
你有没有想象过,仅凭一段普通的手机视频,就能“穿越”到画面中,从任意角度和时间点重新观察整个动态场景?比如在一场足球比赛中,你可以自由“飞行”在球场上空,从不同角度观看球员跑动、球的轨迹,甚至追踪每一个物体的3D运动轨迹。
这一切,MoVieS 正在让它们成为现实。
近日,由北京大学、字节跳动与卡内基梅隆大学联合提出的新模型 MoVieS,首次实现了外观、几何与运动的统一建模,能够在一秒钟内从单目视频中生成高质量的 4D 动态新视角(Dynamic Novel View Synthesis),并支持多种下游任务。
这项成果不仅速度快、泛化能力强,更在无需任务特定监督的情况下,实现了多个任务的零样本应用。
什么是 MoVieS?
MoVieS(Motion Vector Space) 是一种新型的前馈模型,专门用于从单目视频中重建动态3D场景,并实时生成任意视角的新画面。
它的核心创新在于:使用像素对齐的高斯基元网格表示动态3D场景,并明确建模其随时间变化的运动信息。
简单来说,MoVieS 能够从一段普通视频中提取出场景的“动态结构”,然后让你像操作3D游戏一样,自由切换视角、查看运动轨迹,甚至进行3D点追踪和移动物体分割。
MoVieS 的四大核心能力
✅ 1. 4D动态新视角合成(4D Dynamic Novel View Synthesis)
仅凭一段单目视频,MoVieS 可以在任意时间点、任意视角生成全新的画面,实现类似“自由视角视频”的效果。
✅ 2. 3D几何重建与外观建模
MoVieS 能联合建模场景的外观(颜色)、几何(形状)与运动(轨迹),从而实现高质量的3D场景重建。
✅ 3. 3D点追踪(3D Point Tracking)
MoVieS 可追踪视频中每个像素点在3D空间中的运动轨迹,为动作分析、视频编辑等任务提供结构化支持。
✅ 4. 零样本应用(Zero-shot Applications)
MoVieS 还能自然支持多种无需额外训练的任务,例如:
- 🌊 场景流估计(Scene Flow Estimation)
- ✂️ 运动目标分割(Moving Object Segmentation)
为什么 MoVieS 如此特别?
一秒钟完成4D重建,速度领先几个数量级
MoVieS 的一大亮点是其极高的运行效率。相比传统方法,它能在一秒钟内完成整个4D重建流程,速度提升达几个数量级。
这意味着,MoVieS 不仅适用于科研实验,也具备在工业级视频处理、影视特效、AR/VR、智能视频分析等场景中大规模落地的潜力。
统一建模:外观、几何与运动的联合学习
MoVieS 的另一大突破在于:在一个统一的框架中联合建模外观、几何和运动,打破了传统方法中任务割裂的局限。
这种统一建模方式不仅提升了模型的泛化能力,也为后续任务提供了更强的结构化输出。
大规模训练,泛化能力强
MoVieS 可在包含静态与动态场景的多样化数据集上进行大规模训练,显著减少了对特定任务监督信号的依赖。
这使得 MoVieS 在面对未见过的场景或任务时,依然能保持良好的表现。
MoVieS 的工作原理简述
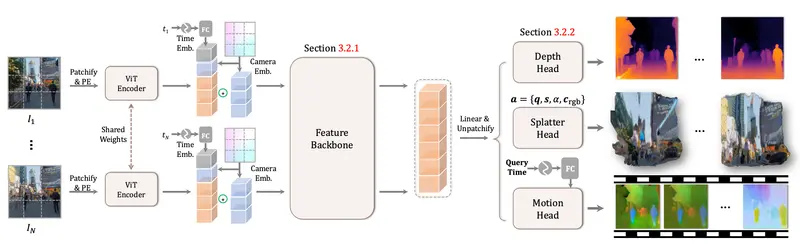
MoVieS 的核心架构包括以下几个关键步骤:
- 动态场景表示:使用“动态溅射像素”(Dynamic Splatter Pixels)表示场景,将每个像素映射为一个3D高斯基元,并建模其随时间的变化。
- 特征提取与融合:通过预训练的 Transformer 主干网络提取视频帧特征,并融合相机参数和时间信息。
- 多任务预测头:包括深度头(Depth Head)、溅射头(Splatter Head)和运动头(Motion Head),分别预测深度、外观属性和运动属性。
- 可微渲染:利用可微分的3D高斯渲染框架,将预测的3D高斯原语渲染为图像,用于监督训练。
实验结果验证:速度快、性能优、泛化强
MoVieS 在多个基准任务中表现优异:
- 新视角合成:在多个静态与动态数据集上,MoVieS 的合成质量与现有方法相当甚至更优,同时推理速度提升数倍。
- 3D点追踪:在 TAPVid-3D 基准测试中,MoVieS 的3D点追踪精度优于或接近现有技术。
- 零样本应用:通过将运动向量转换为目标相机坐标系,MoVieS 可自然实现场景流估计和运动目标分割,无需额外训练。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











