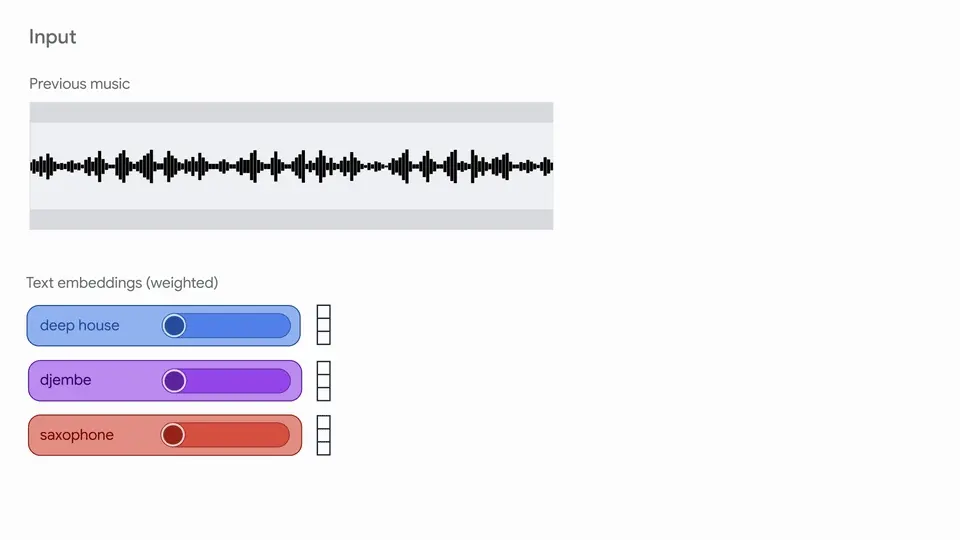
谷歌开源实时音乐生成模型 Magenta RealTime:8亿参数,支持文本/音频操控今天,Google DeepMind 宣布开源一款名为 Magenta RealTime 的实时音乐生成模型。该模型基于 Apache 2.0 许可证发布,具备实时交互能力,能够根据文本提示或音频示例...语音模型# Magenta RealTime# 音乐生成模型6个月前02820
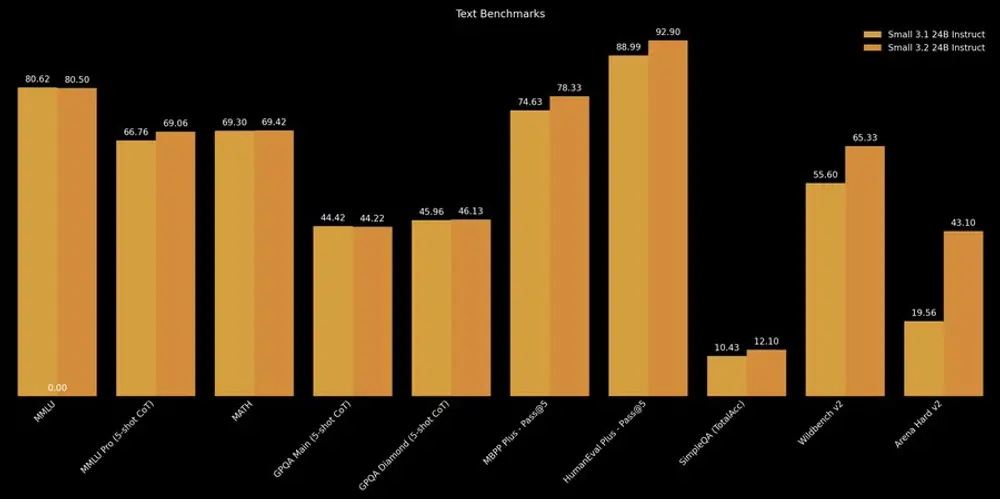
Mistral AI 发布 Mistral Small 3.2:小幅迭代,体验提升Mistral AI 推出了其中型模型系列的新版本——Mistral Small 3.2。这是对上一版 Mistral Small 3.1 的一次轻量级升级,在多个关键使用场景中带来了显著优化。 模型...大语言模型# Mistral AI# Mistral Small 3.26个月前01220
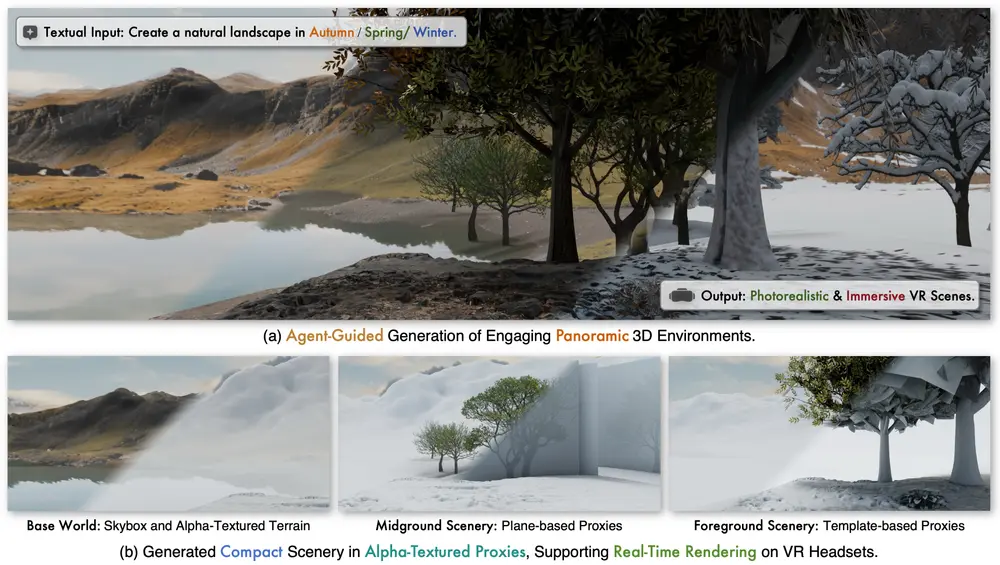
字节跳动推出新型框架ImmerseGen:用于从文本提示自动生成沉浸式 3D 场景字节跳动和浙江大学的研究人员推出新型框架ImmerseGen ,用于从文本提示自动生成沉浸式 3D 场景。ImmerseGen 通过使用轻量级的几何代理(如简化地形和带有 alpha 通道的纹理平面...3D模型# ImmerseGen# 字节跳动6个月前02030
