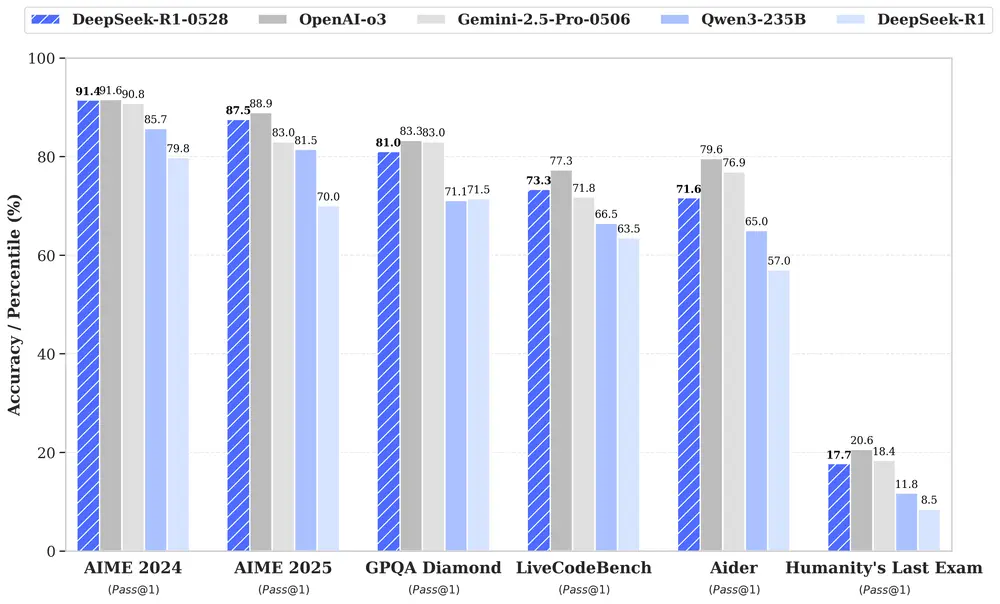
DeepSeek R1 升级:推理能力逼近顶尖模型,小模型也迎来突破DeepSeek 最新发布了其旗舰模型 DeepSeek R1 的升级版本 —— DeepSeek-R1-0528。这次更新不仅在推理深度上有了显著提升,还在幻觉控制、函数调用支持和代码生成体验等方面...大语言模型# DeepSeek-R111个月前04410
DeepSeek推出基于Qwen3-8B的小型推理模型:DeepSeek-R1-0528-Qwen3-8B深度求索在本周对DeepSeek R1进行了升级,还开源了此版本模型DeepSeek-R1-0528,官方还推出了一个基于Qwen3-8B的小型推理模型:DeepSeek-R1-0528-Qwen3...大语言模型# DeepSeek# DeepSeek-R1-0528-Qwen3-8B# 深度求索11个月前02740
Black Forest Labs 推出新一代上下文感知图像生成模型FLUX.1 Kontext,支持图像生成及编辑继 FLUX.1 系列大获成功后,Black Forest Labs(黑森林实验室) 在今天正式发布其最新力作 —— FLUX.1 Kontext。 这是一套全新的上下文流匹配生成模型(Context...图像模型# Black Forest Labs# FLUX.1 Kontext# 黑森林实验室11个月前07670
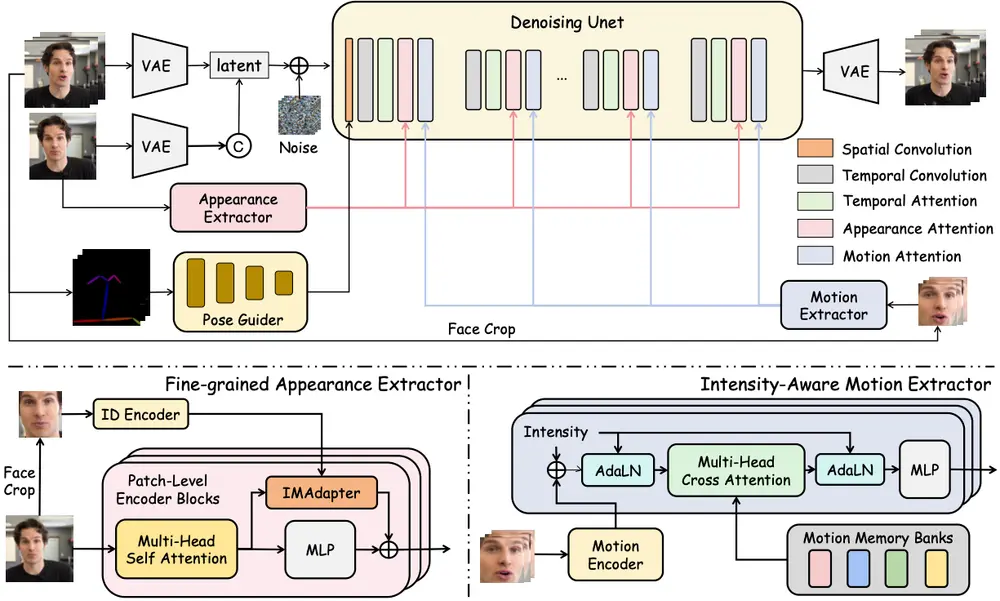
腾讯混元项目组推出数字人头像生成模型 HunyuanPortrait :用于高度可控且逼真的肖像动画生成腾讯混元项目组推出基于扩散模型的条件控制方法 HunyuanPortrait ,用于高度可控且逼真的肖像动画生成。该方法通过隐式表示来控制肖像动画,能够利用单张肖像图像作为外观参考和视频片段作为驱动模...视频模型# HunyuanPortrait# 腾讯混元11个月前01960
Resemble AI推出首个情感可控的开源TTS模型ChatterboxResemble AI正式发布了其首个生产级开源TTS模型——Chatterbox。这是目前市面上少有的、具备高质量语音合成能力并支持情感控制的开源项目。目前仅支持英文。 GitHub:https...语音模型# Chatterbox# Resemble AI# TTS模型7个月前04000
OmniConsistency:解决图像风格化中“一致性”难题的通用插件,提升了图像风格化的一致性与美学质量在图像风格化领域,扩散模型已经取得了显著进展。然而,两个核心问题始终困扰着研究者与开发者: 如何在复杂场景下保持一致的风格化效果? 尤其是在身份、构图和细节上的保留。 如何防止图像到图像(I2I)流水...图像模型# OmniConsistency# 图像风格化11个月前04470
