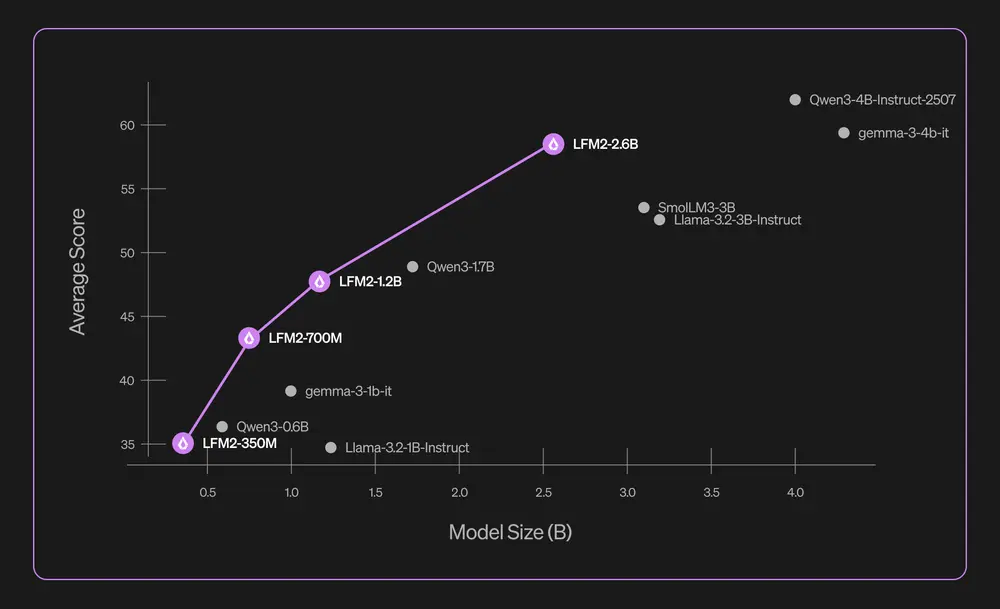
LFM2-2.6B发布:小参数,高性能,重新定义语言模型效率在大模型“军备竞赛”愈演愈烈的今天,参数规模是否仍是衡量能力的唯一标准? Liquid AI 最新推出的 LFM2-2.6B 给出了一个有力的回答: 更优的架构设计,可以让更小的模型,在关键任务上超越...大语言模型# LFM2-2.6B4个月前01490
SongPrep:腾讯提出自动化歌曲预处理方案,破解AIGC歌曲生成的数据难题在AIGC的众多分支中,歌曲生成因兼具“音乐旋律”“歌词文本”“结构韵律”的多维度创作需求,一直是技术难点。尽管互联网上有海量歌曲资源,但要将这些原始音频转化为可训练AIGC模型的“结构化数据”,传统...语音模型# SongPrep# 腾讯# 音乐模型4个月前01090
Qwen3Guard发布:阿里通义实验室推出首款安全护栏模型阿里通义实验室 Qwen 项目组正式推出 Qwen3Guard —— Qwen 家族中首款专为内容安全设计的护栏模型(Safety Guardrail Model)。 该模型基于强大的 Qwen3 架...大语言模型# Qwen3Guard# 安全护栏模型4个月前04940
Lynx:字节跳动提出的单图驱动个性化视频生成方案,实现高保真身份保留在内容创作、虚拟社交等场景中,“基于单张图像生成个性化视频”是重要需求——比如用一张自拍生成动态表情视频,或让历史人物照片“动起来”讲述故事。但这类任务长期面临核心挑战:如何在保证视频自然流畅的同时...视频模型# Lynx# 个性化视频生成# 字节跳动4个月前02060
