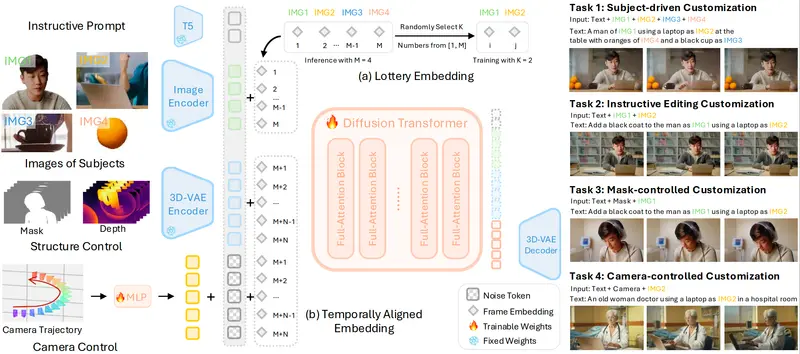
OmniVCus:用多模态控制信号实现前馈式主题驱动视频定制在视频生成领域,一个长期挑战是:如何让用户通过简单指令(如文本、草图或相机轨迹),灵活定制视频中一个或多个主体的外观、动作与空间关系? 由约翰·霍普金斯大学、Adobe 研究院、香港大学、香港中文大学...视频模型# OmniVCus# 视频3个月前0300
MiniMax 发布 MiniMax-M2.1::更智能、更高效、支持多语言的编码与智能体模型在推出专为智能体和代码任务设计的 M2 模型仅数月后,MiniMax 正式发布其增强版本 —— M2.1。 M2 本就以极低成本(约为 Claude Sonnet 的 8%)和高推理速度著称,更引入了...大语言模型# M2.1# MiniMax# MiniMax-M2.1:3个月前0370
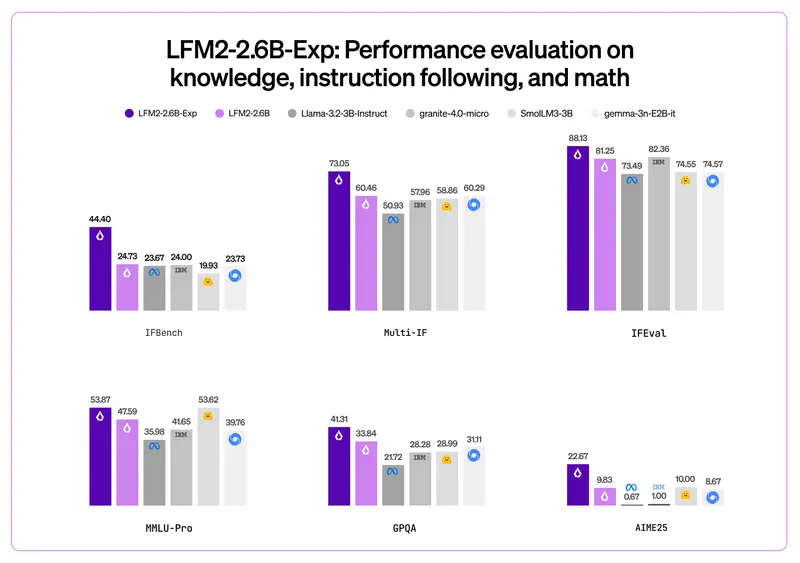
Liquid AI 发布 LFM2-2.6B-Exp:小模型大性能,指令遵循能力超越百倍规模对手Liquid AI 正式推出 LFM2-2.6B-Exp —— 一个基于纯强化学习(RL)训练的实验性语言模型。它在指令遵循、常识推理和数学任务上表现突出,尤其值得注意的是:其 IFBench 评测分...大语言模型# LFM2-2.6B-Exp# Liquid AI3个月前0460
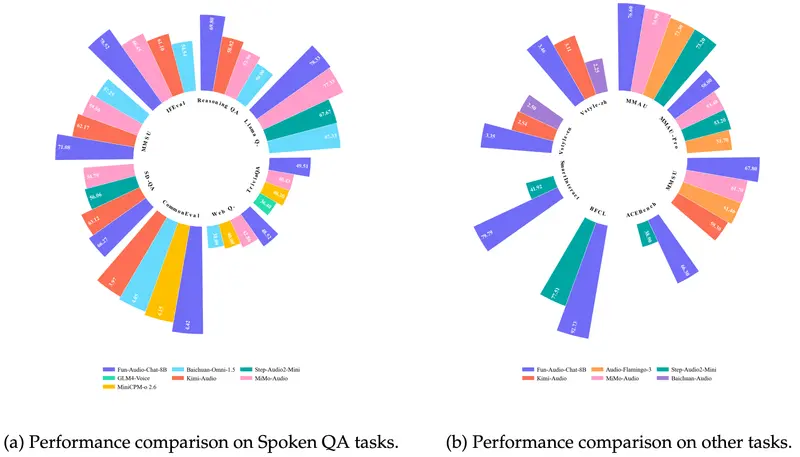
通义百聆发布 Fun-Audio-Chat:8B 端到端语音模型,延迟更低、效率更高通义实验室旗下语音团队 通义百聆(Tongyi Bailin)正式推出 Fun-Audio-Chat —— 一款专为自然、低延迟语音交互设计的端到端大型音频语言模型(Audio Language Mo...语音模型# Fun-Audio-Chat# 通义百聆4个月前0300
阿里通义实验室发布Qwen-Image-Edit-2511:显著提升人物一致性与工业设计能力,支持 LoRA 集成与多图融合阿里通义实验室 Qwen 项目组正式发布 Qwen-Image-Edit-2511,这是继 9 月发布的 Qwen-Image-Edit-2509 后的增强版本。从版本号“2511”可见,该模型原计划...图像模型# Qwen-Image-Edit-2511# 图像编辑模型4个月前02360
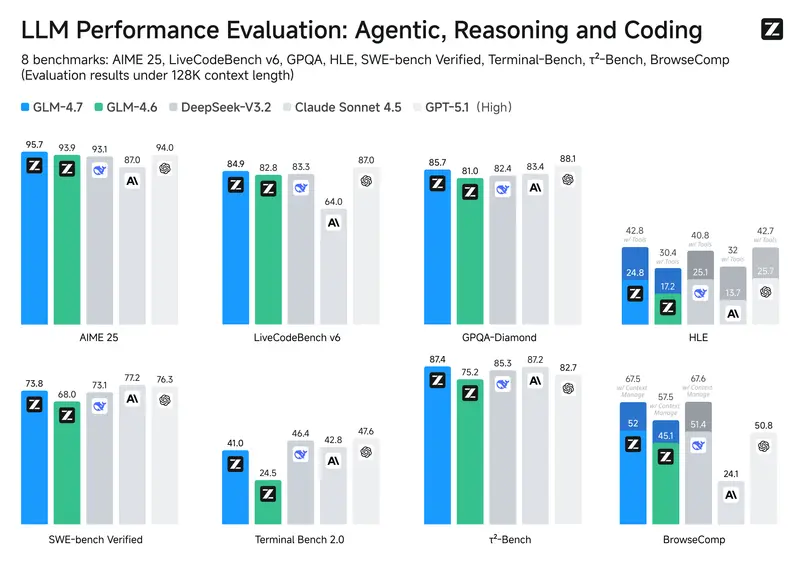
