新加坡国立大学推出 PaperTalker:首个从论文自动生成学术演讲视频的多智能体框架对于研究人员来说,将一篇论文转化为一场高质量的学术演示视频,往往意味着数小时的设计、录制与剪辑——即使最终视频只有5到10分钟。 幻灯片排版、语音同步、字幕对齐、讲解节奏控制……这些重复性工作消耗大量...视频模型# PaperTalker4个月前02170
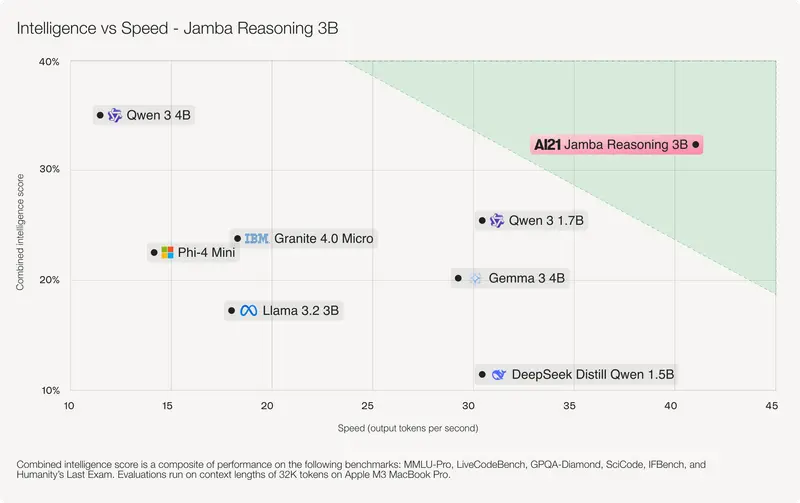
AI21 发布Jamba Reasoning 3B:30亿参数模型实现25万Token上下文,可在笔记本运行在小型语言模型(SLM)加速落地的趋势下,以色列AI公司 AI21 Labs 推出其最新力作——Jamba Reasoning 3B。 模型:https://huggingface.co/ai21la...大语言模型# AI21# Jamba Reasoning 3B4个月前01210
三星研究员发布 TRM:700万参数小模型,在特定推理任务上超越大模型一个仅含 700万参数 的神经网络,如何在性能上匹敌甚至超过参数量高达其 10,000倍 的大语言模型? 这不是理论设想,而是现实。 三星先进技术研究院(SAIT)蒙特利尔分部的高级AI研究员 Ale...大语言模型# TRM# 三星# 小模型4个月前01580
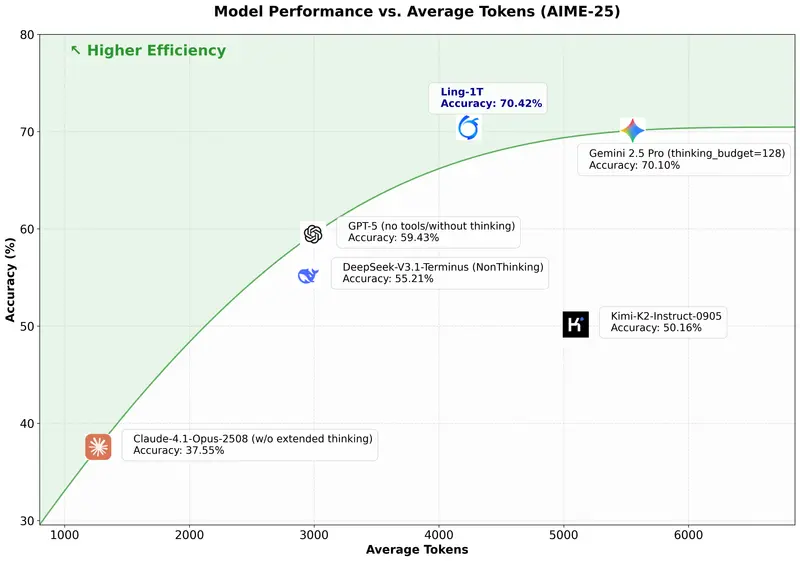
蚂蚁集团发布万亿参数大模型 Ling-1T:开源最强非思考模型,推理效率超越 Gemini蚂蚁集团百灵大模型团队正式推出其新一代通用语言模型——Ling-1T。作为“百灵”Ling 2.0 系列的首款旗舰级非思考(non-thinking)模型,Ling-1T 拥有 总计1万亿参数,单次推...大语言模型# Ling-1T# 蚂蚁集团4个月前03570
Code2Video:基于代码智能体的教育视频生成框架尽管当前文生视频模型在短片段合成上取得进展,但在生成结构严谨、知识准确、视觉连贯的教育视频方面仍面临挑战。这类内容不仅要求语义正确,还需具备清晰的空间布局、逻辑动画过渡和教学节奏控制。 为此,新加坡国...视频模型# Code2Video# 教育视频生成4个月前02170
