MoLingo:通过语义对齐潜在空间实现高保真文本到动作生成在虚拟角色动画、VR/AR交互和智能体控制中,如何让AI根据一句自然语言(如“一个人正在跳华尔兹”)生成逼真、连贯且语义一致的人体动作,一直是核心挑战。传统方法要么动作生硬,要么与文本描述脱节,难以兼...视频模型# MoLingo# 动作生成4个月前01160
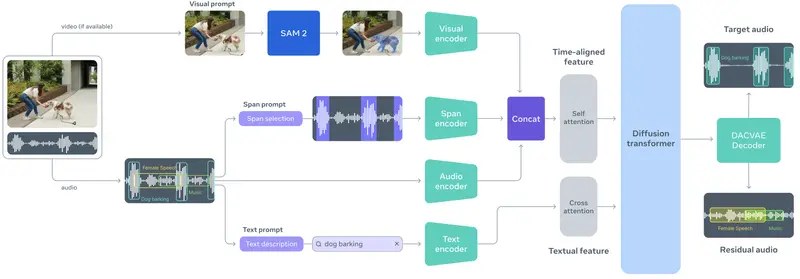
Meta发布SAM Audio:首个支持文本、视觉、时间提示的统一音频分离模型在图像领域,Meta 的 Segment Anything Model (SAM) 通过“任意分割”能力,彻底改变了计算机视觉的交互范式。如今,这一理念正式延伸至音频领域。 Meta 正式发布 SAM...语音模型# Meta# SAM Audio# 音频分离模型4个月前01000
清华与微软推出 TRELLIS.2:单图生成带透明材质的 3D 资产由清华大学、微软研究院与中国科学技术大学联合推出,TRELLIS.2 是一个参数量达 40 亿 的先进 3D 生成模型,专为从单张图像生成带完整 PBR 材质的高分辨率 3D 资产而设计。 项目主页...3D模型# 3D模型# TRELLIS.24个月前0890
HY-World 1.5:腾讯混元实时交互式 3D 建模框架,24FPS + 几何一致性双突腾讯混元团队推出的HY-World 1.5,凭借核心模块WorldPlay流式视频扩散模型,成功打破了现有3D世界生成模型“实时交互”与“长期几何一致性”不可兼得的技术瓶颈,实现了24 FPS的实时流...3D模型# HY-World 1.5# 腾讯4个月前01160
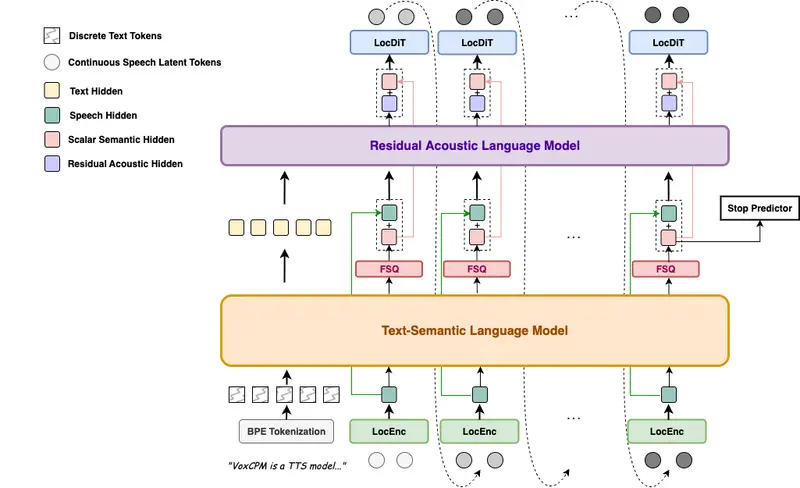
