
在3D内容生成领域,早期的研究主要依赖于2D渲染图像的多视角驱动方法。然而,随着技术的发展,3D原生扩散模型逐渐展现出更强的生成能力,尤其是在几何建模和纹理细节方面,因为它直接利用了真实3D数据所包含的空间信息。
尽管3D扩散技术取得了显著进展,但在处理复杂3D对象时,仍然面临以下几个关键挑战:
- 单一潜在表示难以捕捉复杂结构:大多数方法使用统一的潜在表示来编码整个3D对象,容易在生成多部件对象时丢失细节。
- 缺乏对部分独立性与关系的建模:3D资产通常是逐部分设计的,但当前方法忽略了部分之间的独立性和相互关系。
- 全局控制缺乏局部可控性:现有方法通常依赖于文本、图像或点云等全局条件,难以实现对对象局部部件的精细控制。
为了解决这些问题,来自香港科技大学、香港中文大学与商汤研究院的研究人员提出了一种全新的3D生成框架:CoPart。

什么是 CoPart?
CoPart(Contextual Part-based 3D Generation) 是一个基于“部分”的3D生成框架,用于生成高质量、多样化的3D物体。它通过将复杂对象分解为多个上下文相关的部分潜变量(part latents),并同时生成这些部分,从而提升生成质量与可控性。
这种方法不仅更贴近3D设计师的创作方式,也带来了以下优势:
- ✅ 降低编码复杂度:将复杂对象拆解为多个简单部分,减轻模型负担。
- ✅ 增强部分建模能力:支持对每个部分进行独立学习与关系建模。
- ✅ 实现局部控制:支持用户通过文本描述或3D边界框对特定部分进行编辑和生成。
CoPart 的工作原理
1. 部分表示编码
CoPart 使用两个独立的编码器分别提取几何潜变量和图像潜变量:
- 几何潜变量:从3D点云和法线中提取特征,通过3D部分VAE进行编码。
- 图像潜变量:将3D部分渲染为多视角图像,使用预训练图像VAE进行编码。
2. 同步扩散与互指导机制
在扩散过程中,CoPart引入了互指导(Mutual Guidance)机制,通过以下方式增强生成一致性:
- 跨模态注意力:在3D几何与2D图像潜变量之间建立联系。
- 跨部分注意力:确保不同部分之间在结构和语义上的一致性。
此外,还引入了全局引导分支,进一步增强整体结构的协调性。
3. 3D边界框与文本引导
CoPart 支持通过以下方式增强生成的可控性:
- 3D边界框条件:将3D边界框编码为几何潜变量,用于解决部分顺序的歧义问题。
- 部分级文本提示:用户可以为每个部分提供独立的文本描述,包括形状、外观以及与整体对象的关系。
4. 优化与后处理
- 使用扩散模型的标准去噪损失函数,分别对3D和2D潜变量进行监督训练。
- 利用3D基础模型对生成结果进行后处理,进一步提升几何质量和纹理细节。
CoPart 的核心特性
| 特性 | 说明 |
|---|---|
| 多部分表示 | 将3D对象拆分为多个部分潜变量,每个部分独立建模 |
| 互指导机制 | 跨模态与跨部分注意力确保一致性 |
| 局部可控性 | 支持文本描述与3D边界框对部分进行精细控制 |
| 高质量生成 | 在几何结构与纹理细节上表现优异 |
| 多样化应用 | 支持部分编辑、关节物体生成、迷你场景构建等 |
实验结果与评估
定量评估
- 在 CLIP 和 ULIP 等指标上,CoPart 在部分感知任务中优于 Rodin、SALAD 等现有方法。
- 用户调研结果显示,CoPart 在生成高质量、可编辑的3D部分方面表现突出。
定性分析
- CoPart 在生成小部件(如耳朵、手柄、轮子)时表现尤为出色。
- 与 SALAD 等方法相比,CoPart 不受限于特定类别,能生成更多样化的3D对象。
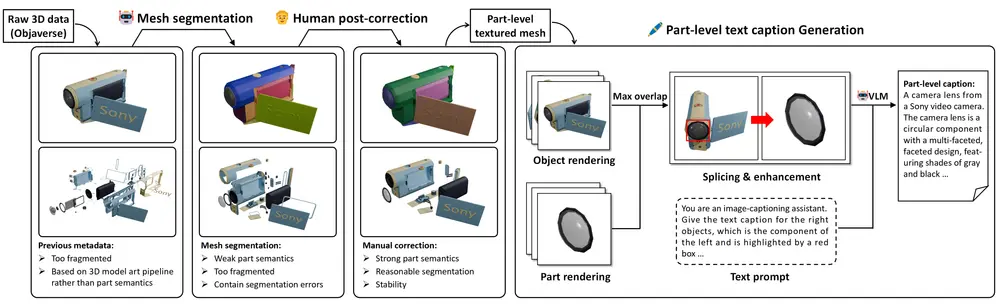
数据集支持:PartVerse
为了验证 CoPart 的有效性,研究人员还构建了一个大规模的3D部分数据集:PartVerse,包含超过 91,000 个3D部分,涵盖多个类别,为模型训练与评估提供了坚实基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











