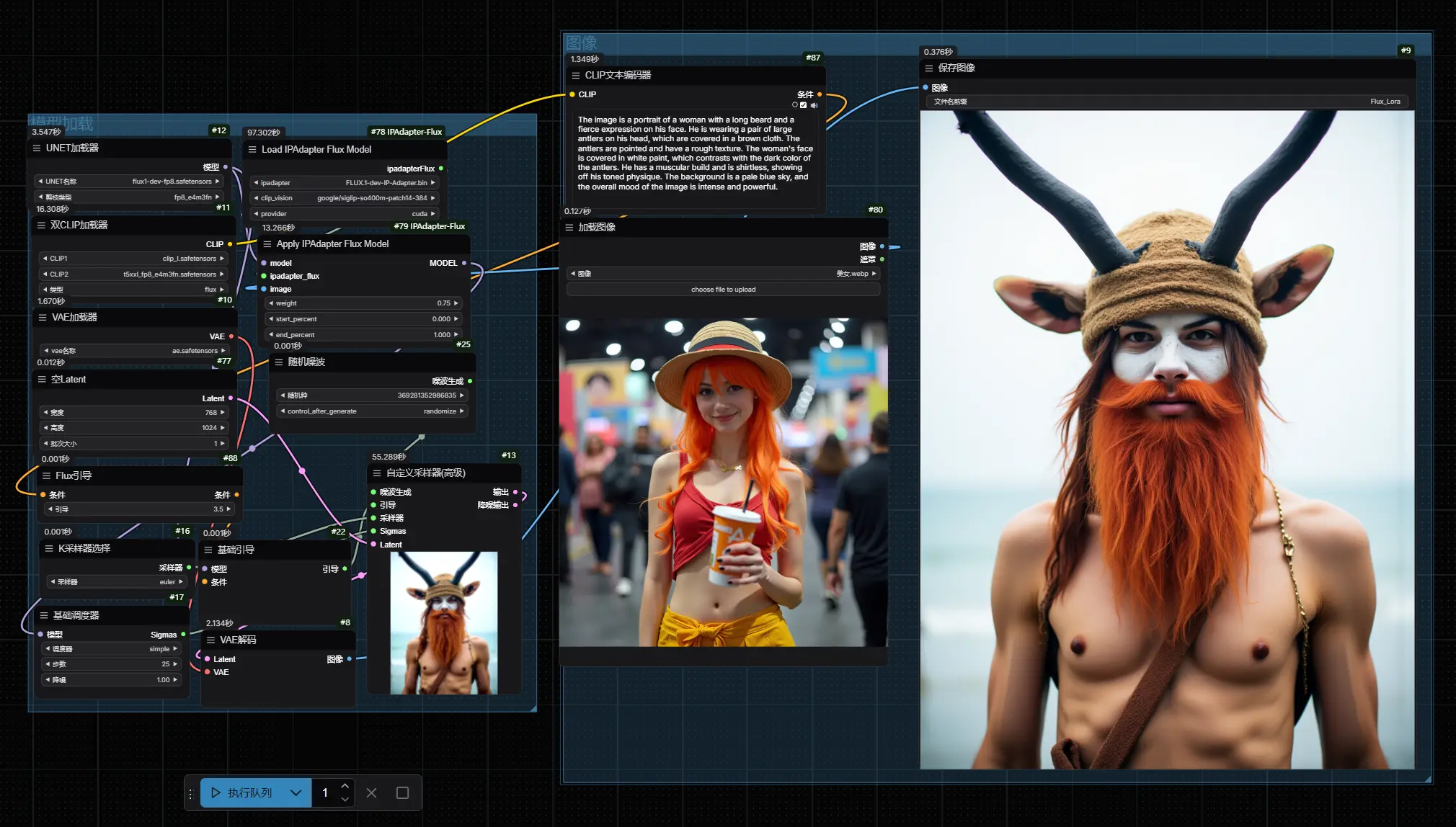
与FLUX.1 Redux竞争?InstantX Team开源基于FLUX.1-dev的IP-Adapter模型FLUX.1-dev-IP-Adapter 是由 InstantX Team 发布的一个 IP-Adapter,最初在 Shakker 平台 上独占。然而,在 Black Forest Labs 发布...Flux衍生# FLUX.1-dev-IP-Adapter# InstantX Team12个月前05310
智象未来开源全新的170 亿参数图像生成基础模型HiDream-I1北京智象未来科技开源了一款全新的图像生成基础模型HiDream-I1,其拥有 170 亿个参数,能够在几秒内实现顶尖的图像生成效果。这一模型提供了三种变体:Full、Dev 和 Fast,以满足不同用...图像模型# HiDream-I1# 图像生成模型# 智象未来10个月前05280
阿里通义实验室Qwen项目组推出图像编辑模型 Qwen-Image-Edit新版本 Qwen-Image-Edit-2509:支持多图输入与更强一致性通义实验室发布 Qwen-Image-Edit-2509,作为 Qwen-Image-Edit 系列的月度迭代版本。该模型已在 Qwen Chat 平台上线,用户可通过“图像编辑”功能直接体验。 Hu...图像模型# Qwen-Image-Edit# Qwen-Image-Edit-2509# 图像编辑模型4个月前05270
Ideogram 3.0发布:更真实、更创意、更一致的生成式设计体验Ideogram在今天正式发布了其最新模型Ideogram 3.0,这款最新的AI生成模型不仅在图像质量和文本渲染方面取得了重大突破,还通过强大的风格控制功能和高效的设计能力,为创作者和专业人士提供了...图像模型# AI绘画# Ideogram# Ideogram 3.010个月前05270