面壁智能发布 VoxCPM1.5:6.25Hz 标记率降低计算开销,支持高质量声音克隆2025 年 12 月 5 日,面壁智能正式发布 VoxCPM1.5 模型权重。作为 VoxCPM 系列的重大升级版本,它在保留上下文感知语音生成与零样本声音克隆能力的基础上,通过两项关键技术改进,显...语音模型# VoxCPM1.5# 面壁智能4个月前0310
Dolphin-v2:字节跳动发布支持21类元素的通用文档解析模型在办公自动化、知识管理与智能体工作流中,将非结构化文档转化为结构化数据是关键第一步。然而,现实中的文档来源复杂:既有干净的 PDF、Word,也有手机拍摄的带畸变、阴影、模糊的纸质文件。现有解析模型往...多模态模型# Dolphin-v2# 字节跳动# 文档解析模型4个月前01630
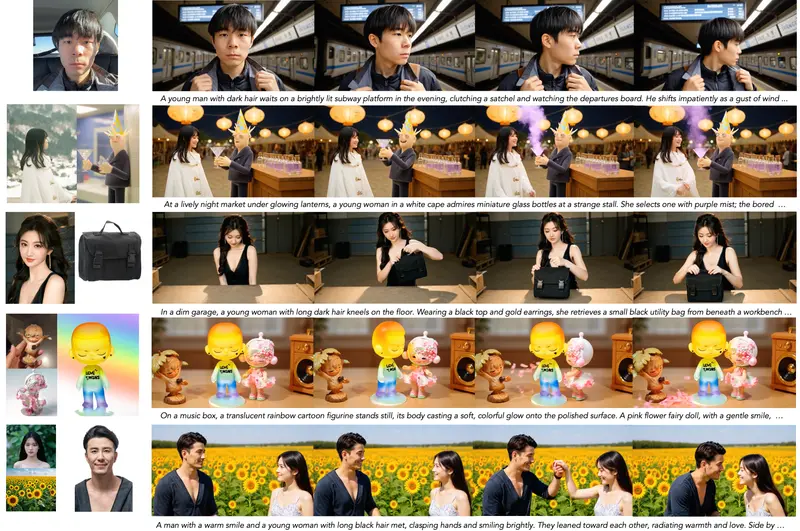
智谱AI发布 Kaleido:通过多参考图像生成主体一致视频的 S2V 框架在主体到视频(Subject-to-Video, S2V)生成任务中,目标是根据用户提供的多张目标主体参考图像和文本提示,合成一段主体身份一致、动作自然、背景可控的视频。尽管近期 S2V 模型取得进展...视频模型# Kaleido# 智谱AI4个月前0720
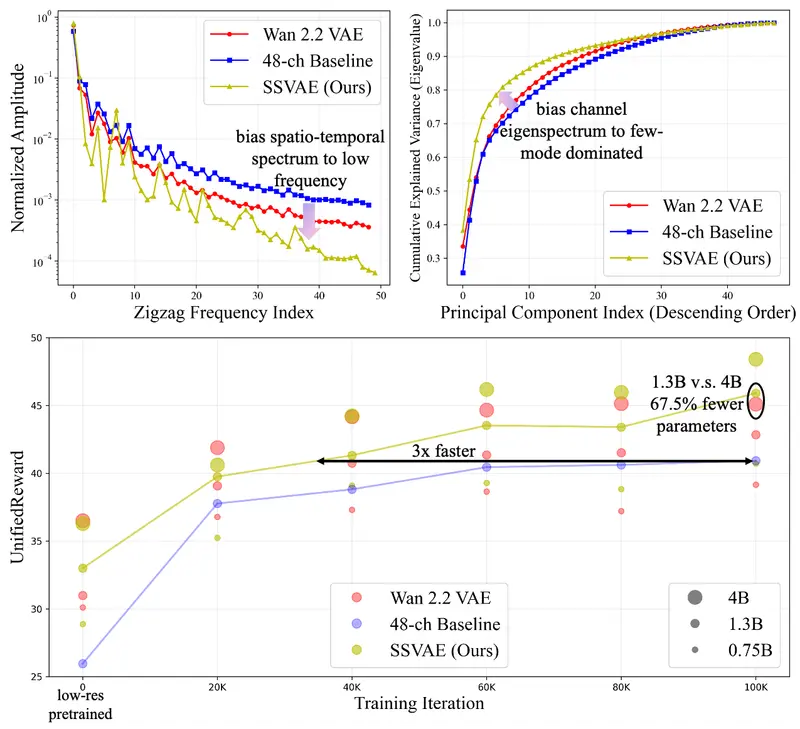
智谱AI提出 SSVAE:通过谱结构优化提升视频VAE“可扩散性”的新方法在基于扩散模型的视频生成系统中,视频变分自编码器(VAE) 扮演着关键角色:它将像素空间视频压缩到潜在空间,供扩散模型高效训练。然而,现有视频 VAE 的设计往往过度聚焦于重建保真度,却忽视了一个更根...视频模型# SSVAE# 智谱AI4个月前0210
