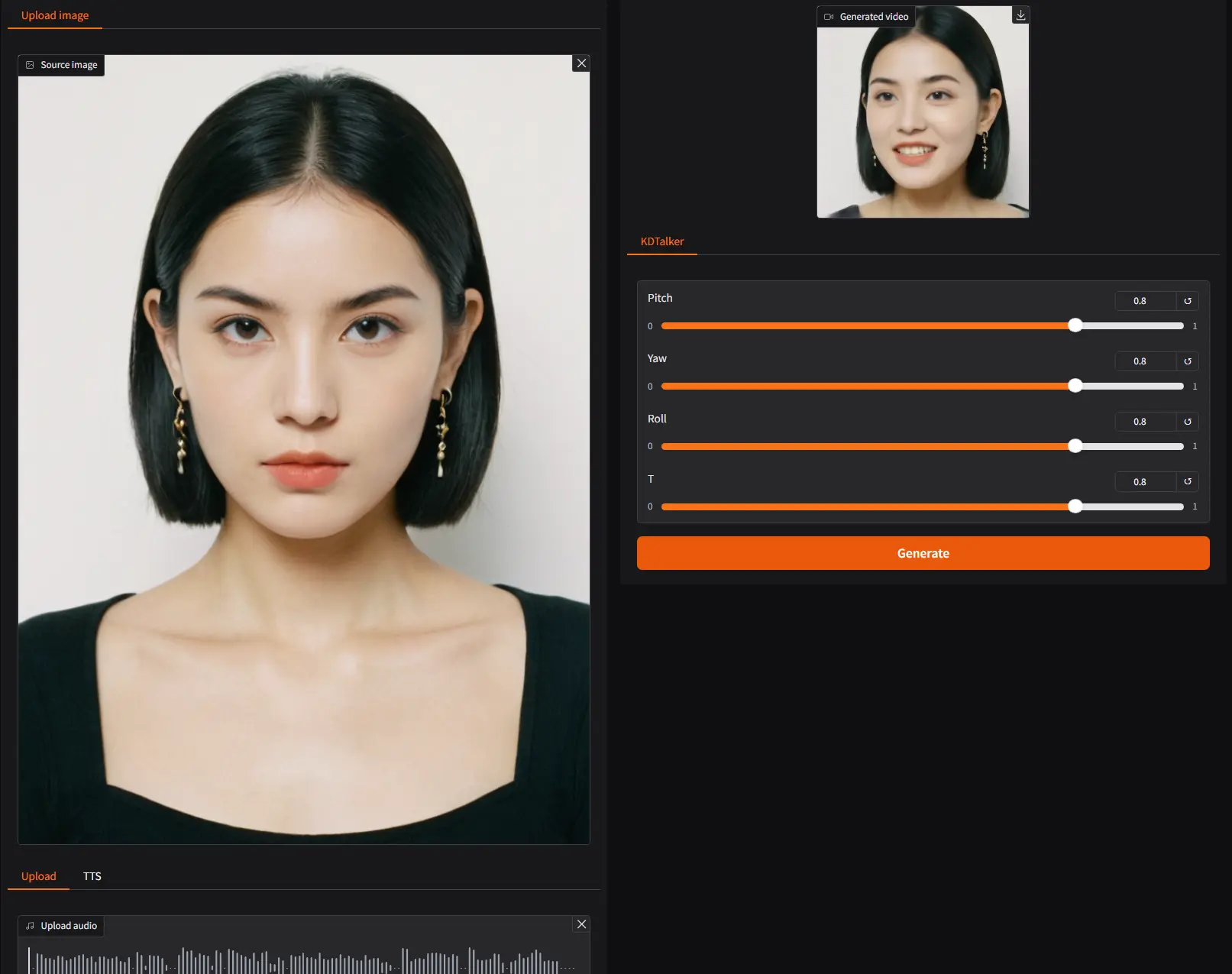
用于生成自然动态“说话肖像”视频的新型框架KDTalker利物浦大学、蚂蚁集团、西交利物浦大学、昆山杜克大学和理光软件研究中心推出新型框架 KDTalker,用于从单张图像和音频生成自然且动态的“说话肖像”(talking portrait)视频。该框架结合...视频模型1年前02920
用于从单张图像生成灵活视角 3D 场景的框架FlexWorld:从单张图像生成具有灵活视角(如 360° 旋转和缩放)的高质量 3D 场景中国人民大学、北京市大数据重点实验室、清华大学、北京师范大学和字节跳动的研究人员推出一种用于从单张图像生成灵活视角 3D 场景的框架FlexWorld,从单张图像生成具有灵活视角(如 360° 旋转和...视频模型# 3D 场景# FlexWorld1年前04790
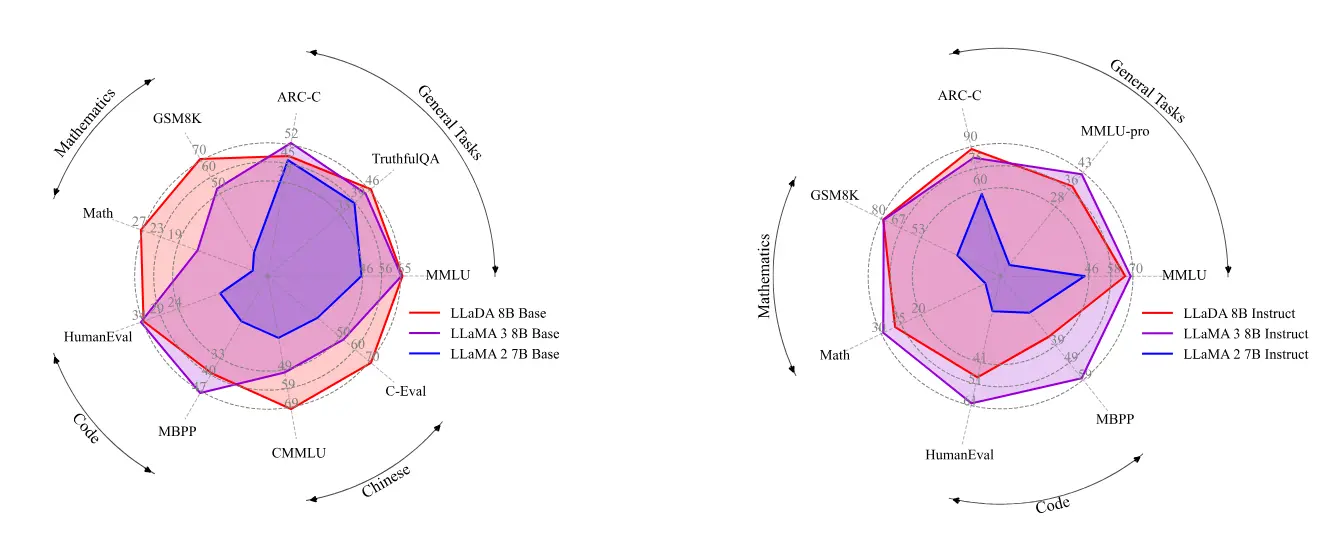
基于扩散模型的大语言模型LLaDA:通过一个前向掩码过程和一个反向过程来建模,能够同时优化双向依赖关系,并通过似然下界优化来生成文本中国人民大学和蚂蚁集团的研究人员推出新型大语言模型LLaDA,基于扩散模型(Diffusion Model)从头开始训练,挑战了自回归模型(ARM)在大型语言模型中的主导地位。