Yandex Research推出分层蒸馏框架SWD:加速扩散模型(如FLUX和SD3.5)的生成过程Yandex Research 推出了一种名为 “Scale-wise Distillation of Diffusion Models (SWD)” 的新型框架,通过分层采样策略加速扩散模型(DMs...图像模型# FLUX# SD3.5# SWD10个月前05240
NeuTTS Air:可在本地运行的高效语音合成模型长期以来,高质量的文本转语音(TTS)能力主要依赖云端 API——虽然效果好,但存在延迟高、隐私风险、网络依赖等问题。 现在,一种新的选择正在出现:在本地设备上实现自然听感的语音合成。 NeuTTS ...语音模型# NeuTTS Air# 语音合成模型4个月前05190
字节跳动推出 USO:统一风格与主体生成模型,开源全方案赋能创作字节跳动智能创作实验室UXO项目组近期发布了UXO家族的新成员——USO(统一风格-主体优化定制模型)。这款模型打破了现有技术中“风格驱动”与“主体驱动”生成相互孤立的困境,能在单一框架下自由组合任意...图像模型# USO# 字节跳动# 统一风格与主体生成模型5个月前05190
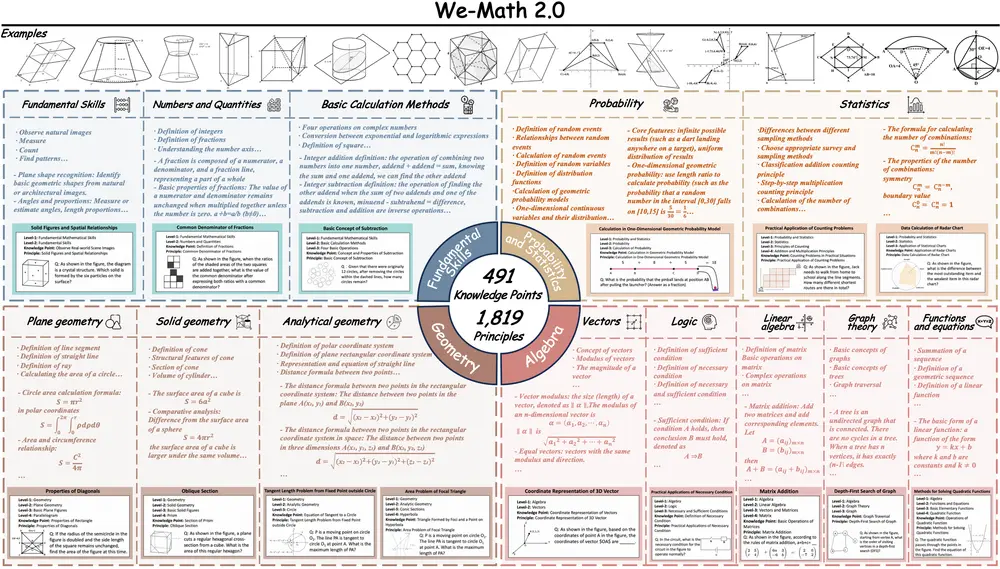
北邮、清华、腾讯联合推出 We-Math 2.0:构建有“知识体系”的数学推理智能体在当前多模态大模型(MLLM)普遍依赖数据驱动“试错式”解题的背景下,北京邮电大学、清华大学与腾讯的研究团队提出了一条不同的技术路径:让模型真正理解数学。 他们联合发布了 We-Math 2.0 ...多模态模型# We-Math 2.0# 数学推理智能体6个月前05180
