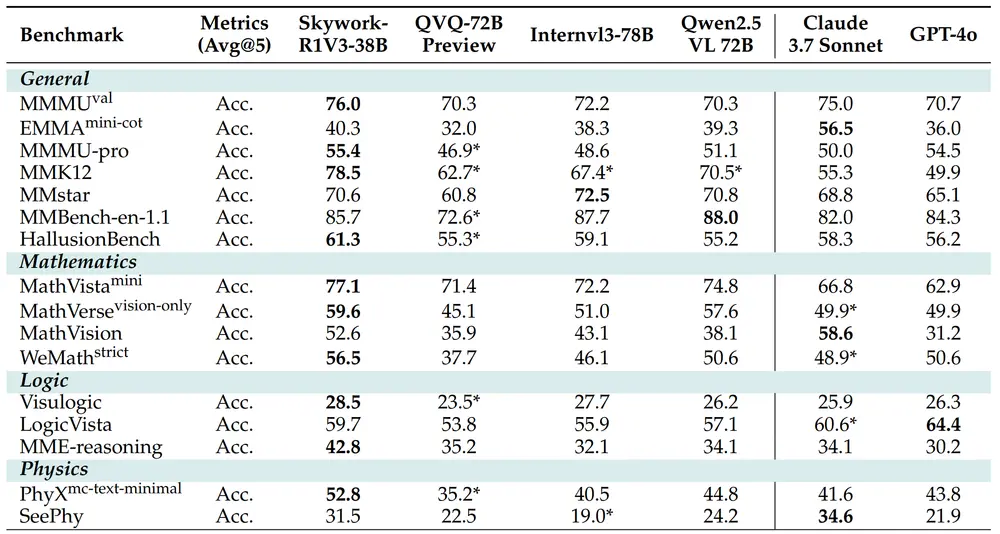
昆仑万维天工项目组推出多模态推理模型 Skywork-R1V3-38B昆仑万维天工项目组近日发布了 Skywork-R1V3-38B,这是其开源视觉-语言模型(VLM)系列 Skywork-R1V 的最新迭代版本,也是目前该系列中性能最强的多模态推理模型。基于 Inte...多模态模型# Skywork-R1V3-38B# 多模态推理模型# 昆仑万维5个月前02090
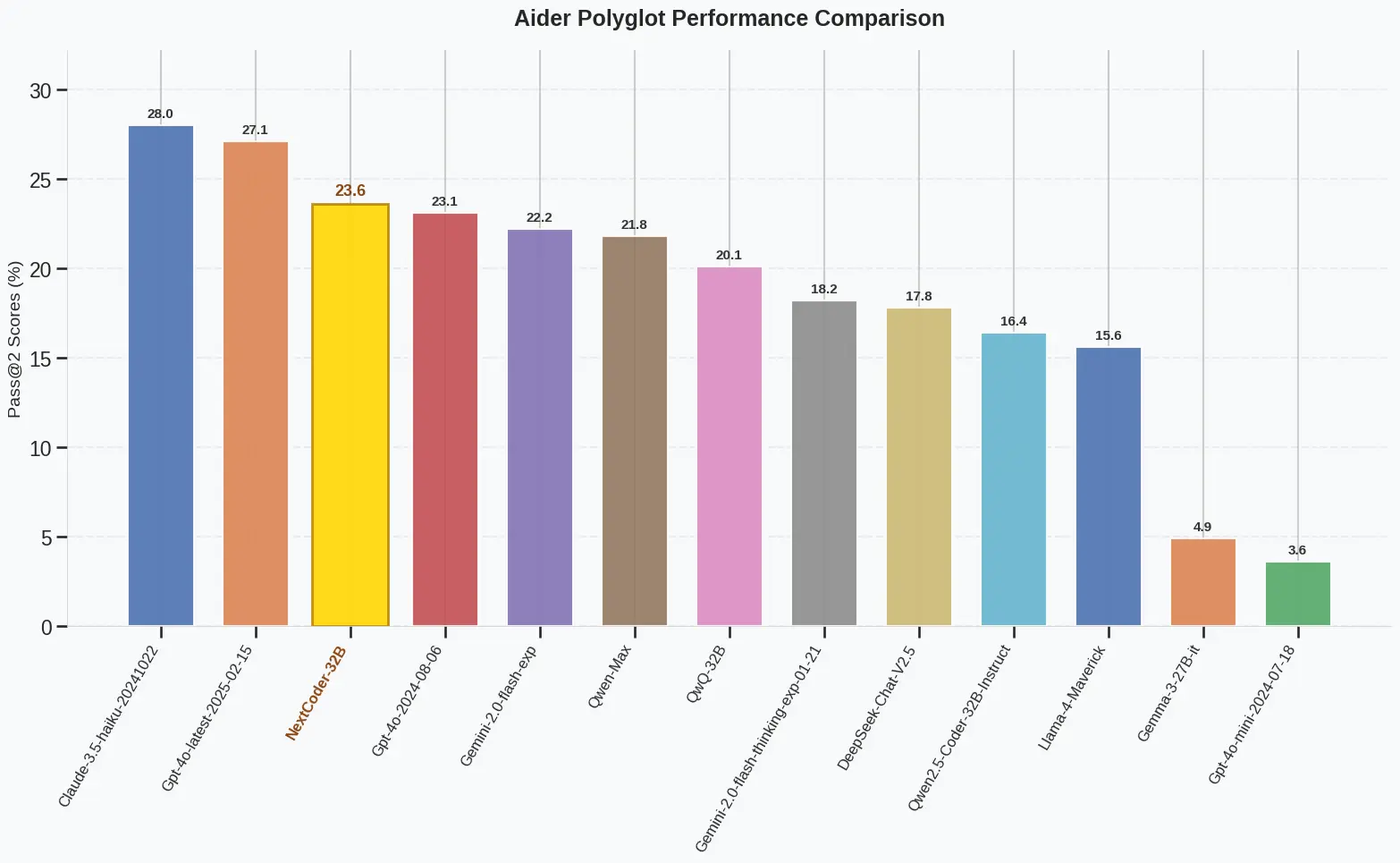
微软推出 NextCoder:基于 Qwen2.5-Coder 的高效代码编辑模型近年来,软件开发中的代码编辑需求日益增长,尤其是在维护和重构已有项目时。然而,现有的大语言模型在面对多样化的代码修改任务时,往往表现不佳。为了解决这一问题,微软联合相关研究团队提出了一套全新的方法,并...大语言模型# NextCoder# Qwen2.5-Coder# 代码编辑模型5个月前02160