与传统的从左到右的生成方...大语言模型# LLaDA# 大语言模型# 扩散模型1年前04240
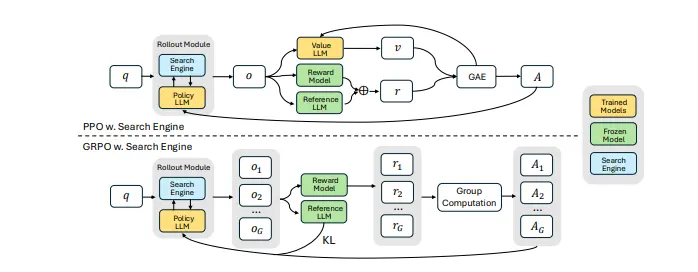
SEARCH-R1:通过强化学习让 LLM 在逐步推理过程中自主生成多个搜索查询,并实时检索信息伊利诺伊大学厄巴纳-香槟分校计算机科学系和马萨诸塞大学安姆赫斯特分校智能信息检索中心的研究人员推出新型框架SEARCH-R1 ,通过强化学习( RL)训练大语言模型,使其能够在推理过程中自主生成搜索查...大语言模型# DeepSeek-R1# SEARCH-R11年前03400
新型图像编辑框架PhotoDoodle:通过文字提示在照片中添加艺术化装饰新加坡国立大学、上海交通大学、北京邮电大学、字节跳动和Tiamat的研究人员推出新型图像编辑框架PhotoDoodle,通过少量样本学习艺术家的独特风格,将装饰元素(如手绘线条、装饰图案等)无缝叠加到...图像模型# PhotoDoodle# 图像编辑框架# 照片涂鸦1年前02980