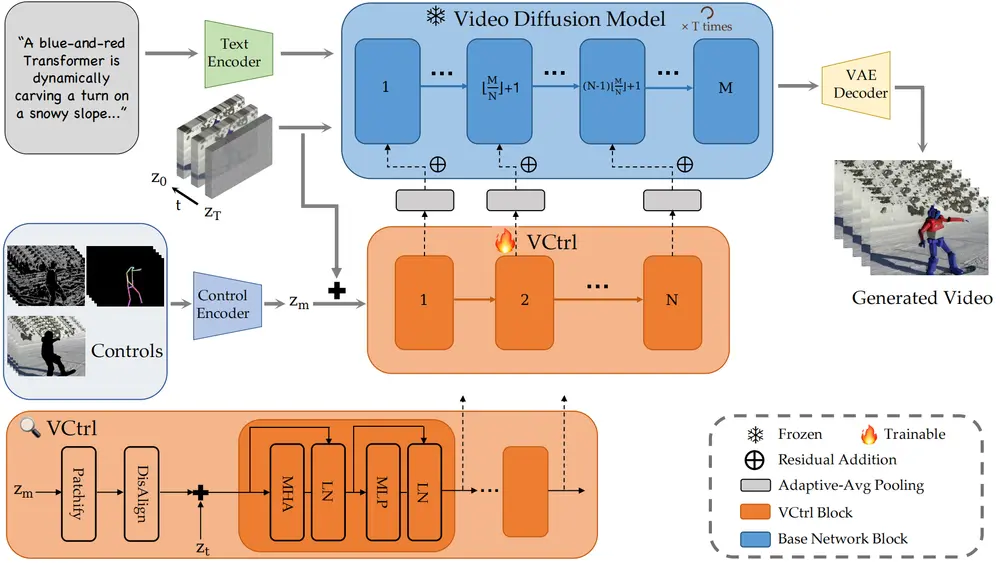
通用视频生成控制模型PP-VCtrl:引入辅助条件编码器,能够灵活对接各类控制模块在数字创意蓬勃发展的当下,视频生成技术已成为内容创作的核心驱动力之一。然而,尽管文本到视频的扩散模型取得了显著进展,但在精确控制生成内容的时空特征方面仍存在诸多挑战。广告创意、影视后期制作、直播带货...视频模型# PP-VCtrl# 视频生成控制模型10个月前05150
阶跃星辰发布 NextStep-1:140 亿参数自回归模型,用“连续令牌”重塑图像生成在图像生成领域,自回归模型长期被视作“文本专家,视觉弱项”——它们擅长逐词生成语言,却难以像扩散模型那样精细构建图像。而如今,阶跃星辰(StepFun)正试图打破这一边界。 GitHub:https...图像模型# NextStep-1# 图像生成# 图像编辑6个月前05140
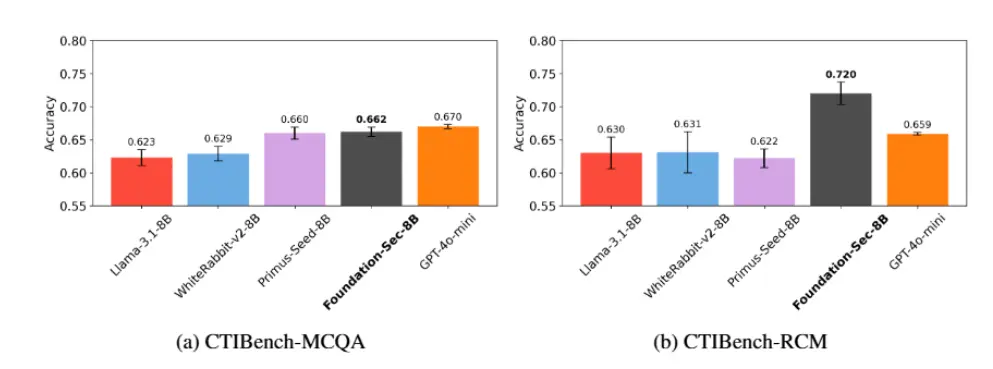
思科发布专为网络安全打造的开源模型 Foundation-sec-8b思科宣布其在AI领域的重大进展——推出首个由全新成立的Foundation AI团队开发的大语言模型(LLM):Llama-3.1-FoundationAI-SecurityLLM-base-8B(简...大语言模型# Foundation-sec-8b# 思科9个月前05140
背景移除模型BEN:自动从图像中移除背景,生成二值掩码和前景图像BEN(Background Erasure Network)是由Prama LLC推出的一款深度学习模型,旨在自动从图像中移除背景,生成二值掩码和前景图像。 模型:https://huggingfa...图像模型# BEN# 背景移除模型12个月前05140
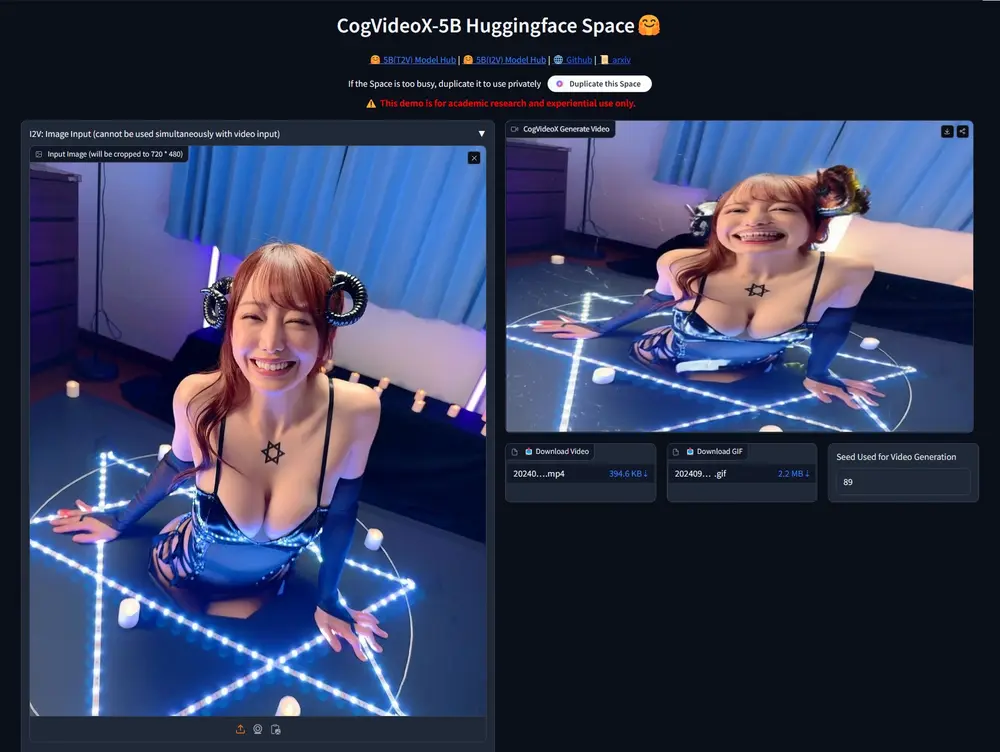
