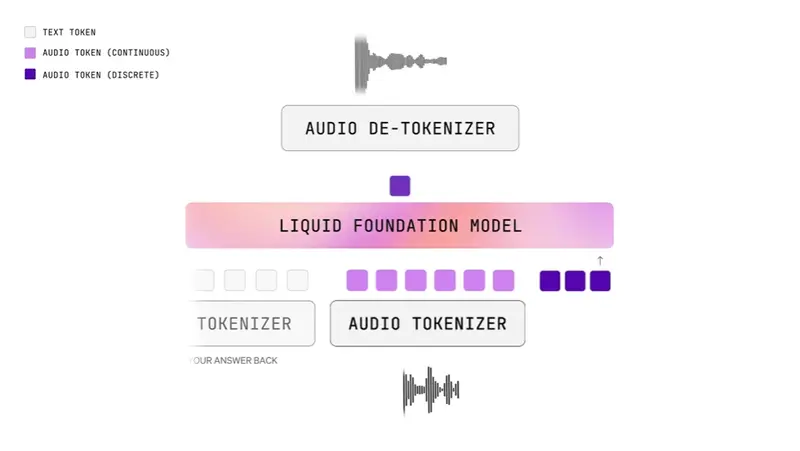
Liquid AI 发布 LFM2-Audio:一个轻量级、端到端的音频-文本基础模型Liquid AI 正式推出 LFM2-Audio-1.5B ——一款专为实时交互设计的端到端多模态基础模型,支持音频与文本的任意输入输出组合。 GitHub:https://github.com/L...语音模型# LFM2-Audio# Liquid AI6个月前01640
Hume AI 发布 Octave 2:更智能、多语言、低延迟的语音合成系统Hume AI 正式推出 Octave 2 ——其下一代文本到语音(TTS)模型的重大升级版本。作为“语音语言模型”(Speech Language Model, SLM)架构的延续,Octave 2...语音模型# EVI 4 mini# Hume AI# Octave 26个月前01120
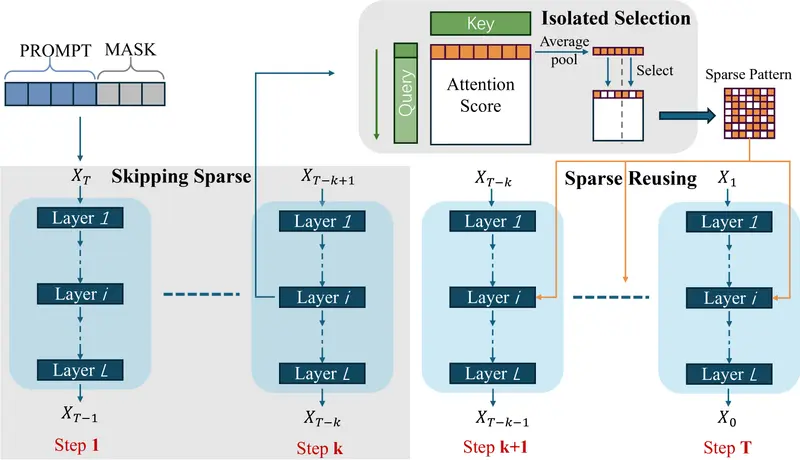
新加坡国立大学等提出 SparseD:让扩散语言模型在长上下文场景高效运行的稀疏注意力新方案扩散语言模型(Diffusion Language Models, DLMs)因其支持并行生成文本的能力,被视为自回归模型(AR)之外的一条重要技术路径。然而,其高昂的推理延迟严重制约了实际应用,尤其...大语言模型# SparseD# 稀疏注意力# 长上下文场景6个月前02640
SLA:清华与伯克利联合提出可训练稀疏线性注意力,加速DiT视频生成在高分辨率、长时序视频生成任务中,扩散变换器(Diffusion Transformer, DiT)已成为主流架构。然而,其核心组件——自注意力机制——面临着一个根本性瓶颈:计算复杂度随序列长度呈平方...视频模型# SLA# 可训练混合注意力机制6个月前01790
