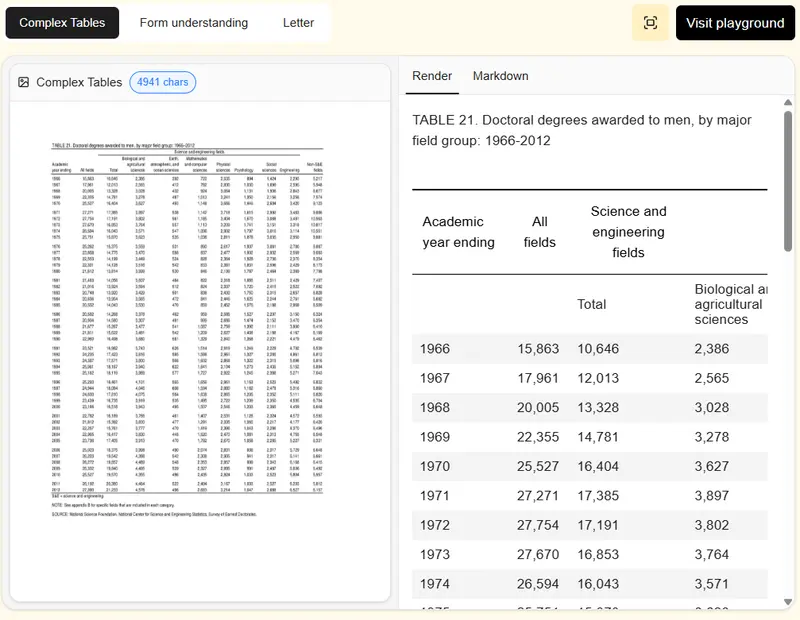
Mistral OCR 3 发布:手写、表格、低质量扫描件识别全面升级Mistral AI 正式推出 Mistral OCR 3,其在复杂文档场景下的识别准确率显著超越前代模型与主流竞品。该模型专注于真实业务环境中的多样化文档——从手写批注、低质量扫描件到多层级表格...多模态模型# Mistral OCR 34个月前0340
Grok Voice Agent API 上线:支持多语言、实时工具调用与低延迟语音交互xAI 正式推出 Grok Voice Agent API,向开发者开放其在 Grok 移动应用及特斯拉车载系统中使用的语音交互技术。该 API 支持构建能实时对话、调用工具、搜索网络并流利使用数十种...语音模型# Grok Voice Agent4个月前0330
艾伦AI研究所推出 Olmo 3.1:更强的 32B 开源聊天与推理模型艾伦人工智能研究所(AI2)发布了 Olmo 3.1,这是 Olmo 3 系列的最新迭代。此次更新包含两个 32B 参数的新模型检查点,以及多个 7B 规模的强化学习变体,进一步推动了高性能与全开源的...大语言模型# Olmo 3.14个月前01260
FunctionGemma:谷歌发布 2.7 亿参数边缘函数调用模型,让设备“听懂即执行”在 Gemini 3 引发广泛关注的同时,谷歌悄然推出了一款面向边缘设备的专用小模型——FunctionGemma。它不是另一个聊天机器人,而是一个能在手机、浏览器或 IoT 设备上本地运行的“行动引...大语言模型# FunctionGemma# 谷歌# 边缘函数调用模型4个月前0860
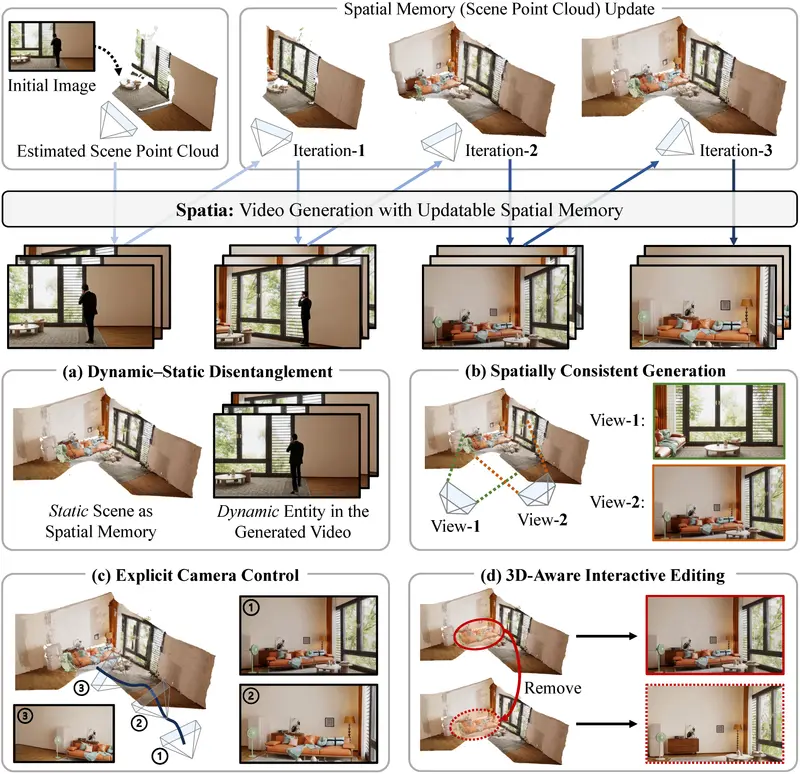
