微软推出Phi-4系列推理模型:Phi-4-reasoning、Phi-4-reasoning-plus和Phi-4-mini-reasoning一年前,微软推出了Phi-3,开启了小型语言模型(SLM)的新篇章。这些模型以其高效性和灵活性迅速吸引了广泛关注。如今,在 Phi 系列发布一周年之际,微软再次突破技术边界,推出了三款全新推理模型:P...大语言模型# Phi-4-mini-reasoning# Phi-4-reasoning# Phi-4-reasoning-plus12个月前02250
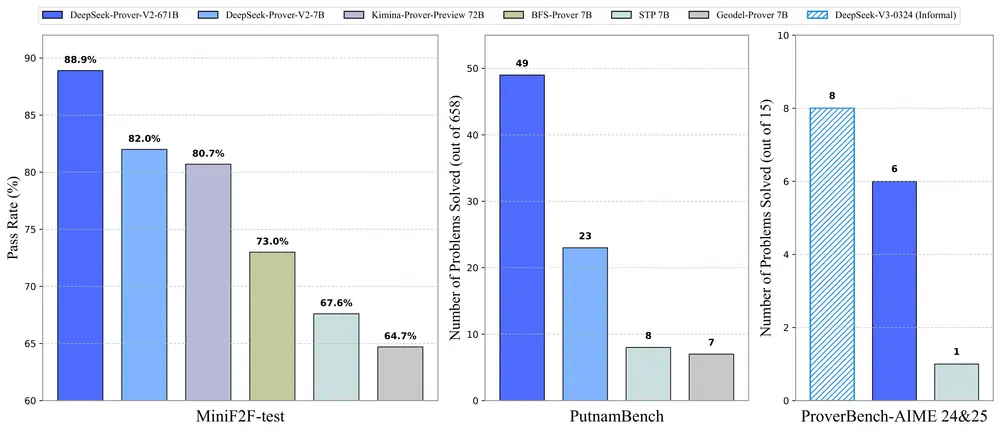
DeepSeek 推出 DeepSeek-Prover-V2:为 Lean 4 形式化定理证明设计的开源大语言模型DeepSeek于4月30日发布了 DeepSeek-Prover-V2,这是一个专门用于 Lean 4 形式化定理证明的开源大语言模型。该模型的设计目标是将非形式化的数学推理与形式化的证明构建整合到...大语言模型# DeepSeek# DeepSeek-Prover-V2# DeepSeek-Prover-V2-671B12个月前02630
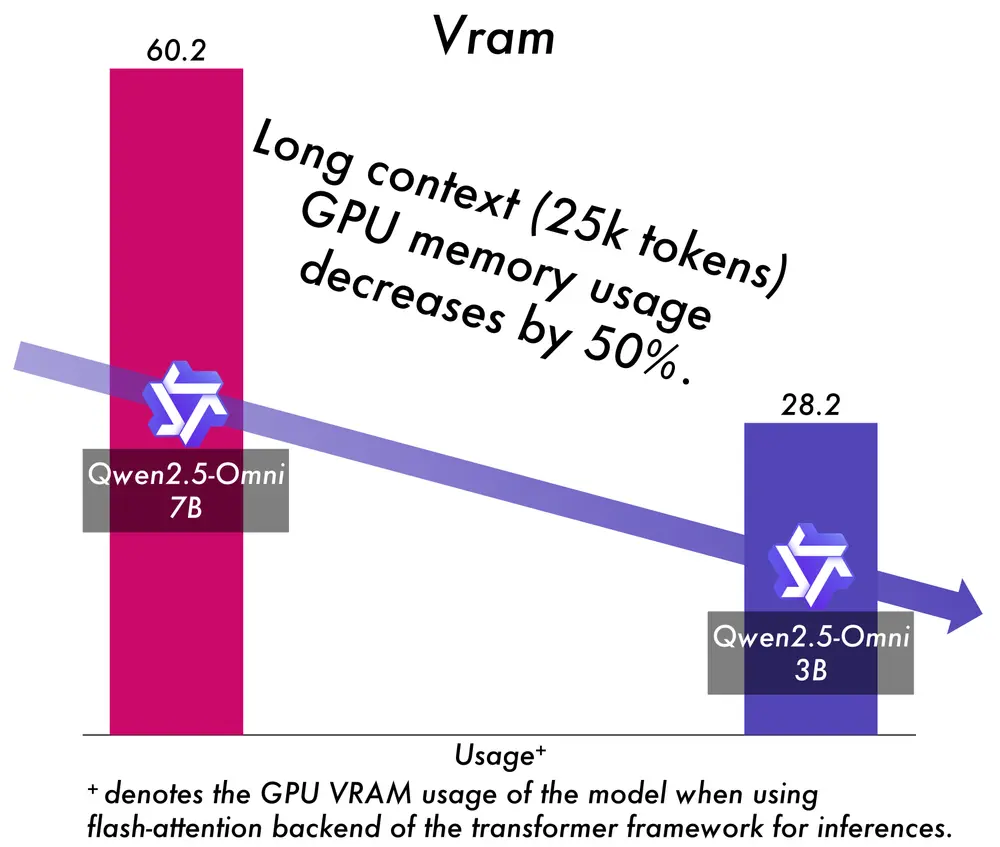
阿里Qwen团队发布端到端多模态模型Qwen2.5-Omni-3B阿里Qwen团队在发布Qwen3系列模型后,又推出Qwen2.5-Omni系列的一个新模型Qwen2.5-Omni-3B,这是一个端到端多模态模型,能够无缝处理文本、图像、音频和视频等多种输入形式,并...多模态模型# Qwen# Qwen2.5-Omni-3B# 阿里巴巴12个月前04790
