
从一句“现代客厅,带沙发和挂墙电视”,到一个完整、一致、可编辑的 3D 场景——这曾是 3D 内容创作的理想。如今,中国科学技术大学、南洋理工大学、香港科技大学(广州)与奥胡斯大学联合提出的 DreamScene,正让这一理想逐步成为现实。
- 项目主页:https://jahnsonblack.github.io/DreamScene-Full
- GitHub:https://github.com/DreamScene-Project/DreamScene
DreamScene 是一个端到端的文本到 3D 场景生成框架,首次将 GPT-4 的语义理解能力与 3D 高斯表示(3D Gaussian Splatting) 深度结合,实现了从自然语言或对话输入,自动生成高质量、结构合理且支持精细编辑的室内/室外 3D 场景。

它不仅解决了传统方法在布局合理性、视角一致性与生成效率上的瓶颈,还引入了对4D 动态编辑的支持,为游戏、影视、建筑设计等领域的自动化内容生成提供了新路径。
为什么需要 DreamScene?
当前,文本生成 3D 内容的技术主要依赖扩散模型或 NeRF,但在实际应用中面临三大挑战:
- 缺乏全局规划:多数方法逐个生成物体,忽略整体空间逻辑,导致布局不合理、物体穿插;
- 视角不一致:基于 2D 先验的方法常出现“多头怪”现象——不同视角下物体形态不一致;
- 难以编辑:生成后修改物体位置、外观或运动需重新训练或复杂后处理。
DreamScene 的目标,正是系统性地解决这些问题。
核心架构:四步完成从文本到可编辑 3D 场景
DreamScene 的工作流程分为四个关键阶段:场景规划 → 对象生成 → 环境合成 → 场景编辑。每一步都针对现有痛点进行了专门设计。
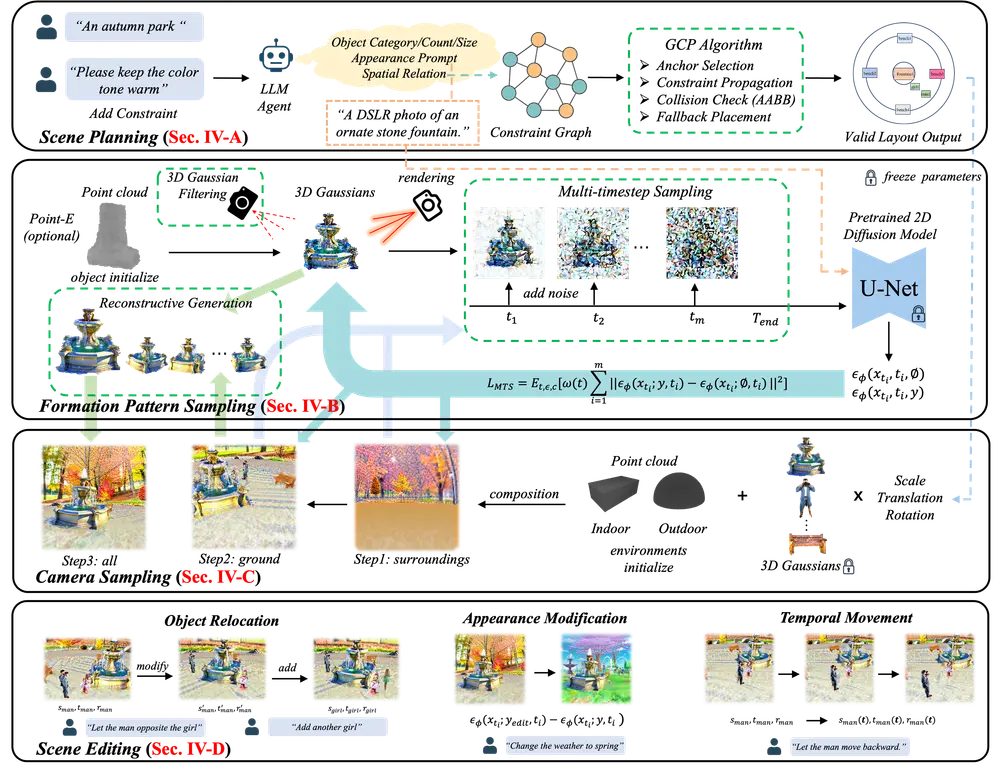
第一步:GPT-4 驱动的场景规划
输入一段文本描述(如“一个现代风格的客厅,有一张大沙发和一台挂在墙上的电视”),DreamScene 首先调用 GPT-4 作为智能代理,进行语义解析与结构推理。
GPT-4 输出:
- 场景中应包含的对象(沙发、电视、咖啡桌等);
- 各对象的属性(颜色、材质、尺寸);
- 空间关系约束(“电视挂在墙上”、“沙发面对电视”);
- 潜在的布局模式(对称、L型、中心聚焦等)。
这些信息被组织成一张混合约束图(Hybrid Constraint Graph),作为后续布局的指导蓝图。
第二步:图约束放置 + 无碰撞布局
基于约束图,DreamScene 采用图约束放置算法(Graph-based Constraint Placement, GCP),在全局坐标系中为每个对象分配初始位置与朝向。
该算法确保:
- 物体之间无重叠;
- 符合物理常识(如电视不放在地上);
- 尊重语义关系(如餐桌靠近厨房)。