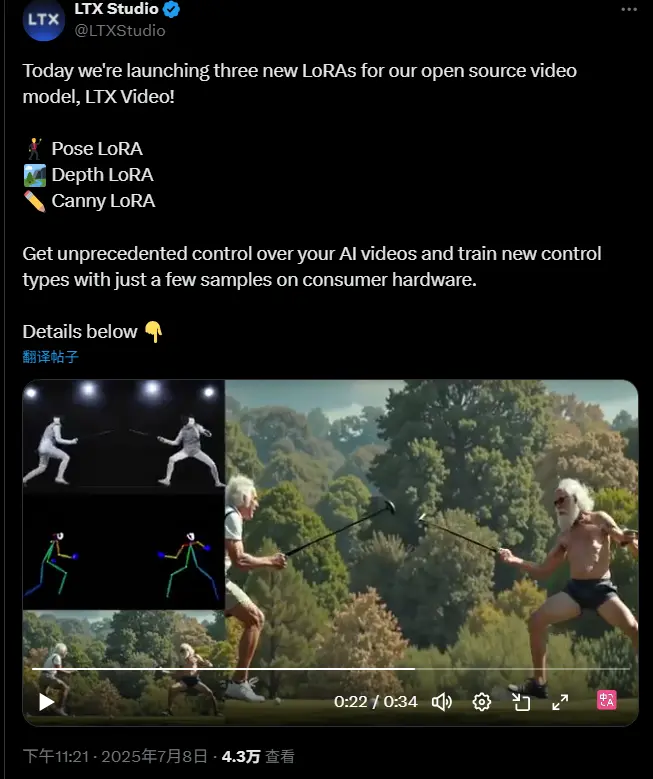
LTX Studio为其开源视频生成模型 LTX Video 推出三款全新 LoRA控制模型,为开源视频模型带来前所未有的控制力LTX Studio 为其开源视频生成模型 LTX Video 推出了三项全新的 LoRA 控制模块,让 AI 视频创作进入一个更具操控性与表现力的新阶段。 Depth Control: LTX-Vi...视频模型# LTX Studio# LTX Video6个月前01350
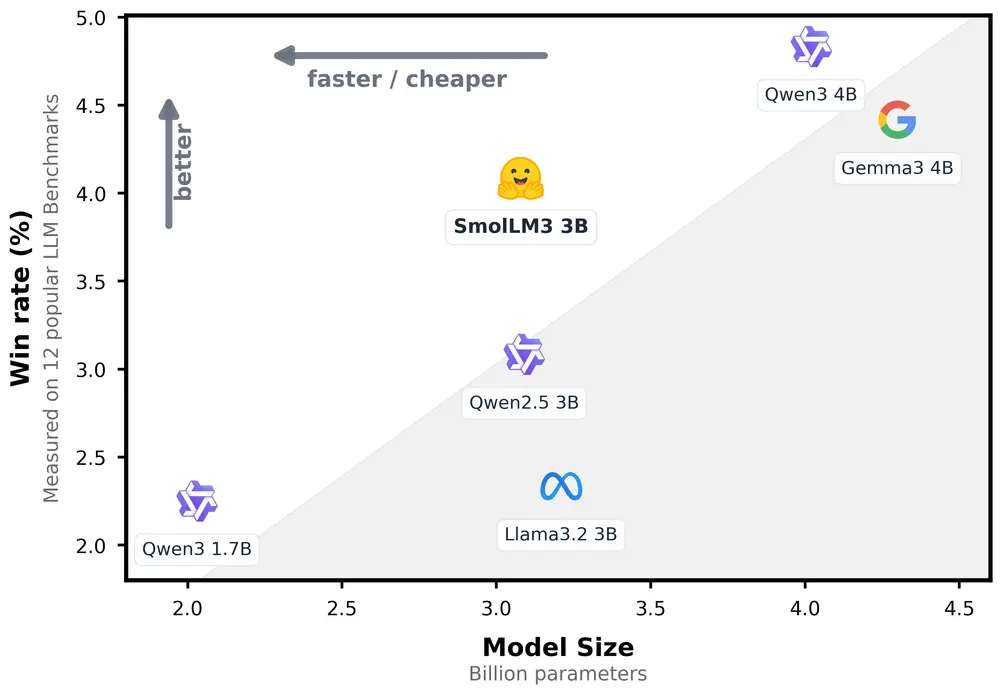
Hugging Face发布SmolLM3:3B 级全能小模型,支持推理/非推理双模式与 128k 上下文随着边缘计算和本地部署需求的增长,小型语言模型(Small Language Model, SLM) 正在成为新一代 AI 应用的关键组成部分。