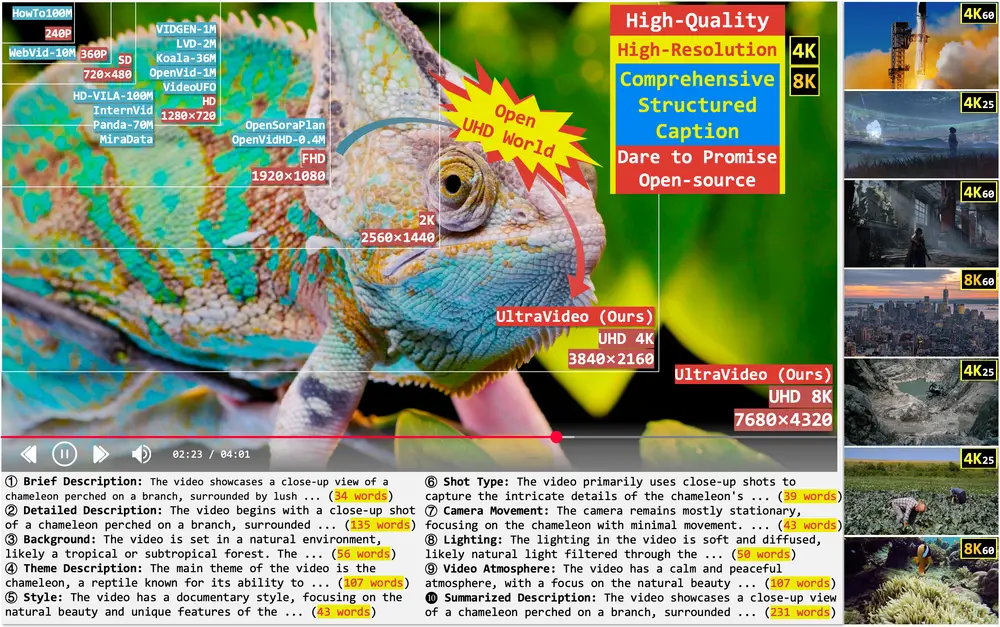
UltraVideo 与 UltraWAN:首个支持原生 UHD 视频生成的开源数据集与模型随着高质量视频内容需求的快速增长,如电影级超高清(UHD)制作、沉浸式媒体和短视频创作,对文本到视频(T2V)模型的能力提出了更高要求。 然而,现有公开数据集在分辨率、图像质量及字幕细节方面存在明显不...视频模型# UltraVideo# UltraWAN# UltraWanComfy6个月前03600
EmoNet:迈向真正“有情感”的AI,LAION开源新一代情感智能模型人工智能的发展正进入一个全新的阶段:从理解语言到理解情绪。尽管AI在语言处理、推理能力等方面取得了显著进展,但在情感智能(Affective Intelligence)这一维度上,仍然存在巨大空白。 ...多模态模型# EmoNet# LAION AI# 情感智能模型6个月前02450
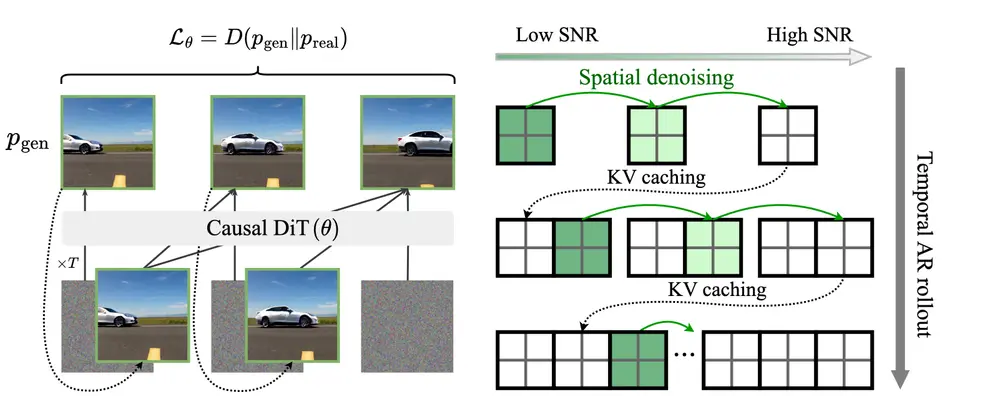
新型训练范式Self Forcing:用于自回归视频扩散模型,解决模型在训练和推理时的分布不一致问题Adobe研究和德克萨斯大学奥斯汀分校的研究人员推出新型训练范式Self Forcing ,用于自回归视频扩散模型,旨在解决模型在训练和推理时的分布不一致问题(即暴露偏差问题),从而提高视频生成的...视频模型# Self Forcing# 训练范式6个月前04170