SpatialGen:布局引导的多模态扩散模型,高效生成高保真3D室内场景在室内设计、VR/AR开发、机器人训练等领域,“高保真3D室内场景模型”是核心基础——设计师需要用它预览方案效果,VR设备需要靠它构建沉浸式环境,机器人则依赖它模拟真实导航场景。但长期以来,3D室内场...3D模型# 3D室内场景# SpatialGen4个月前01120
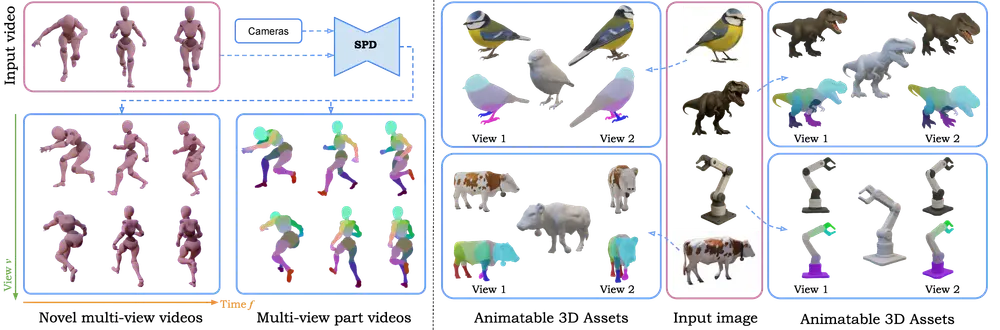
Stable Part Diffusion 4D:单目输入驱动多视图RGB与运动部件视频生成在动画制作、AR/VR开发、机器人运动规划等领域,“从单视角视觉信息生成多视图内容+结构化运动部件”是长期存在的技术难点——传统方法要么依赖多设备采集,要么难以保证运动部件在时间与空间上的一致性。 项...3D模型# SP4D# Stable Part Diffusion 4D4个月前0790
字节跳动提出OmniInsert:无需遮罩,任意对象都能自然插入视频在影视后期、广告制作乃至虚拟内容创作中,“将一个新角色或物体自然地加入已有视频”是一项高频需求。传统方法依赖精确的遮罩标注、关键帧追踪和复杂的合成流程,成本高、耗时长。 近期,基于扩散模型的技术为这一...视频模型# OmniInsert# 字节跳动# 视频编辑4个月前01540
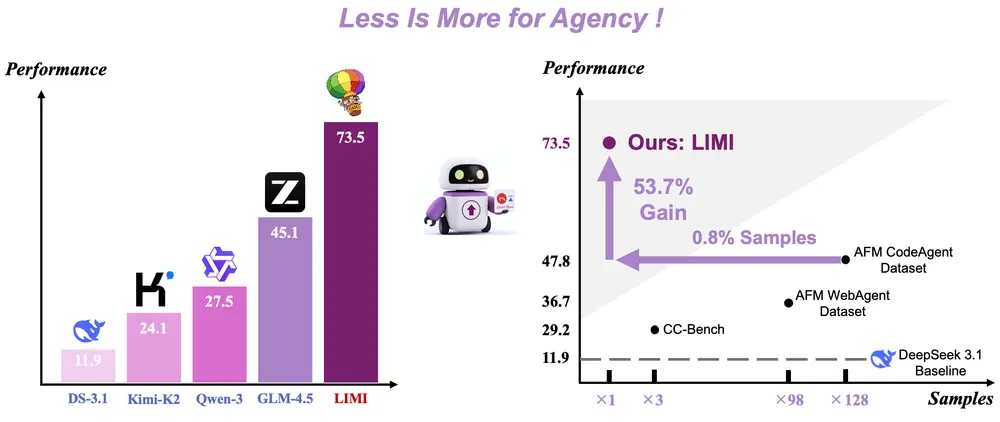
LIMI :少即是多,78个样本如何训练出高效AI智能体由上海交通大学、上海创智学院、香港理工大学、中国科学技术大学与GAIR联合开展的一项研究,最近提出了一个名为 LIMI 的新方法——全称为 Less is More for Intelligent A...大语言模型# LIMI# 智能体4个月前01720
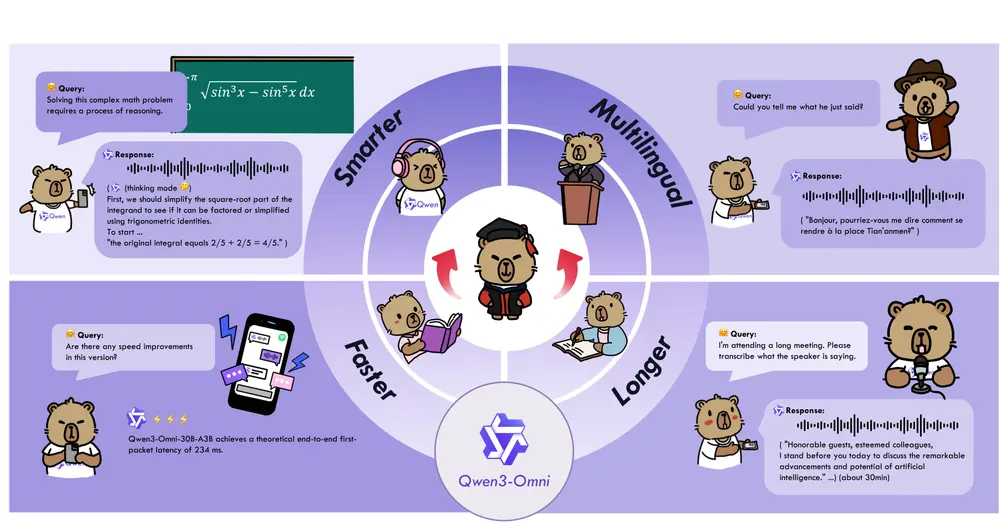