智谱 AI推出CogVideoX 系列图生视频模型 CogVideoX-5B-I2VCogVideoX是智谱 AI推出的与 清影 同源的开源版本视频生成模型,之前已经释出了CogVideoX-2B和CogVideoX-5B模型,智谱 AI又在昨天释出了 CogVideoX 系列图生视...视频模型# CogVideoX-5B-I2V# 智谱 AI12个月前05140
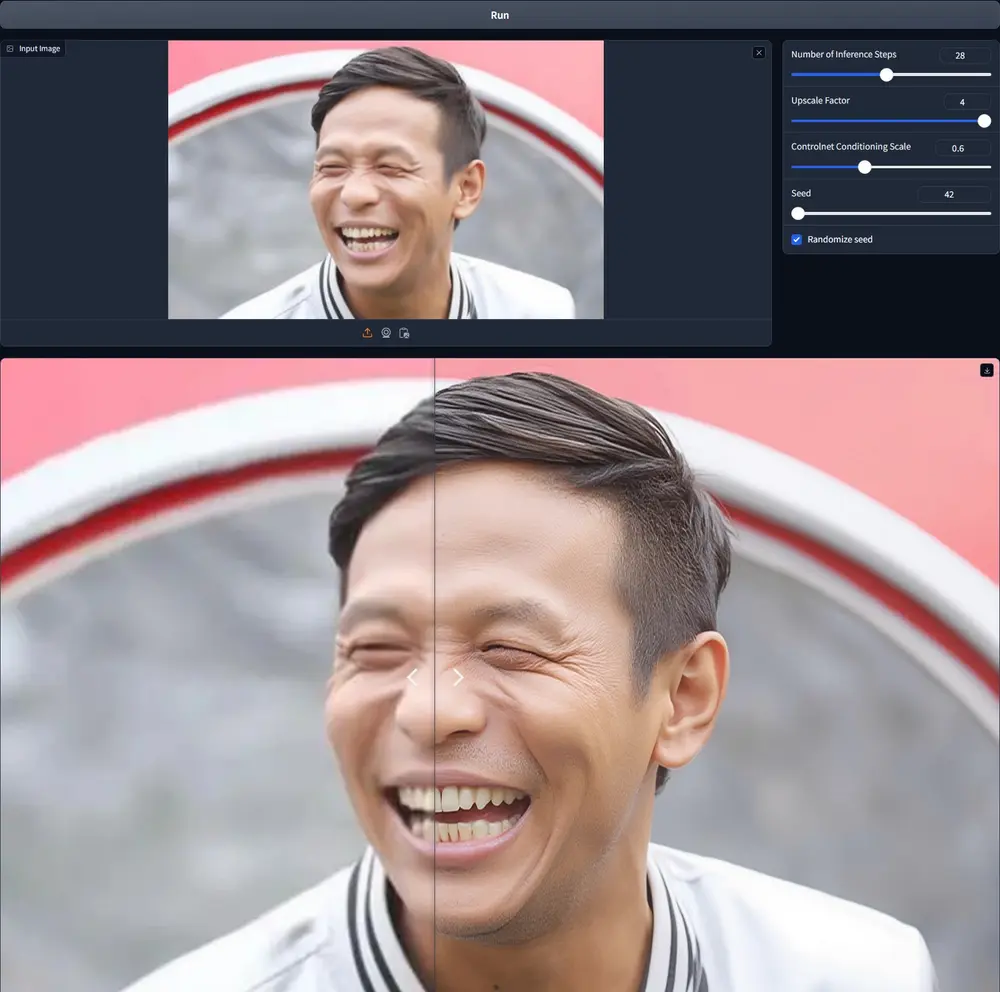
Jasper研究团队推出适用于FLUX.1-dev 的新型 Upscaler、深度和法线贴图 ControlNet模型在FLUX.1-dev取代SDXL和SD3成为开源社区最爱的文生图开源模型, 各种周边模型也是层出不穷,今天给大家分享近期推出的适用于 FLUX.1-dev 的新型 Upscaler、深度和法线贴图 ...Flux衍生# ControlNet模型# FLUX.1-dev12个月前05130
SliderSpace:自动分解文生图模型的视觉能力,将其转化为简单的滑块控件,使用户能够更直观地控制生成结果扩散模型(Diffusion Models)在生成高质量图像方面表现出色,但其生成过程的黑箱性质限制了用户的控制能力。为了增强扩散模型的可控性和可解释性,来自美国东北大学和 Adobe Researc...图像模型# Adobe Research# SliderSpace# 东北大学11个月前05120
Block Diffusion:结合了自回归(Autoregressive)和扩散(Diffusion)模型优点的新型语言生成模型康奈尔科技校区、斯坦福大学和Cohere推出语言模型Block Diffusion,它是一种结合了自回归(Autoregressive)和扩散(Diffusion)模型优点的新型语言生成模型。论文的核...大语言模型# Block Diffusion# 大语言模型11个月前05110