近日,Hugging Face 推出了其最新力作 —— ...大语言模型# Hugging Face# SmolLM3# 小模型6个月前0970
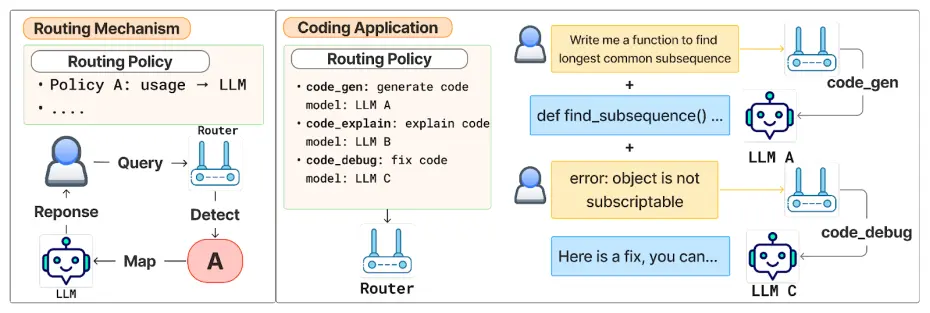
Katanemo Labs发布1.5B 路由模型Arch-Router-1.5B:实现 93% 准确率,无需昂贵微调在 LLM(大语言模型)应用场景日益复杂的背景下,如何将用户查询智能路由到最合适的模型,成为提升效率和体验的关键挑战。 近日,Katanemo Labs 推出了一个创新的解决方案 —— Arch-Ro...大语言模型# Arch-Router-1.5B# 路由模型6个月前01260
NovelAI 正式公开了其基于SD1.5的第二代图像生成模型 NovelAI Diffusion V2NovelAI 正式公开了其第二代图像生成模型 NovelAI Diffusion V2 的权重文件,供研究、个人使用及历史保存。