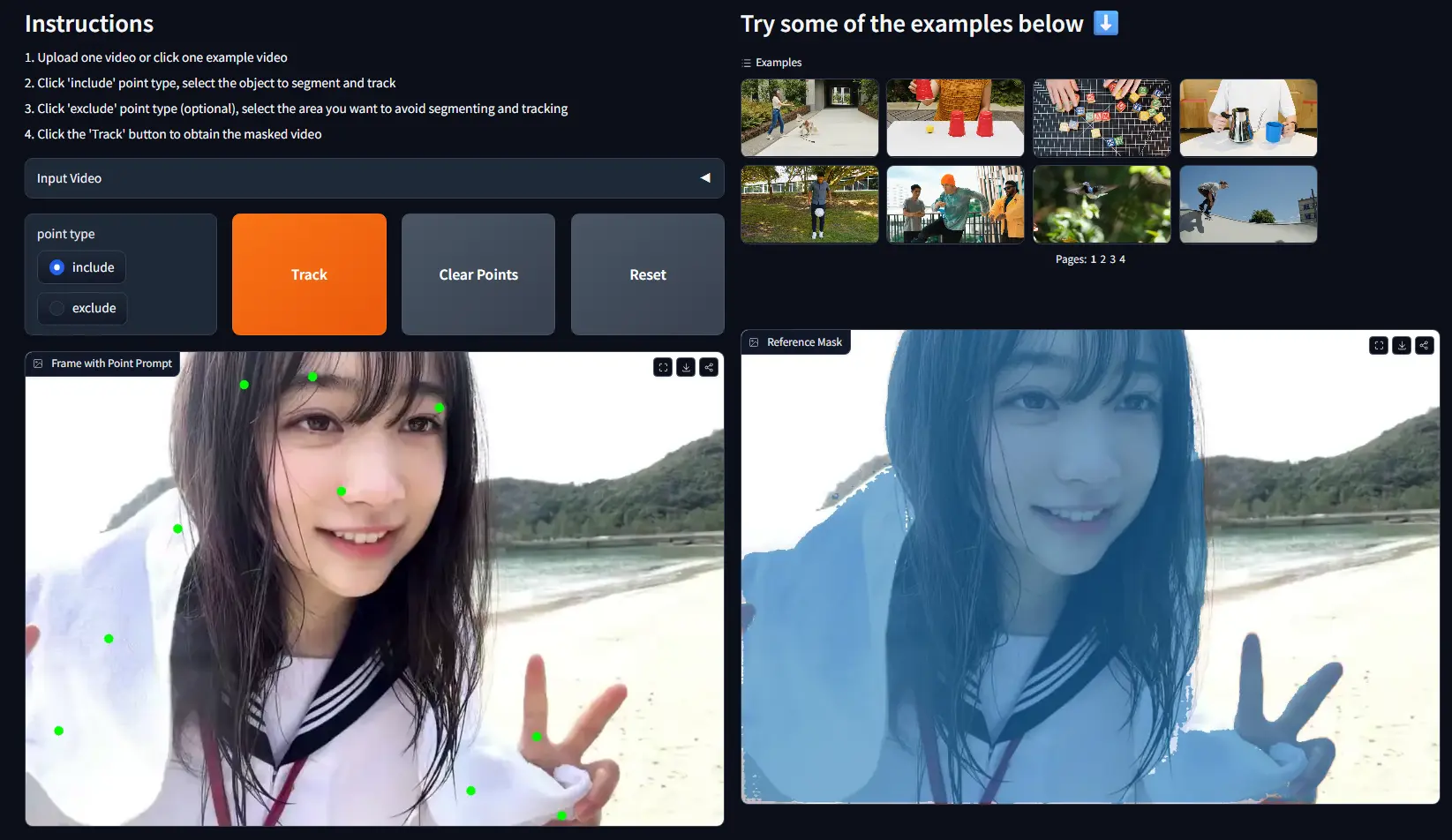
EdgeTAM:Meta 与南洋理工等联合推出可在手机运行的视频分割模型,比 SAM 2 快 22 倍由 Meta Reality 实验室、南洋理工大学 和 上海人工智能实验室 联合提出的新模型 EdgeTAM 引起了广泛关注。该模型是对 Segment Anything Model 2(SAM 2...视频模型# EdgeTAM# SAM 2# 视频分割模型6个月前02380
Midjourney 正式发布 V1 视频模型:从文本到视频,AI创作迈入新阶段6月18日,Midjourney 宣布正式推出其首款视频生成模型 V1,标志着这家以图像生成闻名的 AI 公司,正式进军视频内容创作领域。 这一更新不仅打通了原有的图文生成生态,还实现了从文本直接生成...视频模型# Midjourney6个月前01120
Jan-Nano:40亿参数的紧凑型研究专用语言模型正式上线Menlo发布一款专为深度研究任务设计的小型语言模型 Jan-Nano 。该模型拥有 40亿参数规模,在保证轻量级部署的同时展现出强大的推理能力。此模型基于 Qwen3-4B 构建,并经过 DAPO ...大语言模型# Jan-Nano# 小型语言模型6个月前02660