智谱AI发布GLM-4.7:聚焦编程、工具使用与多轮推理智谱AI最新发布的 GLM-4.7 在多个关键维度实现突破,特别是在开发者关注的编程、工具调用与复杂推理能力上,带来可观的性能提升。本文将系统梳理 GLM-4.7 的主要改进,并说明如何快速接入与使用...大语言模型# GLM-4.7# 智谱AI4个月前0510
英伟达发布 Nemotron 3 系列:30B Nano 即用,Super/Ultra 2026 年登场英伟达正式推出 Nemotron 3 开源模型系列,聚焦多智能体协作场景,包含 Nano、Super、Ultra 三个版本,覆盖从轻量推理到超大规模智能体系统的全栈需求。 模型:https://hug...大语言模型# Nemotron 3# 英伟达4个月前0380
图宾根大学提出3D-RE-GEN:从单张照片生成可编辑的完整3D室内场景只需一张室内照片——哪怕家具相互遮挡、背景杂乱——就能重建出带纹理、可单独编辑、空间对齐正确的完整3D场景?图宾根大学的研究团队提出的 3D-RE-GEN 框架,正在将这一目标推向实用化。 项目主页...3D模型# 3D-RE-GEN4个月前0620
TurboDiffusion:视频扩散模型提速 100–200 倍,质量几乎无损视频扩散模型虽能生成高质量内容,但其缓慢的推理速度长期制约实际应用。近日,清华大学、生数科技与加州大学伯克利分校联合提出 TurboDiffusion——一个端到端视频生成加速框架,在单张 RTX 5...视频模型# TurboDiffusion# Wan2.24个月前0330
苹果提出 SHARPA:单图生成 3D 高斯模型,实现秒级实时视图合成苹果近期提出 SHARPA(Single-image High-Accuracy Real-time Parallax),一种从单张 RGB 图像生成高保真、可交互 3D 场景的新方法。该技术通过神经...3D模型# 3D 高斯模型# SHARPA4个月前01110
Chatterbox-Turbo 发布:3.5 亿参数、一步解码、支持副语言标签的高效 TTS 模型Resemble AI 正式开源 Chatterbox 系列——一个由三款高性能文本转语音(TTS)模型组成的开源 TTS 工具集,覆盖低延迟交互、多语言支持与创意语音控制三大典型场景。所有模型均支持...语音模型# Chatterbox-Turbo4个月前0980
Google DeepMind发布T5Gemma 2:支持多模态与 128K 上下文的高效编码器-解码器模型Google DeepMind 正式推出 T5Gemma 2——新一代基于 Gemma 3 架构的编码器-解码器(Encoder-Decoder)模型系列。它不仅继承了 Gemma 3 的先进特性,更...多模态模型# Google DeepMind# T5Gemma 24个月前0330