Nemotron-Speech-Streaming-En-0.6B:面向低延迟与高吞吐的流式语音识别模型英伟达推出的 Nemotron-Speech-Streaming-En-0.6B 是 Nemotron Speech 系列中的首个统一语音识别(ASR)模型,专为实时英语转录场景设计。它同时支持低延迟...语音模型# Nemotron-Speech-Streaming-En-0.6B# 英伟达# 语音识别3个月前0290
Lightricks发布LTX-2:首个基于 DiT 的开源音视频基础模型Lightricks发布了首个基于 Diffusion Transformer(DiT) 架构的开源音视频联合生成模型LTX-2。它在一个统一框架中集成了现代视频生成的核心能力:同步的音频与视频输出...视频模型# Lightricks# LTX-2# 音视频模型3个月前0430
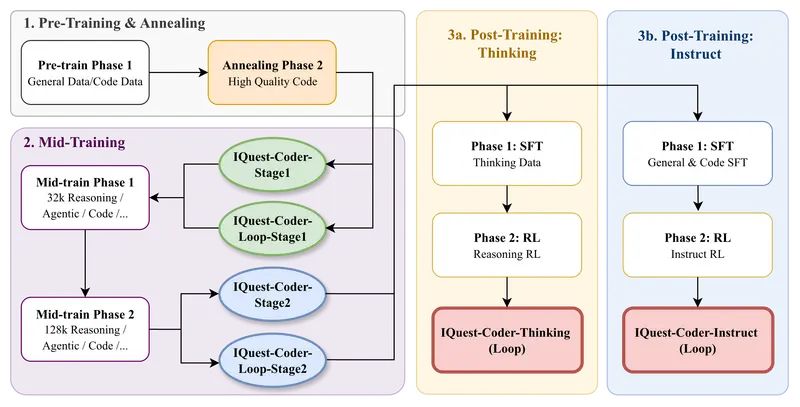
九坤至知开源代码大模型IQuest‑Coder‑V1:Code‑Flow训练+双路径优化,40B模型重塑代码大模型性能边界2026年初,量化基金公司九坤旗下至知创新研究院正式开源IQuest‑Coder‑V1系列代码大模型,涵盖7B、14B、40B、40B‑Loop等版本,专注软件工程与竞赛编程场景,目前已释出40B模型...大语言模型# IQuest‑Coder‑V1# 九坤# 代码大模型3个月前01920
阿里发布文生图模型Qwen-Image-2512:人像、纹理、文字渲染显著提升2025 年 12 月 31 日,阿里 Qwen 项目组发布了 Qwen-Image-2512 —— Qwen-Image 文生图基础模型的最新版本。这是继今年 8 月首次开源 Qwen-Image ...图像模型# Qwen-Image-2512# 文生图模型3个月前0430
Yume1.5:用一张图或一段文字,生成可实时探索的虚拟世界想象一下:你上传一张街景照片,或输入一句描述——“一个穿风衣的男人走在雨夜的东京街头,霓虹灯闪烁,远处有全息广告”——模型随即生成一个可自由行走、视角可调、事件可触发的动态 3D 世界。你用键盘控制角...多模态模型# Yume1.5# 世界模型3个月前0430
1步顶100步!TwinFlow让Qwen-Image、Z-Image推理提速100倍,无需判别器或教师模型当前,大规模多模态生成模型(如 Qwen-Image、Z-Image)在图像与视频生成上展现出惊人能力,但其推理效率仍严重受限——标准扩散或流匹配模型通常需 40–100 次函数评估(NFE)才能生成...图像模型# TwinFlow# TwinFlow-Qwen-Image# TwinFlow-Z-Image-Turbo3个月前01790
fal 发布FLUX.2 Turbo:开源图像模型速度提升6倍,成本降至0.008美元/图在完成 1.4 亿美元 D 轮融资后,AI 媒体基础设施平台 fal.ai(简称 fal)于年末推出其最新成果:FLUX.2 [dev] Turbo —— 一款基于 Black Forest Labs...图像模型# FLUX.2 Turbo3个月前01170
告别 “改不动”!ProEdit:反转编辑新方案,精准修改图像属性,即插即用超 SOTA解决源图像信息过度注入问题,实现更可控的图像与视频编辑 由中山大学、香港中文大学、香港大学与南洋理工大学联合提出,ProEdit 是一种高精度、即插即用的基于反转(inversion-based)的视...图像模型# ProEdit# 编辑图像3个月前0970
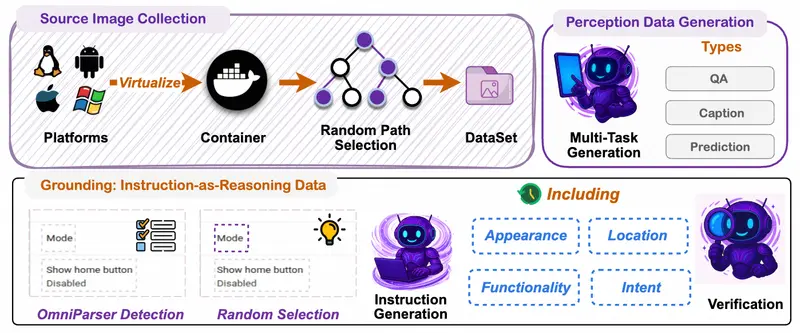
阿里通义开源 MAI-UI:32B 模型 GUI 定位超 Gemini-3-Pro,端云协同重构智能体交互阿里通义实验室近日开源 MAI-UI —— 一个面向真实世界部署的 通用 GUI(图形用户界面)智能体基座模型系列,涵盖 2B、8B、32B 和 235B-A22B 四种规模。其 32B 版本在 Sc...多模态模型# MAI-UI# 通用 GUI模型3个月前01060
Stable Video Infinity(SVI)发布 2.0 Pro:基于错误回收机制的无限长视频生成模型洛桑联邦理工学院(EPFL)的研究团队推出 Stable Video Infinity(SVI) ——一款能够生成任意长度视频的人工智能模型。它通过一项名为 “错误回收微调(Error-Recycli...视频模型# Stable Video Infinity3个月前01470
StoryMem:基于Wan2.2的新框架,用“视觉记忆”生成连贯的多镜头长视频生成一段包含多个镜头、角色一致、场景连贯、时长达一分钟的叙事视频,是当前视频生成模型的重大挑战。主流方法要么局限于单镜头,要么在跨镜头切换时出现角色崩坏、场景断裂等问题。 由南洋理工大学与字节跳动联合...视频模型# StoryMem# Wan2.23个月前0850
VideoRAG:用知识图谱和多模态检索让大模型理解多小时视频当前的大语言模型(LLMs)在处理短视频时已表现出强大能力,但面对数小时甚至跨集的长视频(如讲座系列、纪录片、剧集),它们往往力不从心——上下文窗口有限、计算成本高、跨场景语义断裂。 GitHub:h...多模态模型# VideoRAG# 多模态检索# 知识图谱3个月前0600