这一举动意味着即使该模型在 NovelAI 官网停止服务后,用户仍可通...图像模型# NovelAI Diffusion V2# SD1.56个月前03020
DLoRAL:一种兼顾细节与时间一致性的视频超分辨率新方法在现实世界视频超分辨率(Real-VSR)任务中,如何从低质量(LQ)视频中恢复出既细节丰富又时间连贯的高质量(HQ)视频,是一个极具挑战性的问题。尤其是在使用预训练扩散模型(如 Stable Dif...视频模型# DLoRAL# 视频超分辨率6个月前03440
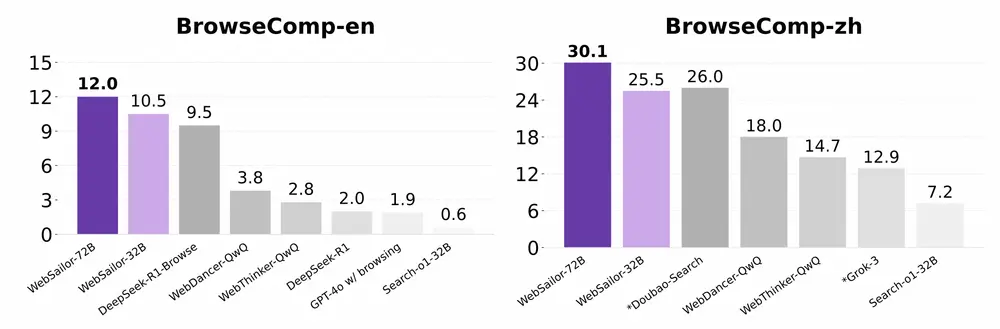
阿里通义实验室开源 WebSailor,登顶 BrowseComp 榜单的网络智能体近日,阿里云通义实验室正式开源了一款名为 WebSailor 的新型网络智能体(Web Agent),它具备强大的多步推理与信息检索能力,在高难度网页导航任务中表现出色。 GitHub:https...大语言模型# WebSailor# 网络智能体# 阿里通义实验室6个月前02180