这一阶段实现了从“语义描述”到“结构化布局”的关键跃迁。
第三步:Formation Pattern Sampling(FPS)生成对象几何
这是 DreamScene 的核心技术之一:Formation Pattern Sampling(FPS)。
传统方法常使用 NeRF 或网格重建,耗时且难收敛。DreamScene 改用 3D 高斯表示,并通过多步采样策略高效生成每个对象的几何与外观。
FPS 的核心机制包括:
- 多时间步采样(MTS):在多个去噪步中逐步优化对象形状,平衡语义准确性和几何细节;
- 3D 高斯滤波:利用高斯分布建模对象表面,支持快速渲染与视角一致性;
- 重构优化:通过可微渲染反向优化高斯参数,提升真实感。
得益于 3D 高斯的高效性,单个对象生成仅需数分钟,且支持并行处理。
第四步:三阶段相机采样,确保全局一致性
为避免“局部真实、整体失真”的问题,DreamScene 引入渐进式三阶段相机采样策略,分步优化场景整体:
- 粗粒度环境初始化:在稀疏视角下生成背景与大结构;
- 中粒度对象融合:将 FPS 生成的对象插入场景,优化光照与阴影一致性;
- 细粒度细节增强:在密集视角下微调表面纹理与反射效果。
该策略有效提升了场景在多视角下的视觉连贯性。
支持精细编辑:不只是生成,更是创作
DreamScene 不只是一个生成器,更是一个可交互的 3D 编辑平台。它支持多种细粒度操作:
| 编辑类型 | 实现方式 |
|---|---|
| 对象移动 | 调整仿射变换参数,实时重渲染 |
| 外观修改 | 输入新描述(如“把沙发换成皮质棕色”),触发局部重生成 |
| 添加/删除对象 | 更新约束图,增量生成或移除高斯表示 |
| 4D 动态运动 | 为对象绑定时间维度参数,生成周期性或响应式动画(如摆动的吊灯、旋转的风扇) |
这些能力使得 DreamScene 可用于迭代式设计、虚拟空间定制等真实工作流。
实验结果:更快、更真、更可控
在多个基准测试中,DreamScene 表现出显著优势:
1. 生成质量更高
- 在 R-Precision 指标上,DreamScene 达到 0.78,优于 Text2Room(0.61)和 LGM(0.69);
- 用户研究显示,其在场景合理性、视觉真实感和布局舒适度三项上均排名第一。
2. 生成效率大幅提升
- 完整室内场景生成时间平均为 1.5 小时;
- 相比 Text2Room 的 13.3 小时,提速近 9 倍;
- 外部测试表明,90% 的生成可在消费级 GPU(如 RTX 4090)上完成。
3. 编辑灵活度领先
- 所有编辑操作均可在 5 分钟内完成反馈;
- 支持跨模态指令(如“让这盏灯像海浪一样起伏”),体现强语义理解能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