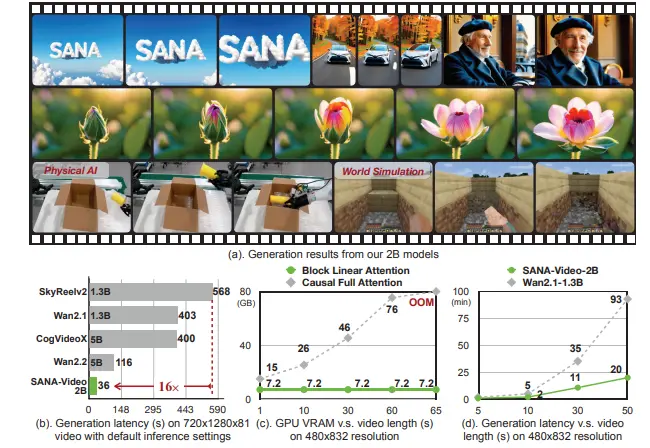
线性注意力 + 恒定内存 KV 缓存!SANA-Video:高效生成分钟级高清视频的新一代文生视频模型在文本到视频(T2V)生成领域,高分辨率、长时长与低延迟三者往往难以兼得。现有大模型虽能生成高质量视频,但动辄数千秒的推理时间与高昂的训练成本严重限制了其落地应用。 为此,由英伟达、香港大学、麻省理工...视频模型# SANA-Video# 文生视频模型6个月前06780
Wan-Alpha:支持透明通道的高质量文生视频模型在视频编辑、虚拟合成、游戏特效和社交媒体创作中,带有透明背景(Alpha 通道)的视频素材具有不可替代的价值——它们可以无缝叠加到任意场景中,无需后期抠像或遮罩处理。 然而,当前主流的文生视频(Tex...视频模型# Wan-Alpha# 文生视频模型6个月前03180
英伟达提出 DC-Gen:用于加速扩散模型的后训练框架,生成速度快 53 倍在文生图领域,高分辨率输出(如 4K)正成为标配。然而,随之而来的计算成本和推理延迟问题日益凸显——以当前领先的 FLUX.1-Krea-12B 模型为例,在英伟达H100 GPU 上生成一张 4K ...图像模型# DC-Gen# 文生图模型# 英伟达6个月前03710
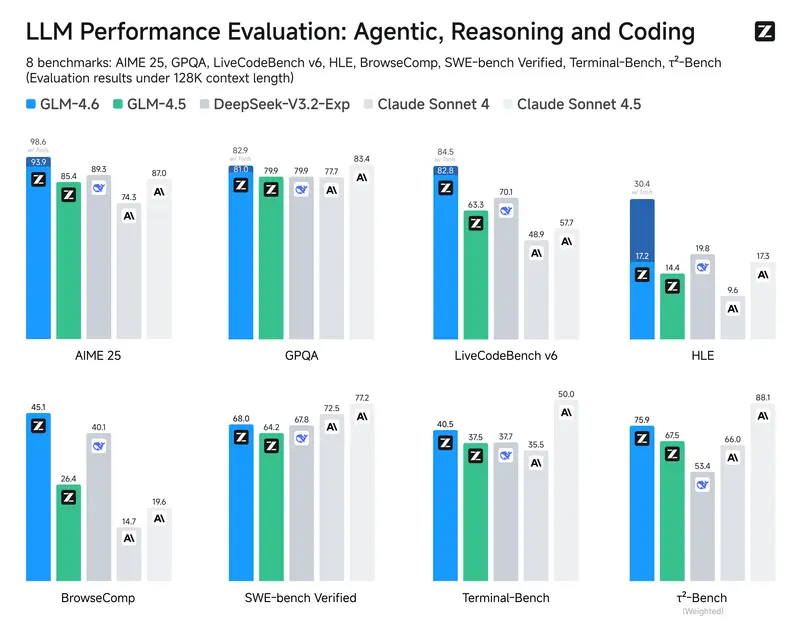
智谱发布 GLM-4.6:200K 上下文、30% 更省,专为编程优化今日,智谱 AI 正式推出其最新旗舰文本模型 GLM-4.6,作为 GLM 系列的最新迭代版本,该模型在推理、编码与智能体能力上实现全面升级,定位为当前国内最强的代码专用大模型。 项目主页:https...大语言模型# GLM-4.6# 智谱6个月前0780