阿里通义实验室推出新型模型LHM:能够在几秒钟内从单张图像重建出可动画化的人体三维模型阿里通义实验室推出新型模型LHM,能够在几秒钟内从单张图像重建出可动画化的人体三维模型。该模型利用多模态变换器架构,有效融合了人体位置特征和图像特征,通过注意力机制实现了几何和视觉领域的联合推理。 项...视频模型# LHM# 阿里通义实验室11个月前05180
深度求索推出统一图像理解和生成的创新框架JanusFlow:将图像理解和生成统一在一个模型中来自深度求索(DeepSeek-AI)、香港大学、清华大学和北京大学的研究人员提出了一种名为JanusFlow的创新框架,该框架将图像理解和生成统一在一个模型中。JanusFlow引入了一个极简的架构...多模态模型# JanusFlow# 深度求索12个月前05180
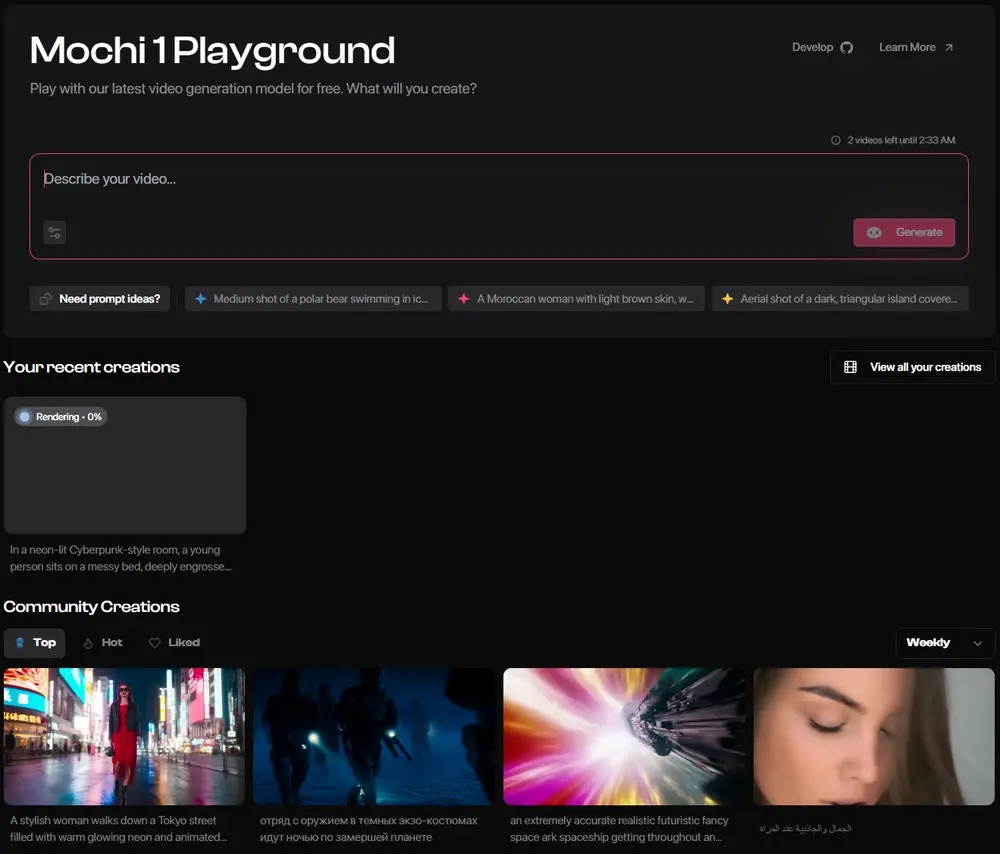
Genmo推出开源视频生成模型天花板Mochi 1,型需 4 块英伟达H100 显卡才可运行Genmo是一家专注于视频生成的AI初创公司,之前都是默默无闻,其官方视频生成产品也是半死不活,但他们在昨天突然放大招开源了一款视频生成模型Mochi 1,号称其性能可与领先的闭源/专有竞争对手(如R...视频模型# Genmo# Mochi 1# 视频生成模型12个月前05180
个性化视觉编辑框架SwapAnything:可以在保持上下文不变的情况下,用参考提供的个性化概念替换图像中的任何物体来自加州大学圣克鲁斯分校和Adobe的研究人员推出个性化视觉编辑框架SwapAnything,它可以在保持上下文不变的情况下,用参考提供的个性化概念替换图像中的任何物体。与现有的个性化主体替换方法...图像模型# SwapAnything# 个性化视觉编辑12个月前05180