交互式世界生成模型 Yume:通过输入图像、文本或视频来创建一个动态、逼真且可交互的世界由上海市人工智能实验室、复旦大学与上海创新研究院联合研发的新型生成模型 Yume 正式亮相。该模型旨在突破传统生成式 AI 的静态局限,构建一个可探索、可控制、高保真且动态演化的虚拟世界。 项目主页...视频模型# Yume# 交互式世界生成模型9个月前02440
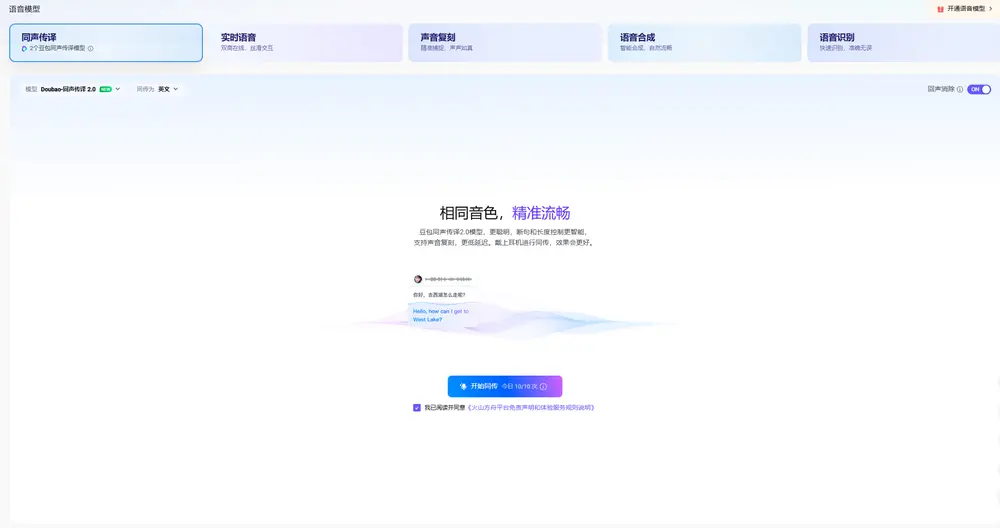
字节跳动发布 Seed LiveInterpret 2.0:首个中英同传延迟与准确率接近人类水平的端到端语音翻译系统在跨语言实时沟通的长期挑战中,机器能否真正替代人类同声传译?字节跳动 Seed 团队给出了迄今为止最接近“是”的答案。 今日,字节跳动正式发布 Seed LiveInterpret 2.0 —— 一款...语音模型# Seed LiveInterpret 2.0# 同声传译模型# 字节跳动9个月前03430
浙大 × 阿里巴巴推出 OmniAvatar:首个支持音频驱动全身动画的可控虚拟人视频生成模型在数字人、虚拟主播、AI 视频创作等领域,仅靠语音生成逼真且动作自然的虚拟形象视频,一直是生成式 AI 的关键挑战之一。 现有音频驱动视频生成方法大多聚焦于面部动画,尤其是唇部同步,而对身体动作、姿态...视频模型# OmniAvatar# 虚拟人9个月前02600