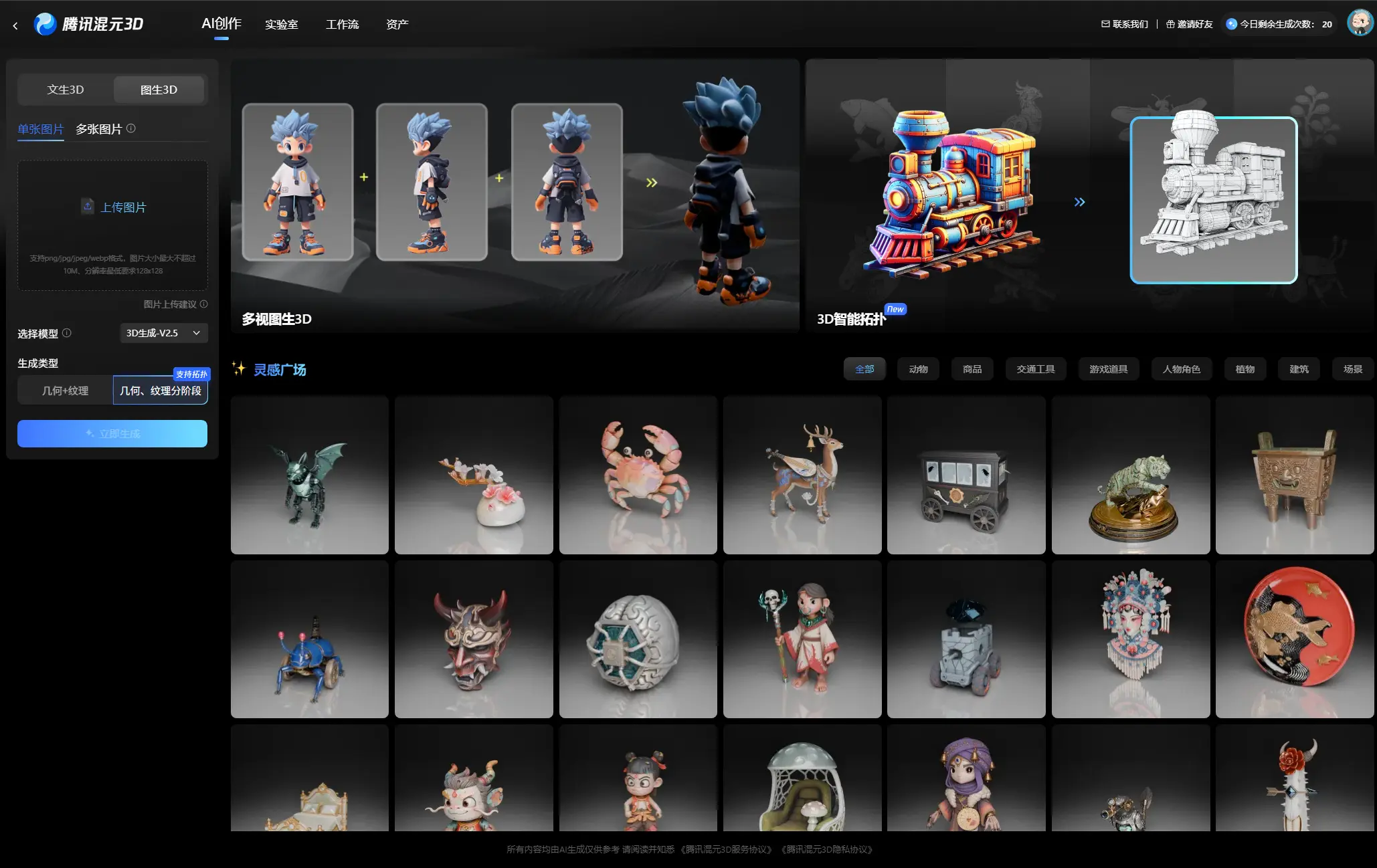
腾讯发布业界首个“美术级”AI 3D 生成模型Hunyuan3D-PolyGen2025 年 7 月 7 日,腾讯正式发布全新升级的 Hunyuan3D-PolyGen,这是全球首个专为艺术级 3D 建模设计的人工智能生成模型。该模型不仅在几何精度和拓扑优化方面达到新高度,更首次...3D模型# Hunyuan3D-PolyGen# 腾讯6个月前01490
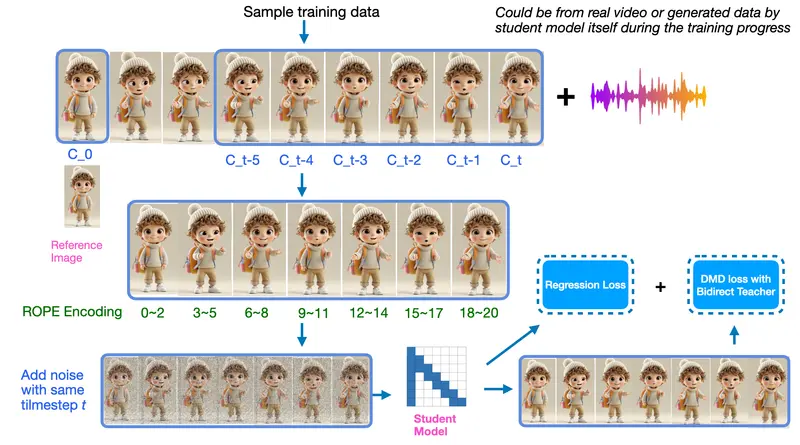
Character.AI 推出 TalkingMachines:音频驱动的实时视频生成模型,打造“FaceTime 风格”AI 视频交互知名 AI 角色平台 Character.AI 发布了一项引人注目的研究成果——TalkingMachines,一个基于扩散模型的新型自回归视频生成系统。