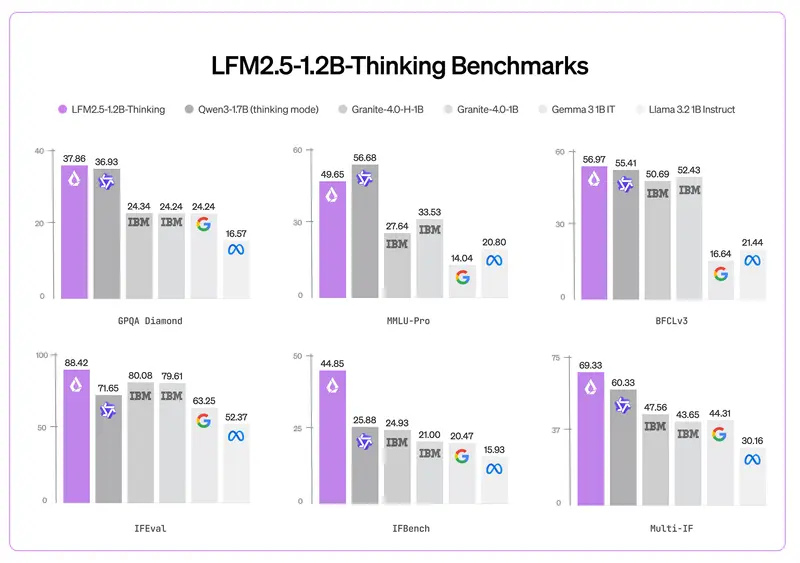
Liquid AI 发布 LFM2.5-1.2B-Thinking:900MB 内存即可运行的设备端推理模型两年前,复杂的推理任务还需要依赖数据中心。如今,Liquid AI 发布的 LFM2.5-1.2B-Thinking 模型,让这一切在任何拥有 900MB 可用内存的手机上成为可能。 地址:https...大语言模型# LFM2.5-1.2B-Thinking# Liquid AI3个月前0440
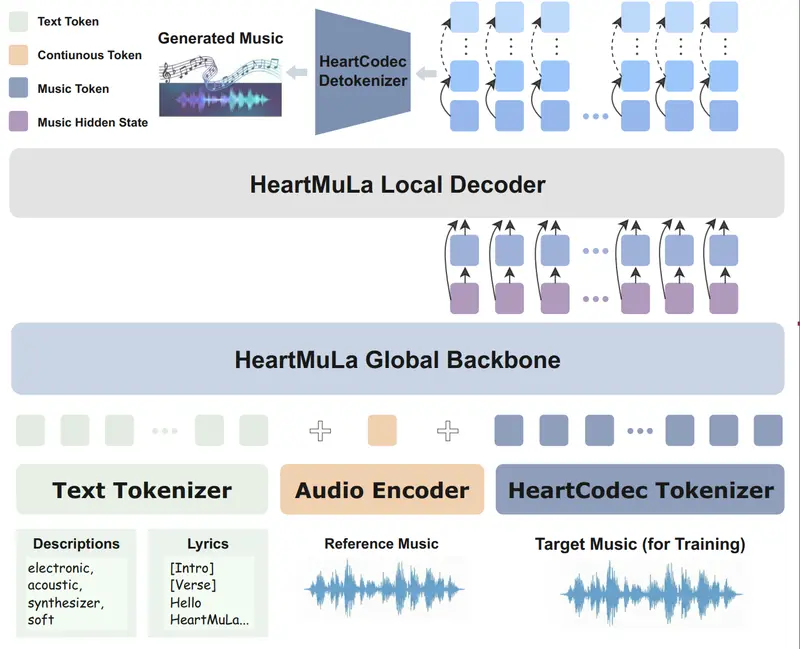
HeartMuLa:开源音乐基础模型家族,支持歌词识别、高保真生成与细粒度控制如果你曾幻想过——只需输入一段歌词和一句描述(如“一首欢快的流行歌,吉他伴奏,副歌要有电子音效”),AI 就能生成一首结构完整、音质高保真的歌曲——那么 HeartMuLa 项目正将这一愿景变为现实...语音模型# HeartMuLa# 音乐模型3个月前02300
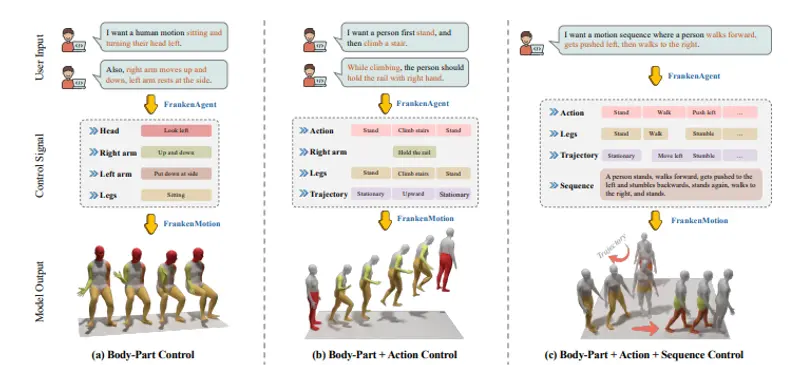
FrankenMotion:首个支持身体部位级精细控制的文本驱动人体动作生成框架在虚拟角色、游戏动画或人机交互中,如何让 AI 根据自然语言描述生成逼真且可控的人体动作,一直是计算机图形学与 AI 领域的挑战。现有方法大多只能生成整体动作(如“走路”“跳舞”),难以对手臂、腿部...3D模型# FrankenMotion# 人体动作3个月前0910
谷歌开源新翻译模型TranslateGemma:4B 到 27B 全覆盖,支持 55 种语言谷歌发布 TranslateGemma —— 一套基于 Gemma 3 构建的全新开源翻译模型家族,包含 4B、12B 和 27B 三种参数规模,支持 55 种语言 的高质量互译。更重要的是,它在效率...大语言模型# TranslateGemma# 翻译模型# 谷歌3个月前01390
