
近年来,基于 DiT架构的视频生成模型在生成质量上取得了显著突破,但其高昂的计算成本却严重限制了实际部署与落地。
为了解决这一瓶颈,来自香港中文大学、香港科技大学、快手科技和思谋科技的研究团队提出了 Jenga —— 一种全新的推理优化框架,能够在不牺牲生成质量的前提下,将视频生成速度从“分钟级”压缩至“秒级”,极大提升了 DiT 类模型的实用性和效率。

问题背景:DiT 模型为何“慢”?
当前主流的视频生成模型多采用 DiT 架构,虽然生成效果优秀,但在推理阶段存在两大核心性能瓶颈:
- 自注意力机制的二次复杂度:随着 token 数量增加,计算量呈平方增长;
- 扩散过程的多步迭代特性:需要多次去噪步骤,耗时且资源密集。
这些因素使得即使在高端硬件上,生成一个高质量视频也可能需要数分钟甚至更久,难以满足实时或大规模部署需求。
二、Jenga 的解决方案:快而不失准
Jenga 提出了两项关键优化策略,无需重新训练模型即可实现显著提速,同时保持生成质量。
✅ 1. 动态稀疏注意力(Dynamic Token Carving)
- 利用**空间填充曲线(SFC)**对视频 latent 进行分块;
- 在每一步中动态选择最相关的 token 子集进行交互;
- 显著减少注意力计算量,降低内存占用。
✅ 2. 渐进式分辨率生成(Progressive Resolution)
- 将生成过程分为多个阶段,从低分辨率开始逐步提升;
- 早期阶段使用更少 token,后期逐步精细化;
- 减少了整个流程中的计算负担。
此外,Jenga 还引入了两个辅助模块:
- 文本注意力增强(Text-Attention Amplifier):强化文本引导,提高内容一致性;
- 时间步跳过(Timestep Skip):跳过部分扩散时间步,进一步压缩推理时间。
---要几分钟来生成这样的视频,而 Jenga 可以在几秒钟内完成,同时保持高质量的生成效果。
主要功能
- 高效视频生成:通过动态稀疏注意力和渐进式分辨率策略,显著减少推理时间。
- 保持生成质量:在加速的同时,保持与原始模型相当的生成质量。
- 无需重新训练:作为即插即用的解决方案,Jenga 不需要对现有模型进行重新训练。
- 多模型适配:支持多种视频生成模型,包括文本到视频(T2V)、图像到视频(I2V)和经过蒸馏的模型。
主要特点
- 动态稀疏注意力(Dynamic Token Carving):通过动态选择相关 token 交互,减少注意力计算的复杂度。
- 渐进式分辨率(Progressive Resolution):分阶段逐步增加分辨率,减少早期阶段的 token 数量,提高效率。
- 文本注意力增强(Text-Attention Amplifier):通过增加文本注意力权重,减少对局部邻域的关注,增强内容丰富度。
- 时间步跳过(Timestep Skip):通过跳过部分时间步,进一步减少计算量。
工作原理
- 动态稀疏注意力:Jenga 使用空间填充曲线(Space-Filling Curves, SFC)将视频 latent 分块,并通过块级注意力机制动态选择相关 token 交互,减少计算量。
- 渐进式分辨率:将生成过程分解为多个阶段,从低分辨率开始,逐步增加分辨率,减少早期阶段的 token 数量。
- 文本注意力增强:通过增加文本注意力权重,减少对局部邻域的关注,增强内容丰富度。
- 时间步跳过:通过跳过部分时间步,减少扩散模型的计算量。
测试结果
实验结果表明,Jenga 在多种最先进的视频扩散模型上实现了显著的加速,同时保持了可比的生成质量(在 VBench 上实现 8.83 倍加速,仅有 0.01% 的性能下降)。作为一种即插即用的解决方案,Jenga 无需模型重新训练,通过将推理时间从分钟缩短到秒,使现代硬件上实现实用、高质量的视频生成成为可能。
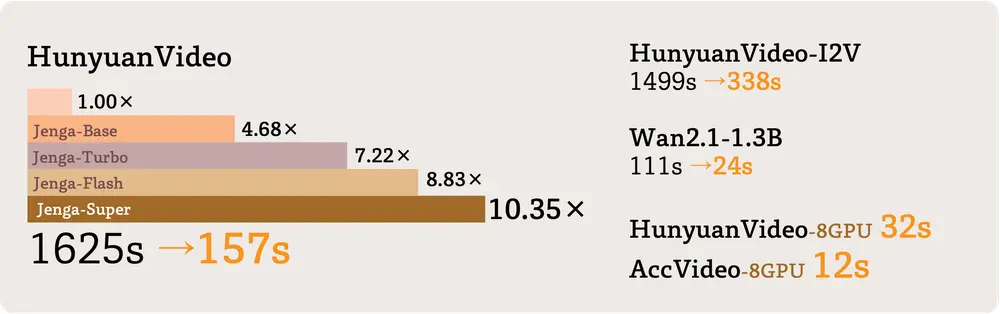
Jenga 在多个主流视频生成模型上进行了验证,结果如下:
| 模型 | 加速倍数 | 推理时间对比 | 质量损失 |
|---|---|---|---|
| HunyuanVideo | 8.83× | 1625s → 184s | 0.01% |
| HunyuanVideo-I2V | 4.43× | 1499s → 338s | 可忽略 |
| AccVideo(蒸馏模型) | 2.12× | 161s → 76s | 基本无损 |
- HunyuanVideo:在 720P 分辨率下,Jenga-Flash 实现了 8.83× 的加速,推理时间从 1625 秒缩短到 184 秒,性能仅下降 0.01%。
- HunyuanVideo-I2V:在图像到视频任务中,Jenga 实现了 4.43× 的加速,推理时间从 1499 秒缩短到 338 秒。
- AccVideo:在经过蒸馏的模型中,Jenga 实现了 2.12× 的加速,推理时间从 161 秒缩短到 76 秒。
- 用户研究:在用户研究中,Jenga 生成的视频在视觉质量、语义一致性和整体质量上与基线模型相当。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