谷歌发布 Gemini 2.5 Flash-Lite 稳定版:更快、更轻、更具成本效益谷歌宣布,Gemini 2.5 Flash-Lite 正式进入稳定版本并全面开放使用。作为 Gemini 2.5 模型系列中速度最快、成本最低的成员,该模型旨在为大规模生产场景提供高性价比的智能推理能...大语言模型# Gemini 2.5 Flash-Lite# 谷歌9个月前01290
阿里Qwen团队推出新一代代码大模型 Qwen3-Coder阿里通义Qwen团队发布全新代码大模型系列 Qwen3-Coder,这是目前 Qwen 系列中最具代理(Agent)能力的代码模型。此次发布的最大版本为 Qwen3-Coder-480B-A35B-I...大语言模型# Qwen Code CLI# Qwen3-Coder# 代码大模型9个月前02210
南洋理工大学 S-Lab 提出新型对象移除框架ObjectClear ,精准消除物体及其阴影、反射在图像编辑任务中,移除一个物体看似简单,实则极具挑战。 不仅要将目标对象从画面中“擦除”,还需同步清除其带来的视觉副产物——如阴影、倒影、高光、遮挡痕迹等。若处理不当,即便主体消失,残留的影子或反光仍...图像模型# ObjectClear# 南洋理工大学# 对象移除9个月前04720
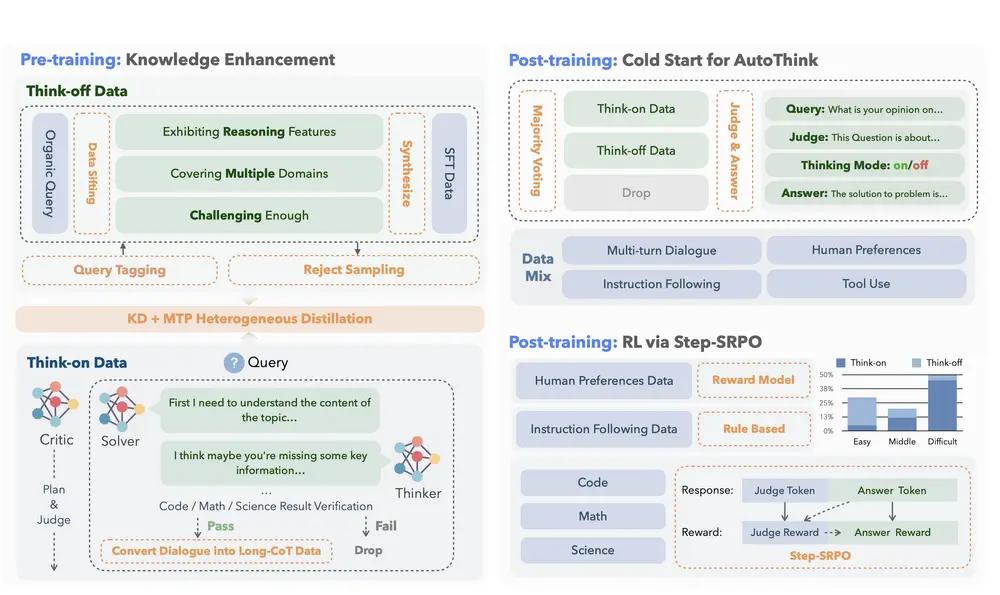