黑森林实验室发布 FLUX.2 [klein]:统一生成与编辑的最快开源模型黑森林实验室(Black Forest Labs)今日正式推出 FLUX.2 [klein] 模型系列——这是目前速度最快、体积最小的高质量图像生成模型家族。它将文生图、图像编辑与多参考图生成统一于单...图像模型# FLUX.2 [klein]# 黑森林实验室3个月前02210
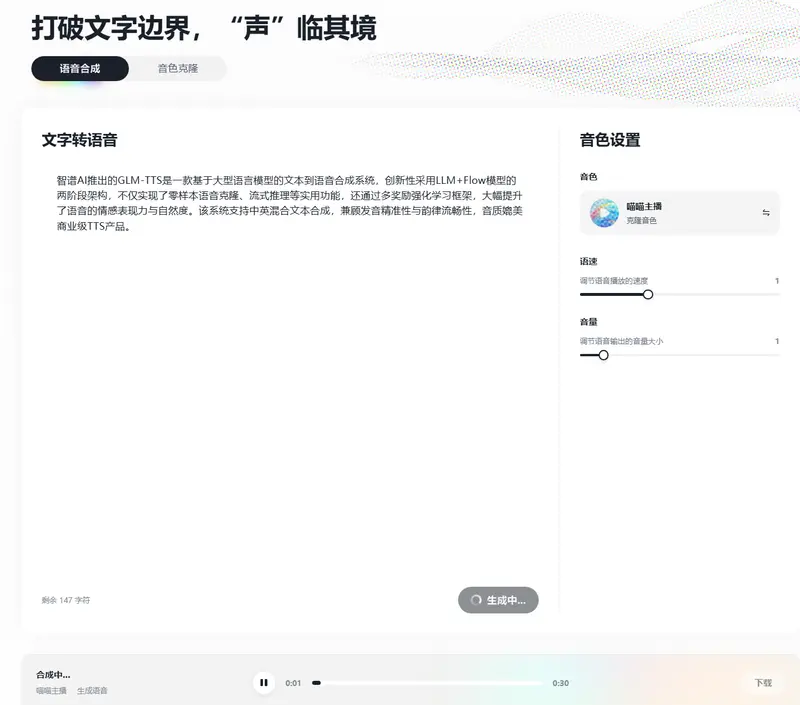
智谱AI开源GLM-TTS:LLM驱动的高质量TTS系统,支持零样本克隆与情感增强智谱AI推出的GLM-TTS是一款基于大语言模型的文本到语音合成系统,创新性采用LLM+Flow模型的两阶段架构,不仅实现了零样本语音克隆、流式推理等实用功能,还通过多奖励强化学习框架,大幅提升了语音...语音模型# GLM-TTS# 智谱AI3个月前0730
智谱AI开源GLM-Image:自回归+扩散混合架构,攻克知识密集型图像生成难题智谱AI正式推出GLM-Image——业界首个开源的工业级离散自回归图像生成模型。这款模型创新性地采用自回归模块+扩散解码器的混合架构,既继承了自回归模型对复杂语义的精准理解能力,又兼具扩散模型高保真...图像模型# GLM-Image# 智谱AI3个月前01900
腾讯优图实验室推出 Youtu-LLM:持 128K 上下文、本地运行,专为端侧 AI 设计在大模型普遍走向百亿、千亿参数的今天,腾讯优图实验室推出了一款仅 1.96B 参数的轻量级语言模型——Youtu-LLM。它不追求规模堆砌,而是以 STEM 能力与原生智能体(Agentic)能力为核...多模态模型# Youtu-LLM# 腾讯优图实验室3个月前0480
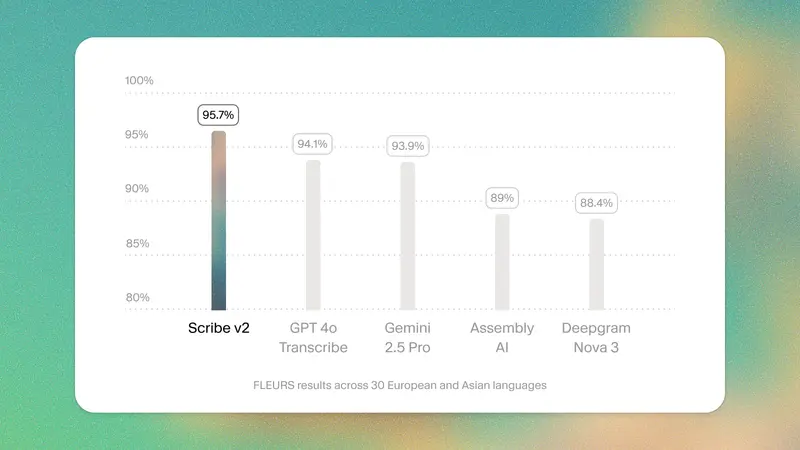
ElevenLabs 推出 Scribe v2:支持 90+ 语言的高精度批量转录模型ElevenLabs 正式发布 Scribe v2——一款专为大规模音视频内容处理设计的新一代语音转文字模型。与主打低延迟的 Scribe v2 Realtime 不同,Scribe v2 面向批量转...语音模型# ElevenLabs# Scribe v23个月前02290