腾讯混元推出 混元3D-Part:让3D模型像乐高一样“可拆解”在AIGC推动内容创作变革的当下,3D生成正成为下一个关键战场。然而,一个长期被忽视的问题是:大多数AI生成的3D模型都是“一体成型”的黑盒结果——无法拆分、难以编辑、不便生产。 腾讯混元推出 Hun...3D模型# Hunyuan3D-Part# 混元3D-Part6个月前01820
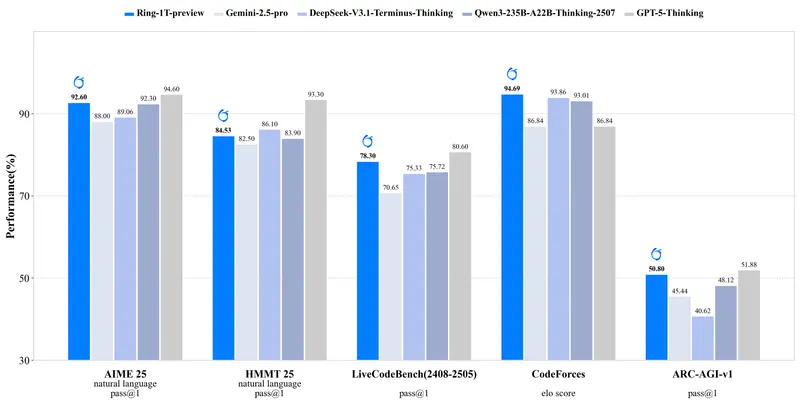
蚂蚁集团发布全球首个开源万亿参数推理大模型 Ring-1T-preview在大模型迈向“深度思考”的关键阶段,蚂蚁集团迈出重要一步:其自研的万亿参数自然语言推理大模型 Ring-1T-preview 正式上线 Hugging Face,成为全球首个开源的万亿参数级推理专用大...大语言模型# Ring-1T-preview# 推理大模型# 蚂蚁集团6个月前01230
Anthropic 发布 Claude Sonnet 4.5:编程能力业界领先,可自主开发生产级应用,定价不变周一,Anthropic 正式发布其最新前沿模型 Claude Sonnet 4.5,宣称在编程任务中实现“生产级”输出能力,标志着其在软件工程场景下的可靠性迈上新台阶。 该模型即日起通过 Claud...大语言模型# Anthropic# Claude Sonnet 4.5# 编程模型6个月前01060
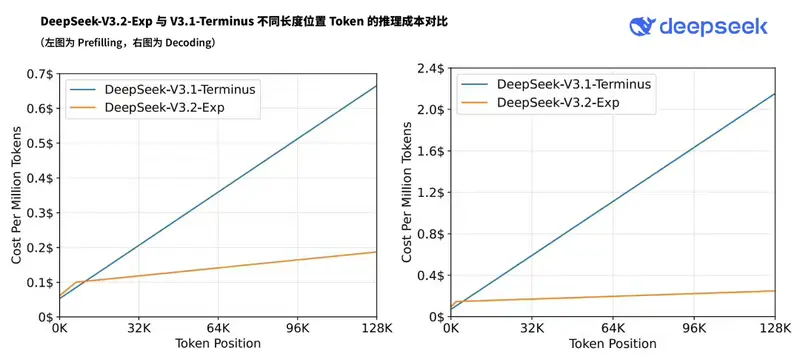
DeepSeek 发布DeepSeek-V3.2-Exp:首次引入细粒度稀疏注意力,API 成本直降 50%+在国庆节假期前夕,DeepSeek 正式推出 DeepSeek-V3.2-Exp ——一个面向未来架构演进的实验性(Experimental)版本。该模型并非最终发布版,而是通向新一代高效架构的关键中...大语言模型# DeepSeek# DeepSeek-V3.2-Exp6个月前02010