JetBrains推出其首个用于编码的开源模型Mellum,主要功能为代码补全软件开发公司JetBrains,以提供一系列流行应用程序开发工具而闻名,它们在今天发布了其首个用于编码的开源模型——Mellum。这款模型于周三在Hugging Face平台上公开,通过高度专业化的代...大语言模型# JetBrains# 代码模型# 代码补全12个月前02050
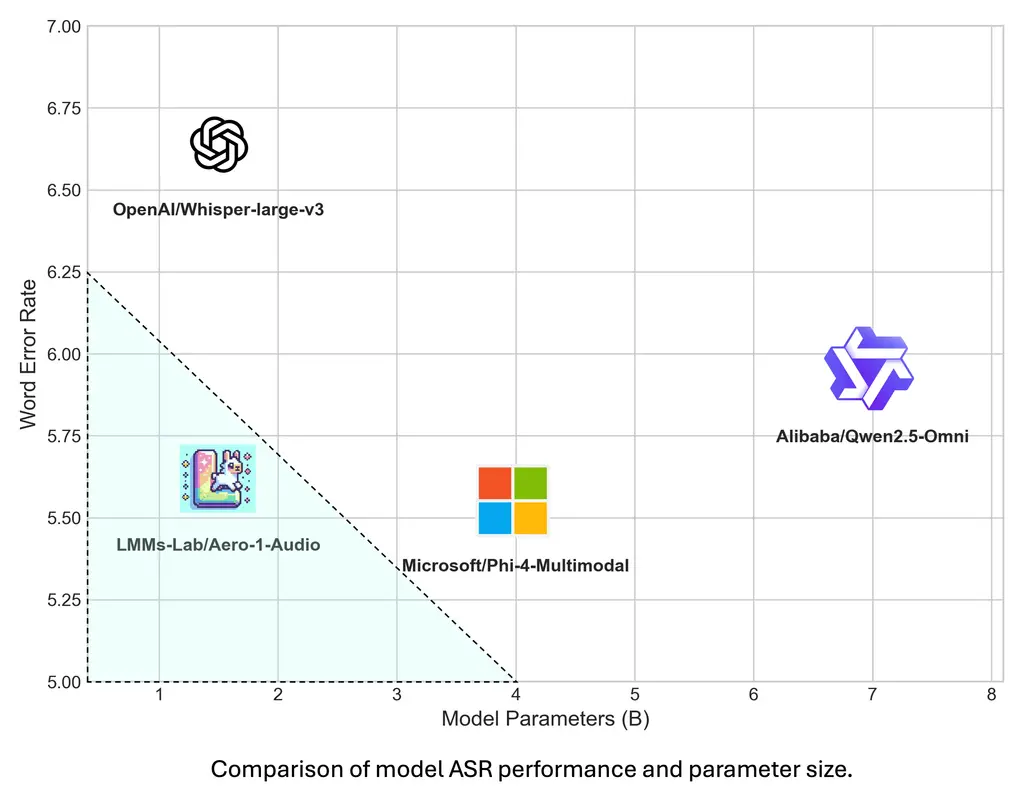
LMMs-Lab发布轻量高效音频模型Aero-1-Audio:擅长长语音ASR与多模态任务LMMs-Lab 推出了一款紧凑型音频模型 Aero-1-Audio,专为多种音频任务设计,包括语音识别(ASR)、音频理解和音频指令跟随。作为 Aero-1 系列的第一代产品,Aero-1-Audi...语音模型# Aero-1-Audio# LMMs-Lab# 语音识别12个月前06750
Freepik 推出基于商业授权图像训练的 AI 图像生成模型 F Lite在线图形设计平台 Freepik 于周二宣布推出一款新的开源图像生成模型——F Lite。这款模型完全基于商业授权的、“适合工作场所(SFW)”的图像进行训练,为用户提供安全、合法且高质量的图像生成服...图像模型# F Lite# Freepik# 图像生成模型12个月前02400