Spatia:基于可更新空间记忆的长期一致视频生成框架传统视频生成模型在生成长视频时,常因高维时空信号的复杂性而难以维持长期的空间与时间一致性——场景结构漂移、物体位置突变、相机运动不连贯等问题普遍存在。 项目主页:https://zhaojingjin...视频模型# Spatia# 视频生成4个月前0330
Generative Refocusing:基于单张输入图像的生成式重聚焦方法Generative Refocusing 是一种基于单张输入图像的生成式重聚焦方法,能够将任意照片转化为一个“虚拟相机”,在拍摄后灵活调整焦点位置、焦外虚化强度、光圈形状等光学属性。该方法不仅支持从...图像模型# Generative Refocusing4个月前01080
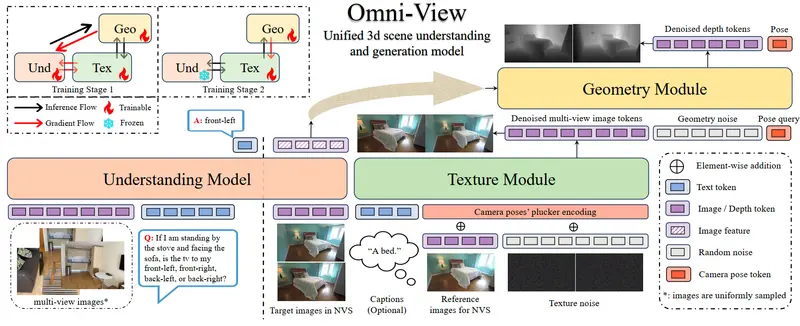
Omni-View:通过生成任务增强3D场景理解的统一模型北京大学、阿里巴巴国际数字商业集团、中国科学院自动化研究所与 TeleAI 联合提出 Omni-View —— 一个面向多视角图像输入的统一3D场景理解与生成模型。该工作首次在端到端框架中系统性验证了...多模态模型# Omni-View4个月前0290
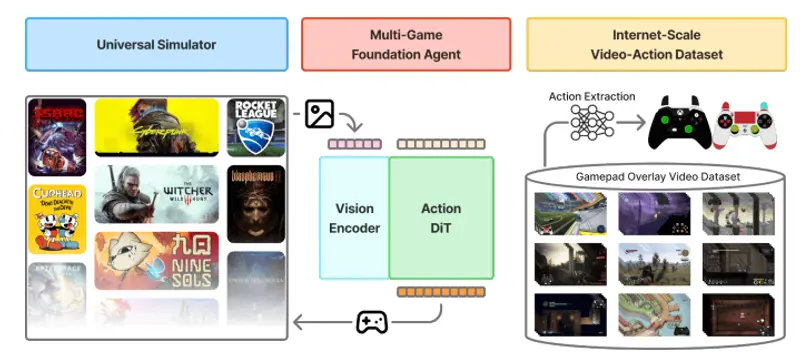
英伟达推出NitroGen:基于人类游戏视频的通用视觉-动作基础模型NitroGen 是由英伟达开发的开放性具身智能基础模型(foundation model for embodied agents),旨在通过观察人类玩家的游戏视频,直接学习从原始画面到手柄动作的映射...视频模型# NitroGen# 英伟达4个月前0860
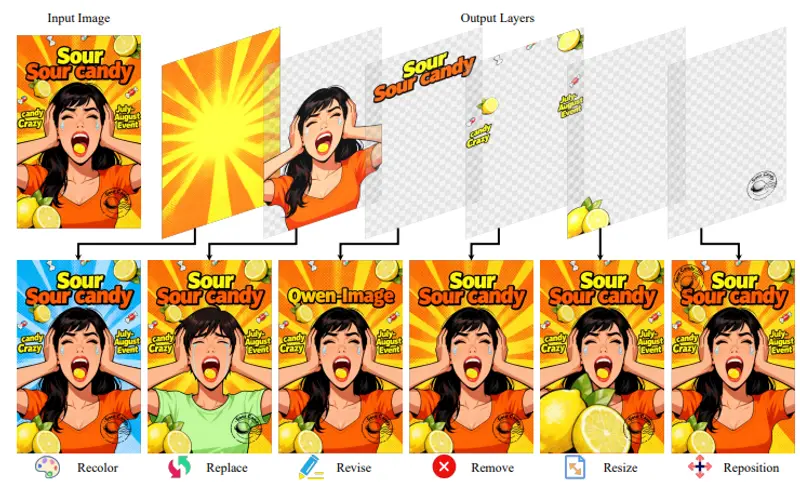