快手 Kwaipilot 团队开源 40B 大模型 KAT-V1-40B :用 AutoThink 实现智能“何时思考”在当前大模型普遍追求“深度推理”的趋势下,一个更现实的问题逐渐浮现:是否每个问题都需要长篇思维链? 过度使用思维链(Chain-of-Thought, CoT)不仅增加计算开销、拖慢响应速度,还可能导...大语言模型# KAT-V1-40B# 快手9个月前01380
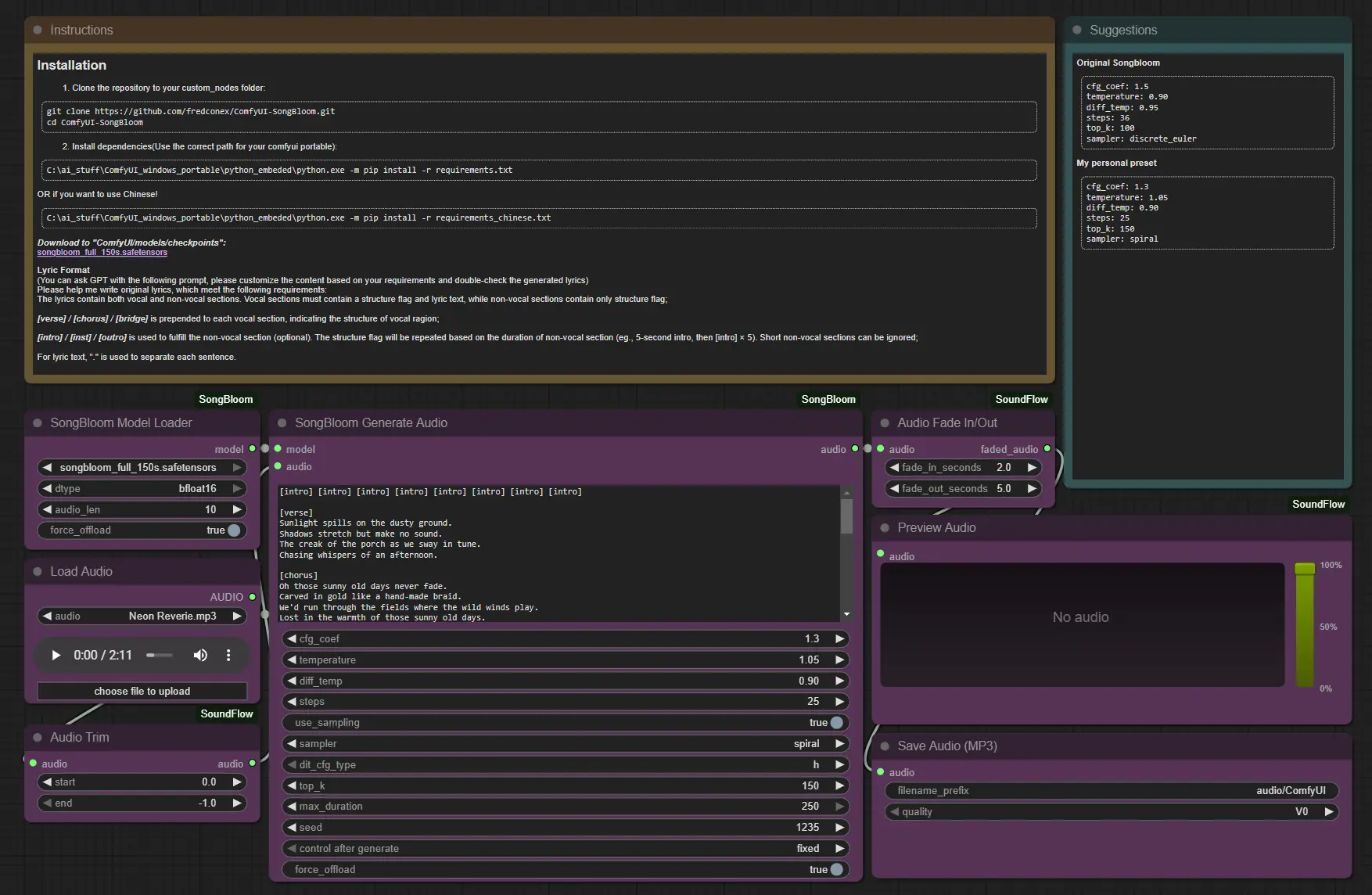
SongBloom:一种实现结构连贯与高保真度的全曲生成新框架在自动音乐生成领域,生成一首具备完整结构、风格统一、人声与伴奏和谐融合的全长歌曲,依然是极具挑战性的任务。 现有方法——无论是基于语言模型的自回归生成,还是基于扩散模型的音频合成——往往面临两难困境...语音模型# SongBloom# 音乐生成9个月前01070
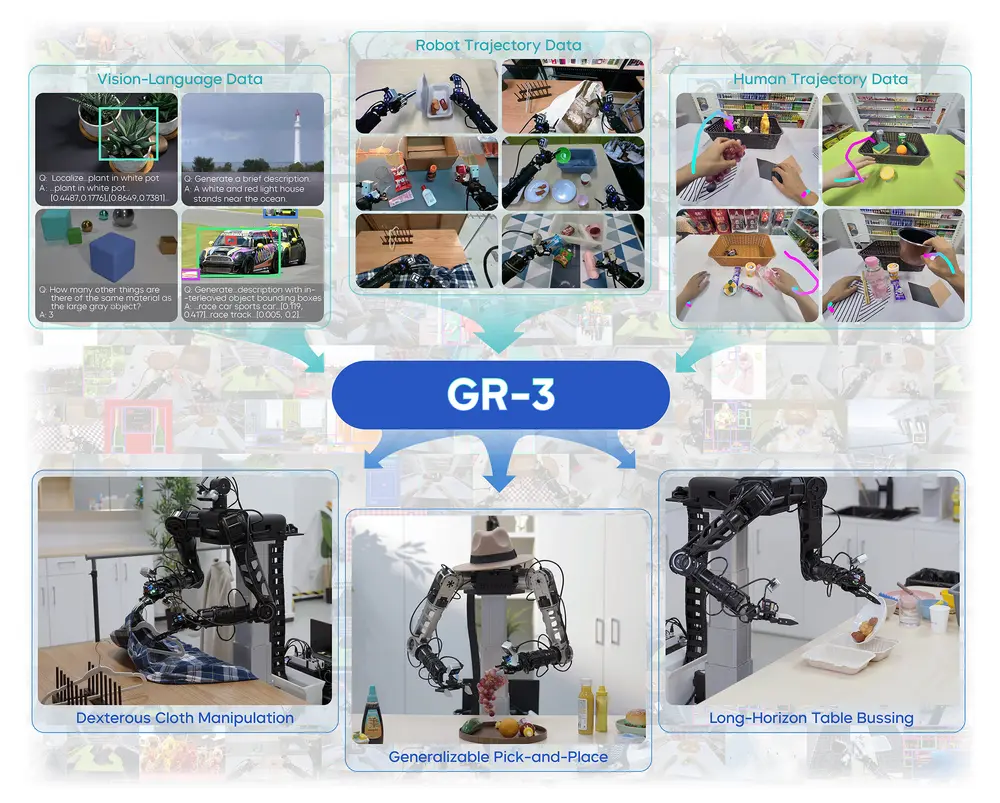
字节跳动Seed团队发布新一代机器人操作大模型Seed GR-3字节跳动Seed团队近日推出一款面向复杂操作任务的大规模机器人模型——Seed GR-3(Generalist Robot Model-3)。该模型具备良好的泛化能力,支持长序列任务执行与多模态指令理...多模态模型# Seed GR-3# 字节跳动9个月前01980