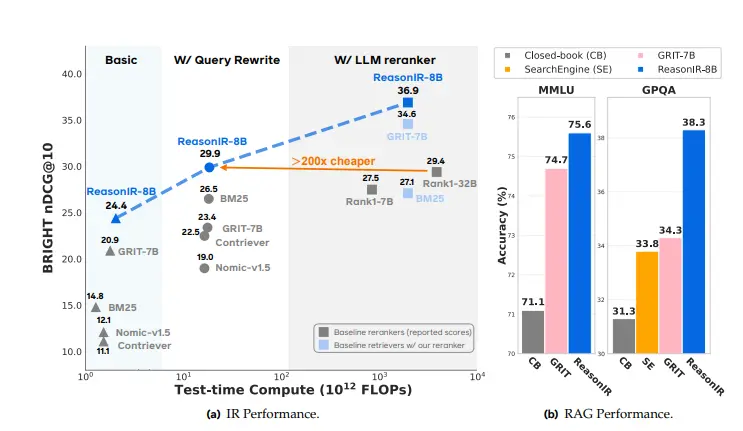
新型检索器ReasonIR-8B:专门针对需要推理的复杂任务进行优化Meta、华盛顿大学、新加坡国立大学、艾伦人工智能研究所、斯坦福大学、麻省理工学院和加州大学伯克利分校的研究人员推出一种名为 ReasonIR-8B 的新型检索器,专门针对需要推理的复杂任务进行优化...大语言模型# ReasonIR-8B# 检索器12个月前02600
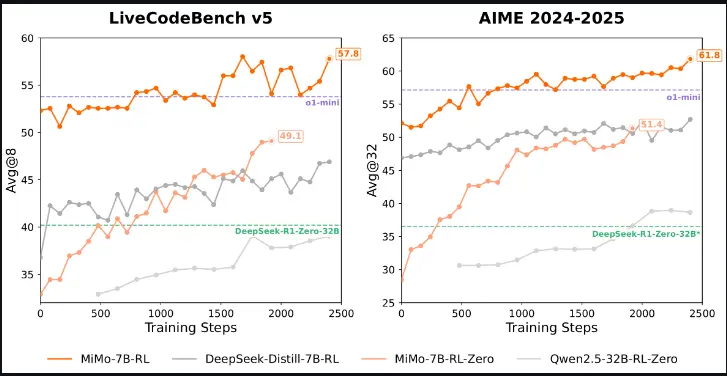
小米团队发布 MiMo-7B系列模型:专为推理任务从头开始训练的模型在强化学习(RL)领域,大型基础模型一直是研究的主流方向。目前,许多成功的强化学习项目,尤其是那些专注于代码推理能力的项目,都依赖于庞大的模型,例如拥有 320 亿参数的模型。然而,要在小型模型中同时...大语言模型# MiMo-7B# 小米12个月前02660
阿里推出 Qwen3 系列大模型:开源 8 款模型,性能飞跃,多语言支持,推理能力显著提升阿里 QWEN 团队在今天推出 Qwen3,这是 Qwen 系列大言模型的最新力作。Qwen3 以其卓越的性能和广泛的应用潜力,正在成为开源AI领域的新焦点。 性能突破:超越行业标杆 Qwen3 的旗...大语言模型# QWEN 团队# 阿里巴巴12个月前06040
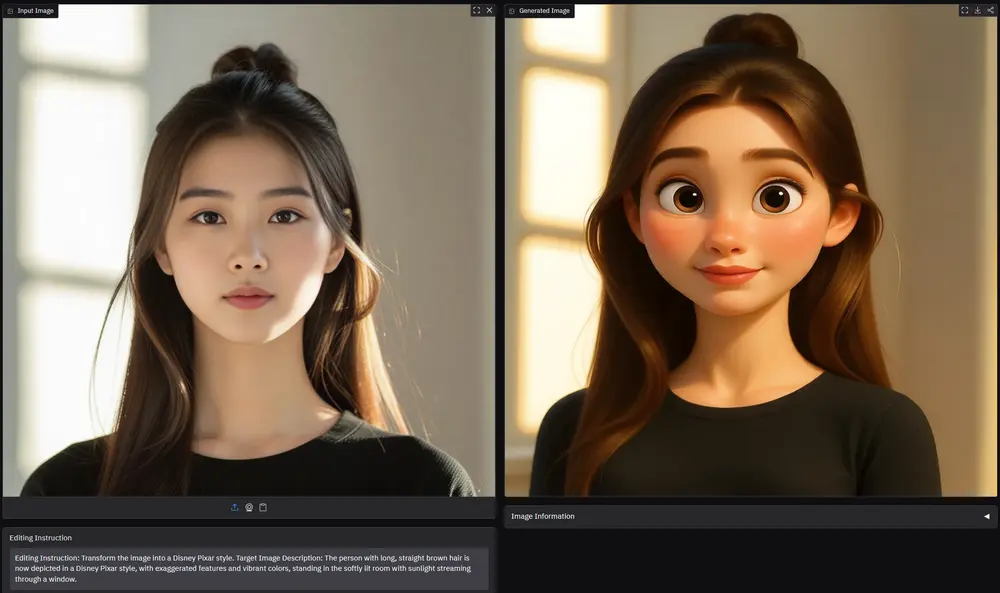
