
在虚拟角色、游戏动画或人机交互中,如何让 AI 根据自然语言描述生成逼真且可控的人体动作,一直是计算机图形学与 AI 领域的挑战。现有方法大多只能生成整体动作(如“走路”“跳舞”),难以对手臂、腿部、头部等部位进行独立控制。
来自图宾根大学与马克斯·普朗克计算机科学研究所的研究团队,近日提出了 FrankenMotion——一个首个支持原子级、身体部位级运动控制的文本到动作生成框架。其核心突破在于:不仅能理解“一个人在爬楼梯”,还能精确控制“右手扶栏杆、左臂下垂、头部向左转”。
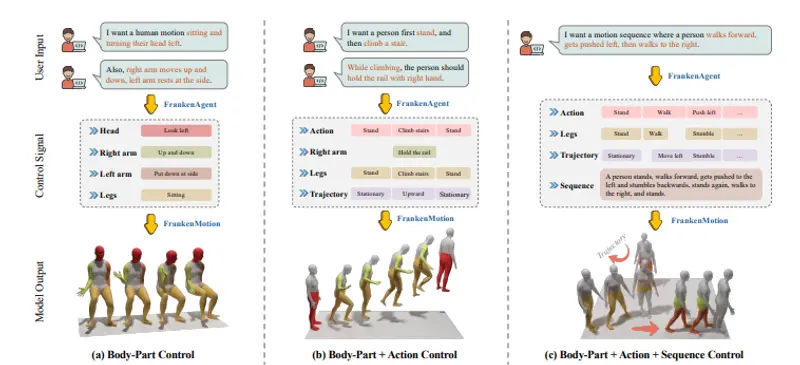
为什么需要部位级控制?
传统动作生成模型依赖序列级或动作级标签(如“行走”“跳跃”),缺乏对身体各部位运动的细粒度描述。这导致:
- 无法组合局部动作(如“边走路边挥手”)
- 难以生成训练数据中未出现的复杂行为
- 用户对生成结果的控制力有限
而 FrankenMotion 通过引入时间感知的部位级文本标注,首次实现了对每个身体部位的独立、异步、语义明确的控制。
技术亮点
1. FrankenStein 数据集:用 LLM 自动生成细粒度标注
研究团队利用大语言模型(如 DeepSeek-R1)作为“FrankenAgent”,对现有动作捕捉数据进行自动注释,生成包含以下层级的文本描述:
- 序列级:整体行为(如“从站立到爬楼梯”)
- 动作级:原子动作(如“迈左脚”“扶栏杆”)
- 部位级:具体身体部位的运动(如“右臂屈肘”“头部左转”)
该数据集共 39 小时,经人工评估,LLM 生成的注释准确率达 93.08%。
2. 层次化扩散模型:三重条件引导生成
FrankenMotion 基于扩散模型架构,通过三层嵌入联合引导动作生成:
- Sequence-level:整体意图
- Action-level:原子动作序列
- Part-level:各身体部位的独立指令
例如,输入提示:
“站立 → 向前走 → 头部左转 → 爬楼梯(右手扶栏杆,左臂自然下垂)→ 被向左推 → 向右走”
模型可逐帧生成符合物理规律且语义一致的三维动作序列。
3. 支持稀疏输入与零样本组合
即使只提供部分部位的描述(如仅指定“手臂动作”),模型也能合理补全其他部位。更重要的是,它能组合训练中未见过的动作,展现出强大的泛化能力。
实验结果
| 指标 | FrankenMotion | 基线模型 |
|---|---|---|
| 语义正确性(部位/动作/序列) | ✅ 全面领先 | ❌ 仅整体动作准确 |
| 动作真实性(FID 越低越好) | 更低 FID | 较高 FID |
| 用户控制灵活性 | 支持任意部位组合 | 仅支持预定义动作 |
应用前景
- 游戏与动画:快速生成角色复杂动作,减少动捕成本
- 虚拟现实:为 VR 角色赋予自然、可定制的行为
- 人机交互:让机器人或虚拟助手执行精细指令(如“用右手递杯子,同时点头”)
- 康复训练:生成标准动作序列用于运动分析或教学
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