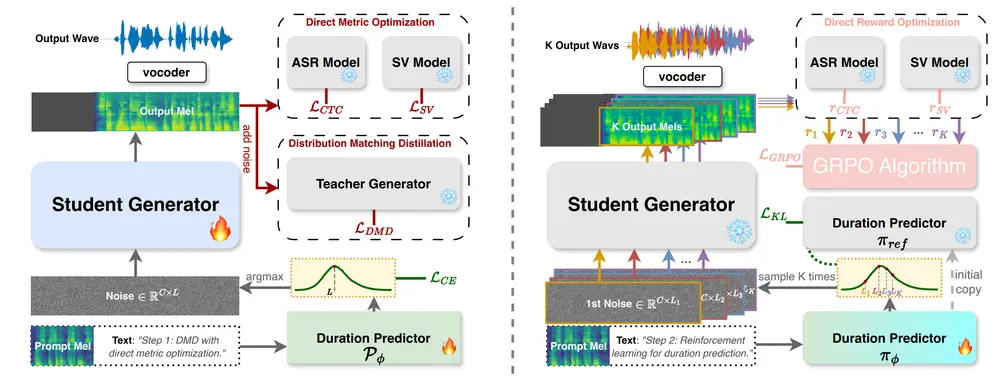
DMOSpeech 2:用强化学习优化语音合成的时长预测在零样本文本到语音(TTS)领域,基于扩散模型的系统近年来取得了显著进展。然而,大多数方法仍难以实现对整个生成流程的端到端感知质量优化——尤其是时长预测这一关键组件,长期依赖自监督训练,未能与语音生成...语音模型# DMOSpeech 2# TTS 框架9个月前03510
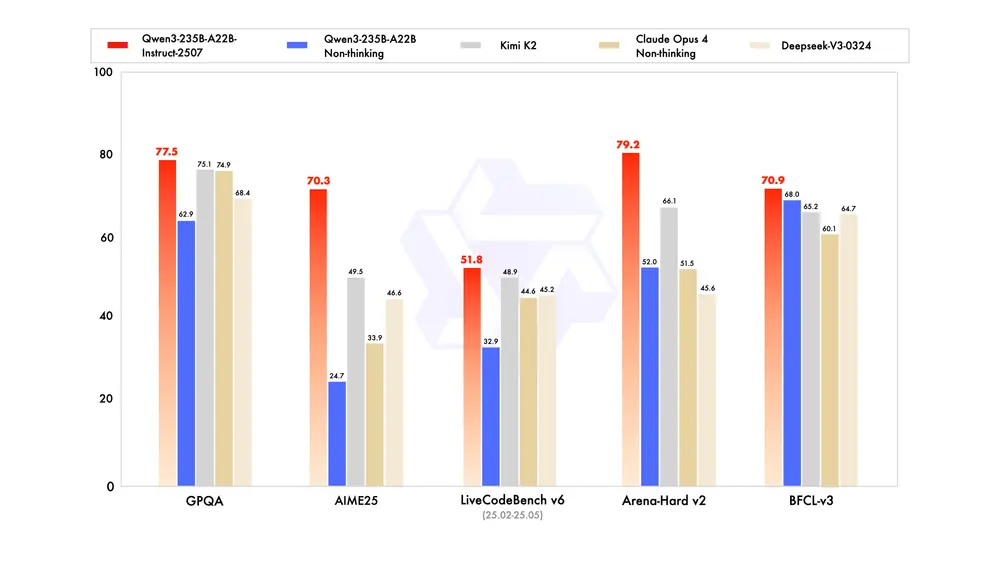
告别旧版,迎接进化!阿里Qwen团队发布Qwen3-235B-A22B-Instruct-2507在与社区深入交流并综合反馈后,阿里Qwen团队做出一项重要决策:停止使用混合“思维模式”(Thinking Mode)的训练方式,转而采用 Instruct 与 Thinking 模型分离训练 的新策...大语言模型# Qwen3-235B-A22B-Instruct-25079个月前06690
CoPart:基于“部分”的3D生成框架,让AI更精细地理解3D对象在3D内容生成领域,早期的研究主要依赖于2D渲染图像的多视角驱动方法。然而,随着技术的发展,3D原生扩散模型逐渐展现出更强的生成能力,尤其是在几何建模和纹理细节方面,因为它直接利用了真实3D数据所包含...3D模型# 3D生成# CoPart9个月前03370