智象未来推出基于 HiDream-I1 的强大图像编辑模型HiDream-E1北京智象未来科技在开源了图像生成基础模型HiDream-I1后,又在今天推出专注于图像编辑的专用模型HiDream-E1,这是一款专为图像编辑任务设计的先进模型,建立在 HiDream-I1 的核心功...图像模型# HiDream-E1# HiDream-I1# 图像编辑模型12个月前04560
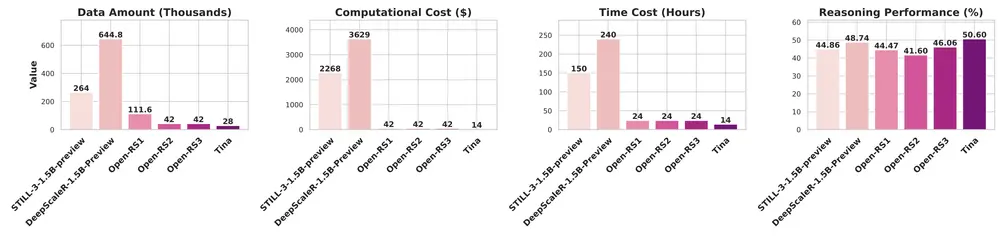
南加州大学推出一系列紧凑型推理模型Tina:利用LoRA技术实现低成本强化学习在语言模型(LLM)领域,尽管通用任务性能取得了显著进展,但实现强大的多步推理能力仍然是一个重大挑战。这种能力对于复杂问题解决场景(如科学研究和战略规划)至关重要。然而,传统方法如监督微调(SFT)虽...大语言模型# Tina# v# 推理模型12个月前03940
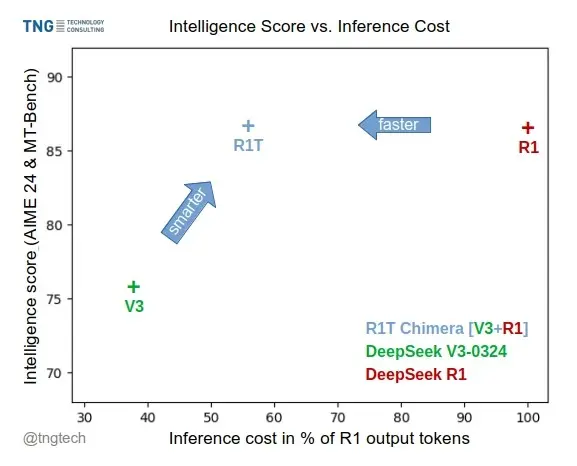
DeepSeek-R1T-Chimera:结合推理能力与高效输出的开放权重模型TNG科技发布了 DeepSeek-R1T-Chimera,这是一个通过创新方法构建的开放权重模型。它将 DeepSeek-R1 的强大推理能力与 DeepSeek-V3 (0324) 的高效 tok...大语言模型# DeepSeek-R1# DeepSeek-R1T-Chimera# DeepSeek-V3-032412个月前04930