阿里开源 Qwen3-VL 多模态检索模型:Embedding + Reranker 两阶段提升跨模态精度在多模态 AI 应用日益普及的今天,如何高效检索混合了文本、图像、截图甚至视频的内容,仍是技术难点。传统方案往往依赖多个专用模型,导致系统复杂、语义割裂。 官方说明:https://qwen.ai/b...多模态模型# Qwen3-VL-Embedding# Qwen3-VL-Reranker3个月前0430
UniVideo:滑铁卢大学与快手推出统一视频生成与编辑模型,支持理解、生成、编辑一体化长久以来,视频 AI 能力被割裂为多个独立任务: 理解:靠视觉语言模型(如 Qwen-VL) 生成:依赖扩散模型(如 Sora、HunyuanVideo) 编辑:需专门的编辑网络或掩码引导 这种碎片化...视频模型# UniVideo# 视频生成# 视频编辑3个月前0260
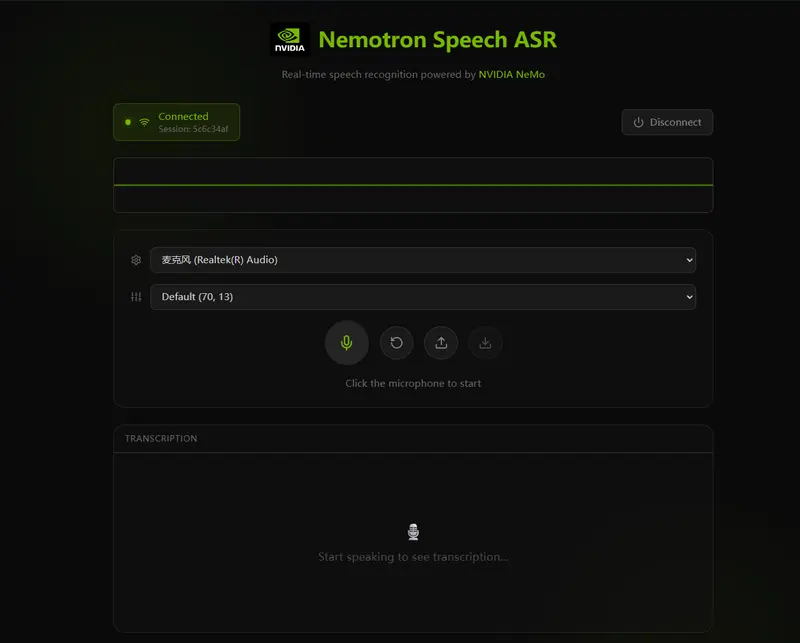
Nemotron-Speech-Streaming-En-0.6B:面向低延迟与高吞吐的流式语音识别模型英伟达推出的 Nemotron-Speech-Streaming-En-0.6B 是 Nemotron Speech 系列中的首个统一语音识别(ASR)模型,专为实时英语转录场景设计。它同时支持低延迟...语音模型# Nemotron-Speech-Streaming-En-0.6B# 英伟达# 语音识别3个月前0290

![黑森林实验室发布 FLUX.2 [klein]:统一生成与编辑的最快开源模型](https://pic.sd114.wiki/wp-content/uploads/2026/01/1768500030-1768500030-FLUX.2-klein-2.webp~tplv-o4t1hxlaqv-image.image)