在生成式 3D 模型快速发展的背景下,绑定(Rigging)——即为静态 3D 模型添加骨骼与蒙皮权重以支持动画——已成为自动化流程中的关键瓶颈。现有方法通常将蒙皮(Skinning)视为一个高维、不适定的连续回归问题,不仅优化效率低,还常与骨骼生成过程脱节,导致结果缺乏语义一致性与动画鲁棒性。
针对这一根本挑战,清华大学与 VAST 的研究团队提出了一种全新思路:将绑定问题重新定义为表示(Representation)问题,并推出了 SkinTokens —— 一种用于蒙皮权重的学习型、紧凑、离散表示。
基于此,团队进一步构建了 TokenRig:一个统一的自回归框架,首次将骨骼生成与蒙皮权重预测联合建模为单一序列生成任务,显著提升了绑定质量与泛化能力。
核心方法:从回归到序列预测
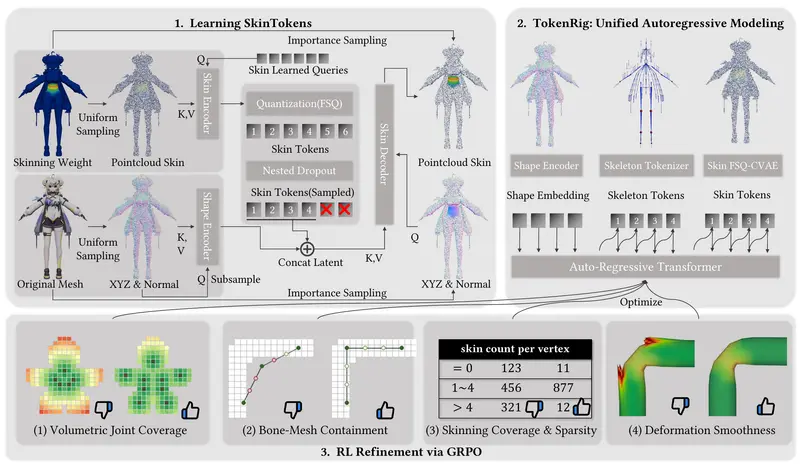
1. 学习 SkinTokens:离散化蒙皮权重
研究团队设计了一个 FSQ-CVAE(有限标量量化条件变分自编码器),将原本稀疏且高维的蒙皮权重压缩为紧凑的离散令牌序列(即 SkinTokens)。
- 利用 VecSet 编码器 同时处理网格几何与蒙皮权重;
- 通过 有限标量量化(FSQ) 实现离散化;
- 引入 嵌套丢弃(nested dropout) 与 重要性采样,确保对关键变形区域(如关节、手指)的重建鲁棒性。
此举将蒙皮任务从“连续回归”转变为“令牌序列预测”,大幅降低优化难度。
2. 统一自回归建模:TokenRig 框架
TokenRig 使用 Transformer 架构,将整个绑定过程建模为一个统一的序列:
- 序列包含:骨骼参数 + SkinTokens;
- 以 全局形状嵌入(global shape embedding) 为条件,捕捉结构依赖;
- 自回归生成确保骨骼与蒙皮之间的语义对齐与物理一致性。
这是首个将骨骼与蒙皮端到端联合生成的生成式绑定系统。
3. 强化学习精调:提升分布外泛化能力
为应对真实世界中复杂、非标准的 3D 资产(“in-the-wild” models),团队采用 GRPO(Group Relative Policy Optimization) 对模型进行微调,并设计了四项定制奖励函数:
- 体积关节覆盖率:确保骨骼覆盖主要形变区域;
- 骨骼-网格包含度:防止骨骼穿透或脱离网格;
- 蒙皮覆盖率与稀疏性:鼓励局部影响力,避免“渗色”;
- 变形平滑度:提升动画流畅性。
主要贡献
- ✅ 提出 SkinTokens:首个用于蒙皮权重的学习型离散表示,将任务转化为序列预测;
- ✅ 构建 TokenRig:统一的自回归绑定框架,联合生成骨骼与蒙皮;
- ✅ 引入 基于几何与语义的强化学习奖励机制,显著提升对未见资产的泛化能力。
实验结果:显著超越现有方法
定量性能
- 蒙皮准确性:比当前最先进方法提升 98%–133%(以 L1 误差衡量);
- 骨骼预测准确性(倒角距离):提升 17%–22%。
定性优势
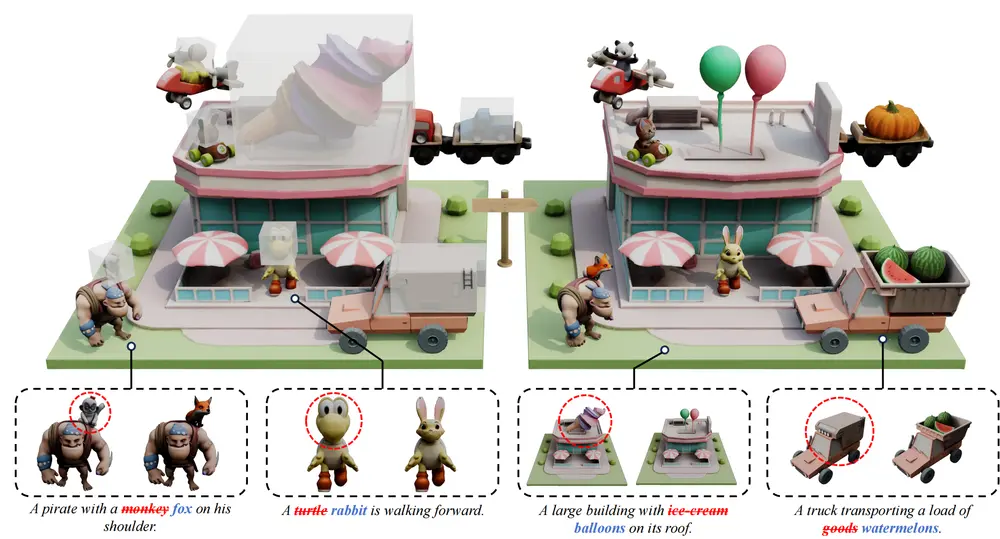
- 骨骼生成:基线方法常出现结构缺失、冗余关节或语义错位;TokenRig 则在人形、动物、幻想角色等多样输入上均生成结构连贯、语义合理的骨骼。
- 蒙皮权重:基线方法普遍存在“渗色”(权重溢出至无关区域);TokenRig 生成的影响力图边界清晰、局部聚焦,尤其在手指、面部等精细区域接近真实标注。
- 泛化能力:在未见过的测试集及复杂野外模型上,仍能稳定输出完整铰接骨骼 + 精确蒙皮,展现强大鲁棒性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