腾讯混元推出HunyuanVideo-Avatar:音频驱动、情感可控、支持多角色的虚拟人视频生成模型近年来,音频驱动人物动画(Audio-driven Avatar Animation)取得了显著进展,但仍有几个关键挑战尚未完全解决: 如何在保持角色一致性的前提下生成高度动态的视频; 实现角色与音频...视频模型# HunyuanVideo-Avatar# 腾讯混元# 视频生成模型11个月前04270
别让好模型消失,这个 WAN2.1 LoRA 合集值得收藏”近日,CivitAI 在 Visa 和 Mastercard 的压力下进一步收紧内容政策,导致平台上大量 模型被删除。这些模型中包含了许多创作者精心训练的作品,尤其是 NSFW类内容。 地址:http...视频模型# WAN2.1 LoRA11个月前01,1480
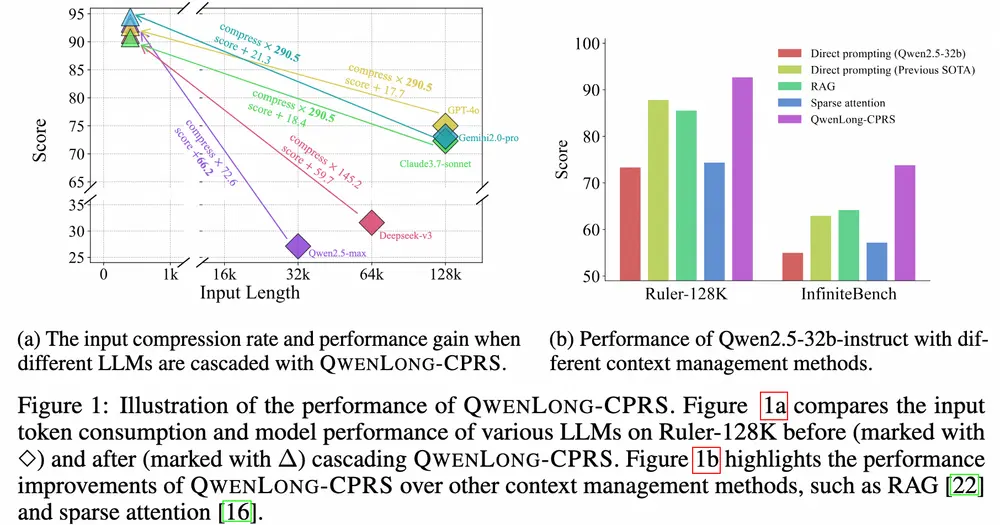
阿里推出高效的长上下文压缩框架QwenLong-CPRS在大语言模型(LLM)处理长文本时,两个核心问题始终存在:计算开销高 和 中间信息丢失严重。为了解决这些问题,阿里通义实验室 Qwen-Doc 团队推出了一个全新上下文压缩框架 —— QwenLong...大语言模型# QwenLong-CPRS# QwenLong-CPRS-7B11个月前06690
Kyutai 推出全新语音系统Unmute,让任何大模型都能“说话”Kyutai 近日发布了一款名为 Unmute 的全新语音 AI 系统。与以往语音模型不同,Unmute 并不试图替代现有的语言模型,而是作为一个高度模块化的“插件”,可以无缝接入任意文本大语言模型...语音模型# Kyutai# Unmute# 语音模型11个月前01660
视频生成模型的高效推理新方案Jenga:无需重新训练模型即可实现HunyuanVideo和Wan2.1显著提速近年来,基于 DiT架构的视频生成模型在生成质量上取得了显著突破,但其高昂的计算成本却严重限制了实际部署与落地。 为了解决这一瓶颈,来自香港中文大学、香港科技大学、快手科技和思谋科技的研究团队提出了 ...视频模型# HunyuanVideo# Jenga# Wan2.111个月前05150
MiniMax推出视觉三重统一强化学习(RL)系统 V-Triune :使视觉语言模型能够在单一训练流程中联合学习视觉推理和感知任务MiniMax推出视觉三重统一强化学习(RL)系统 V-Triune ,使视觉语言模型能够在单一训练流程中联合学习视觉推理和感知任务。该系统通过整合三个互补组件——样本级数据格式化(Sample-Le...多模态模型# MiniMax# V-Triune# 视觉语言模型11个月前05300