该系统仅需一张静态图像和一段语音输入,即可生成...视频模型# Character.AI# TalkingMachines6个月前01720
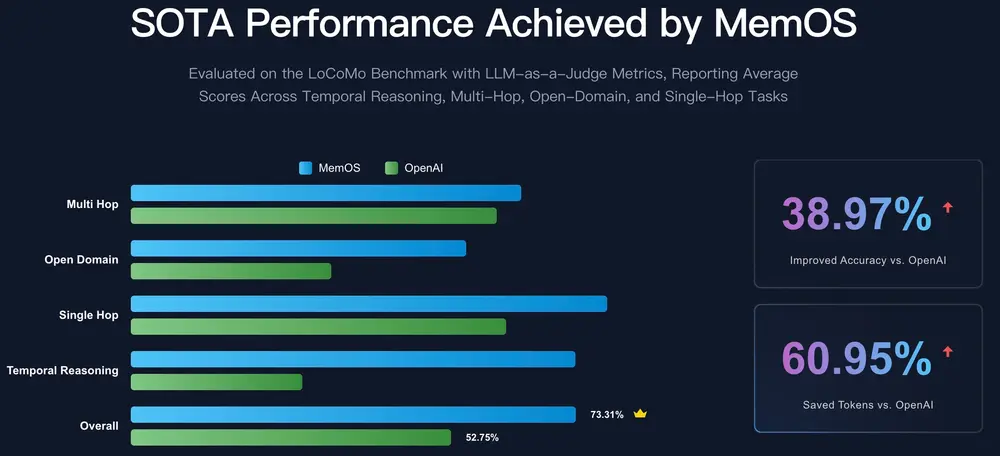
MemOS:为大语言模型设计的长期记忆操作系统MemOS 是由记忆张量科技联合上海交通大学、同济大学、浙江大学、北京大学等多所高校及研究机构联合开源的一项突破性研究成果——专为大语言模型(LLMs)设计的长期记忆操作系统。 项目主页:https...大语言模型# MemOS# 大语言模型6个月前04090
华为正式开源盘古大模型与昇腾推理技术周一,华为宣布一项重大举措:开源其盘古70亿参数(7B)密集模型和720亿参数(72B)Pro MoE混合专家模型,以及基于昇腾平台的高效推理技术。 这一动作被视为华为持续推进大型AI模型研究与产业应...大语言模型# 华为# 盘古大模型6个月前01850