阿里通义实验室推出Qwen3-Omni:支持文本、语音、图像、视频的全模态大模型通义实验室正式推出 Qwen3-Omni——一款统一处理多模态输入并支持流式文本与语音输出的大语言模型。该模型已在 Qwen API 平台上线,开发者可通过接口体验其在音频对话、跨模态理解与指令执行方...多模态模型# Qwen3-Omni# 通义实验室4个月前01650
Qwen3-TTS-Flash 发布:支持多音色、多语言与多方言的语音合成模型通义实验室近日推出 Qwen3-TTS-Flash,一款面向多场景应用的高性能文本转语音(TTS)模型。该模型现已通过 Qwen API 开放访问,支持自然、流畅且富有表现力的语音生成。 API:ht...语音模型# Qwen3-TTS-Flash# 语音合成模型4个月前02340
阿里通义实验室Qwen项目组推出图像编辑模型 Qwen-Image-Edit新版本 Qwen-Image-Edit-2509:支持多图输入与更强一致性通义实验室发布 Qwen-Image-Edit-2509,作为 Qwen-Image-Edit 系列的月度迭代版本。该模型已在 Qwen Chat 平台上线,用户可通过“图像编辑”功能直接体验。 Hu...图像模型# Qwen-Image-Edit# Qwen-Image-Edit-2509# 图像编辑模型4个月前05270
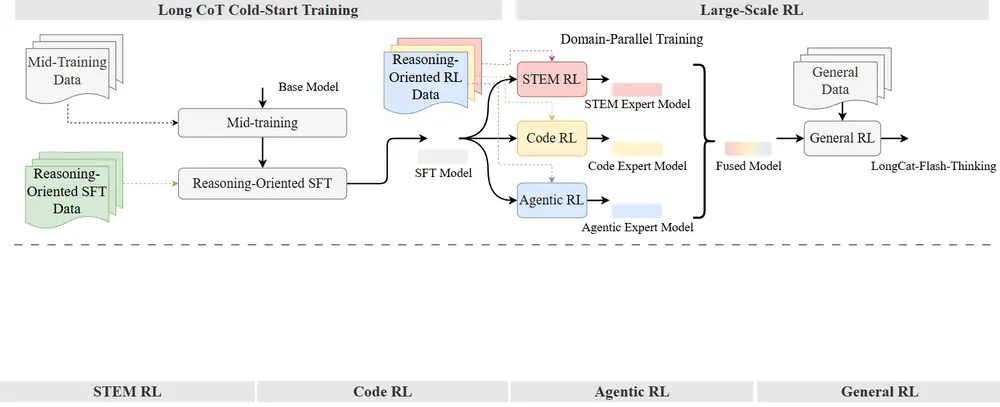
美团 LongCat 团队发布 LongCat-Flash-Thinking:具备形式化与智能体推理能力的新一代高效推理模型美团 LongCat 团队正式推出 LongCat-Flash-Thinking——一款专注于高复杂度任务推理的大型语言模型(LRM)。该模型在保持前代 LongCat-Flash-Chat 高效响应...大语言模型# LongCat-Flash-Thinking# 推理模型# 美团4个月前01570