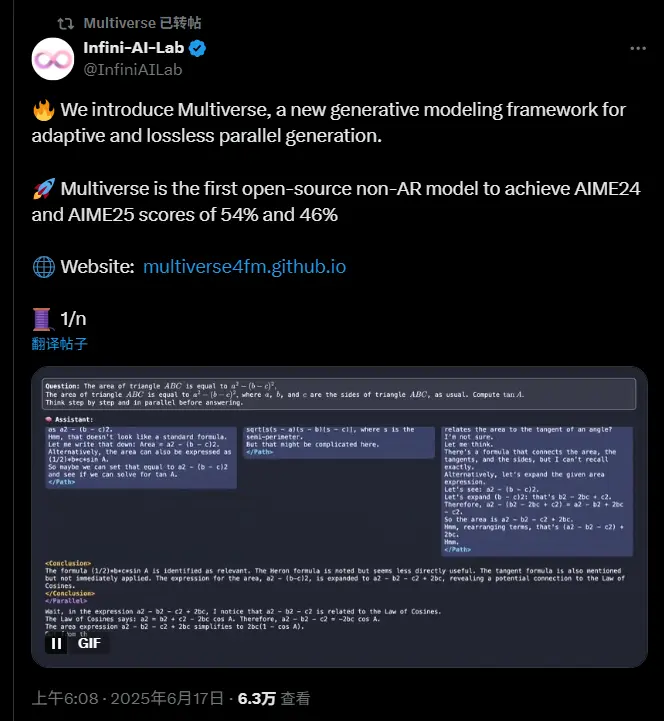
Multiverse:全球首个开源的非自回归并行推理框架,推理速度提升2倍卡内基梅隆大学与英伟达联合推出了一项具有突破性的生成模型框架——Multiverse。这是全球首个开源的非自回归(Non-Autoregressive)并行推理框架,在保持与主流自回归模型(AR-LL...大语言模型# Multiverse# 推理框架6个月前01480
MiniMax正式发布Hailuo 02:全球首个能生成高复杂度体操动作的视频模型MiniMax宣布推出全新视频生成模型——Hailuo 02,这是目前全球唯一一个能够高质量生成如“体操运动”这类高复杂度场景的AI视频模型。 地址:https://hailuoai.com/crea...视频模型# Hailuo 02# MiniMax6个月前01890
中科院团队推出多模态新模型 Stream-Omni,语音+视觉交互更高效由中国科学院计算技术研究所智能信息处理重点实验室、中国科学院人工智能安全重点实验室以及中国科学院大学联合提出,Stream-Omni 是一种新型的语言-视觉-语音多模态模型。该模型通过高效的模态对齐机...语音模型# Stream-Omni# 语言-视觉-语音多模态模型6个月前02570