Watermark-Detection-SigLIP2:高效检测图像水印的视觉语言模型在数字内容管理中,水印检测是一项关键任务。无论是内容审核、数据集清理,还是版权保护,快速准确地识别图像中的水印都能显著提升工作效率。Watermark-Detection-SigLIP2 是一款基于谷...多模态模型# Watermark-Detection-SigLIP2# 水印检测9个月前05100
小红书推出图像生成模型StoryMaker:不仅能保持面部一致性,还能保持服装、发型和身体的一致性,从而通过一系列图像促进故事的创作小红书推出图像生成模型StoryMaker,它专门设计用于在文本到图像的生成过程中保持人物的一致性。这种一致性不仅限于人物的面部特征,还包括服装、发型和身体特征。通过这种方式,StoryMaker能够...图像模型# StoryMaker# 小红书12个月前05100
腾讯发布混元Large-Vision:支持原生分辨率输入的旗舰级多模态理解模型腾讯正式推出 混元Large-Vision —— 一款面向复杂任务的旗舰级多模态大模型。该模型在文档理解、数学推理、视频分析和三维空间感知等高难度场景中表现突出,同时具备卓越的多语言支持能力,在LMA...多模态模型# Hunyuan-Large-Vision# 混元Large-Vision# 腾讯6个月前05090
Qodo推出代码嵌入模型Qodo-Embed-1:专为软件开发领域设计,在优化自然语言到代码和代码到代码的检索任务在软件开发领域,代码嵌入模型正逐渐成为提升开发效率和代码质量的关键工具。今天,Qodo 宣布推出其最新的代码嵌入模型系列 Qodo-Embed-1,该系列在保持较小模型体积的同时,实现了最先进的性能...大语言模型# Qodo# Qodo-Embed-1# Qodo-Embed-1-1.5B11个月前05090