智谱AI发布面向生产级角色动画的生成框架 SCAIL:通过3D一致姿态表征实现影棚级角色动画高质量角色动画长期以来依赖昂贵的动作捕捉设备、繁琐的手动绑定和大量人力修型。尽管近年视频生成模型取得进展,但在复杂动作、风格化角色、多角色交互等场景下,现有方法仍普遍存在结构失真、时间不连贯、身份泄漏...视频模型# SCAIL# 智谱AI# 角色动画4个月前0910
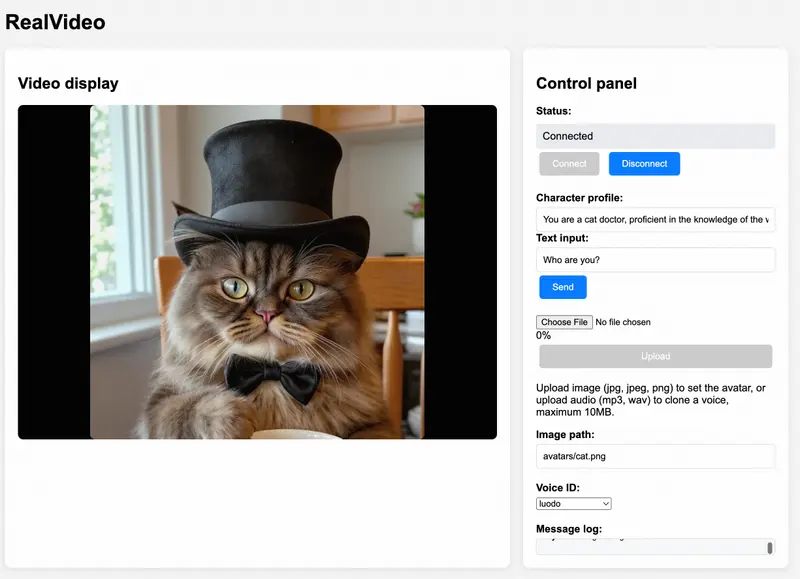
智谱AI开源 RealVideo:基于自回归扩散的实时流式对话视频系统随着多模态生成技术的发展,用户对虚拟角色的期待已从“能说话”升级为“能自然表达、实时互动、持续存在”。为此,智谱AI推出了 RealVideo —— 一个端到端实时流式视频对话系统,能够将文本对话实时...视频模型# RealVideo# 数字人# 智谱AI4个月前01970
MotionEdit:首个专注动作编辑的图像生成基准与训练框架当前主流的图像编辑模型在处理静态属性(如颜色、纹理、物体替换)时已相当成熟,但在修改图像中主体的动作、姿势或交互行为时仍面临显著挑战。例如,让一个人从“站立”变为“坐下”,或让其“拿起桌上的杯子”,现...图像模型# MotionEdit# 图像编辑4个月前0780
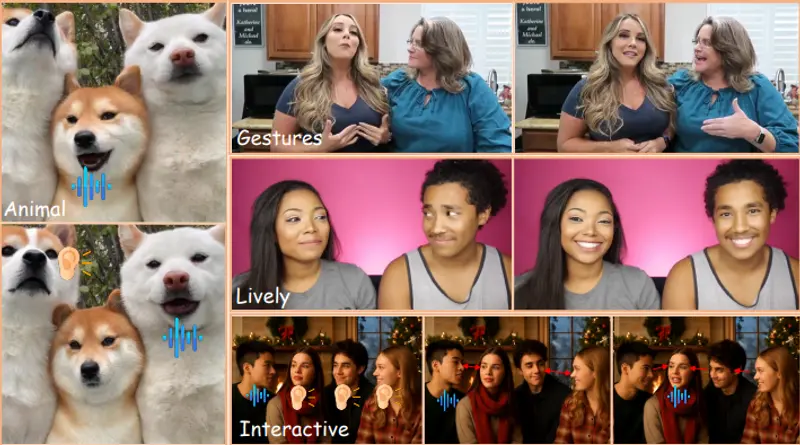
AnyTalker:用单人数据生成自然互动的多人对话视频多人对话视频的自动生成,长期以来受限于两个关键难题:一是高质量多人视频数据极难获取,二是多个角色之间的互动行为难以建模。为解决这些问题,来自香港科技大学、Video Rebirth、浙江大学和北京交通...视频模型# AnyTalker4个月前0240