港科大与阿里推出Qwen-Image-Layered:将单图分解为可编辑RGBA图层,实现像素级精准编辑在传统图像编辑中,若想修改照片中的某个物体(如移动人物、更换背景、调整颜色),往往需要复杂的抠图、蒙版或手动重绘——操作繁琐,且容易破坏整体一致性。 由香港科技大学(广州)、阿里巴巴与香港科技大学联合...图像模型# Qwen-Image-Layered# RGBA图层# 编辑模型4个月前01890
FlashPortrait:端到端生成无限长度肖像动画,6倍加速且身份一致在肖像动画(Portrait Animation)任务中,身份一致性与推理效率是两大长期瓶颈。现有扩散模型即便能生成逼真短片,也常在长序列中出现身份漂移、颜色偏移或动作断裂,且生成速度慢,难以用于实际...视频模型# FlashPortrait# 肖像动画4个月前0990
美团 LongCat 发布统一音频驱动视频模型LongCat-Video-Avatar:支持长视频、多模态输入与多人物动画音频驱动的人类视频合成(Audio-Driven Talking Head)近年来在唇形同步和画面逼真度上取得显著进展。但生成长时间、高动态、身份一致的视频仍是行业难题:现有方法要么在长序列中出现身份...视频模型# LongCat-Video-Avatar# 美团4个月前0590
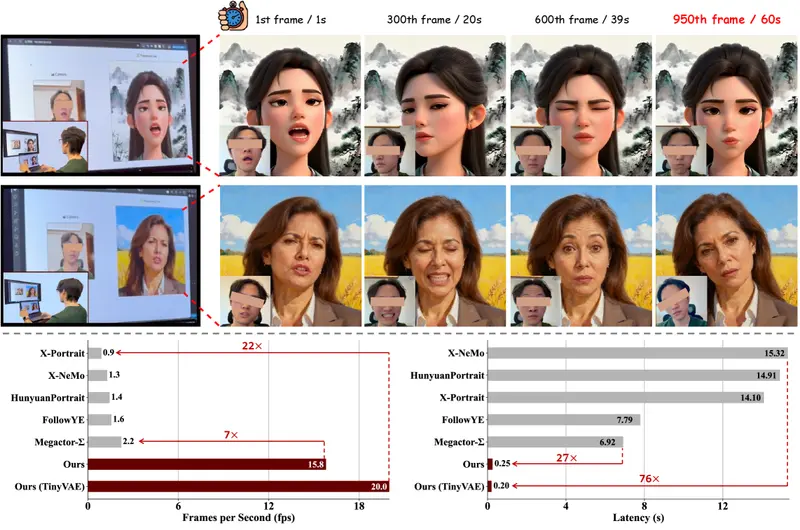
PersonaLive:基于扩散模型的实时肖像动画系统,延迟仅0.25秒在数字人、虚拟主播和直播场景中,高质量、低延迟、身份一致的肖像动画是核心需求。然而,主流扩散模型虽能生成逼真画面,却因高计算成本与多步去噪,难以满足实时交互要求——生成一段3秒视频往往需要数十秒,远不...视频模型# PersonaLive# 肖像动画4个月前0230