StreamDiffusionV2:支持多显卡的实时视频生成系统由加州大学伯克利分校、麻省理工学院、斯坦福大学、德克萨斯大学奥斯汀分校与 First Intelligence 联合研发的 StreamDiffusionV2 正式开源。这是一个面向交互式直播场景的实...视频模型# StreamDiffusionV24个月前01980
谷歌推出新型 AI 模型Gemini 2.5 Computer Use,可操作浏览器完成网页任务谷歌发布一款名为 Gemini 2.5 Computer Use 的新型 AI 模型,能够通过浏览器窗口执行点击、滚动、输入文本等交互操作,帮助用户在那些没有开放 API 的网站上自动完成任务。 这项...多模态模型# Gemini 2.5 Computer Use# 谷歌4个月前01580
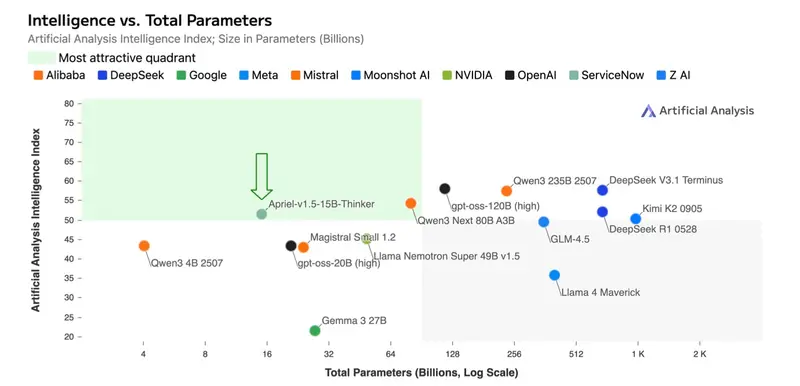
Apriel-1.5-15B-Thinker:用中期训练提升多模态推理效率在大模型竞赛普遍追求参数规模和算力投入的背景下,一个名为 Apriel-1.5-15B-Thinker 的新开源模型带来了不同的思路:它不依赖强化学习或偏好优化,也不从零训练,而是通过精心设计的中期训...大语言模型# Apriel-1.5-15B-Thinker4个月前01070
小红书开源 FireRedChat:一个完整、可控的全双工语音交互系统在智能助手和客户服务场景中,用户希望与AI的对话像人与人交流一样自然——可以随时插话、打断、继续,而系统能即时响应。要实现这种体验,需要真正的全双工语音交互能力。 然而,现有方案存在明显短板: 端到端...语音模型# FireRedChat# 小红书4个月前02870
IBM 发布 Granite 4.0:基于 Mamba-2/Transformer 混合架构的新一代高效开源大模型IBM 正式推出其最新开源语言模型系列 Granite 4.0,标志着企业在追求高性能与低推理成本之间的平衡上迈出关键一步。 这一代模型不再依赖传统的纯 Transformer 架构,而是采用创新的 ...大语言模型# Granite 4.0# IBM4个月前0640
NeuTTS Air:可在本地运行的高效语音合成模型长期以来,高质量的文本转语音(TTS)能力主要依赖云端 API——虽然效果好,但存在延迟高、隐私风险、网络依赖等问题。 现在,一种新的选择正在出现:在本地设备上实现自然听感的语音合成。 NeuTTS ...语音模型# NeuTTS Air# 语音合成模型4个月前05190
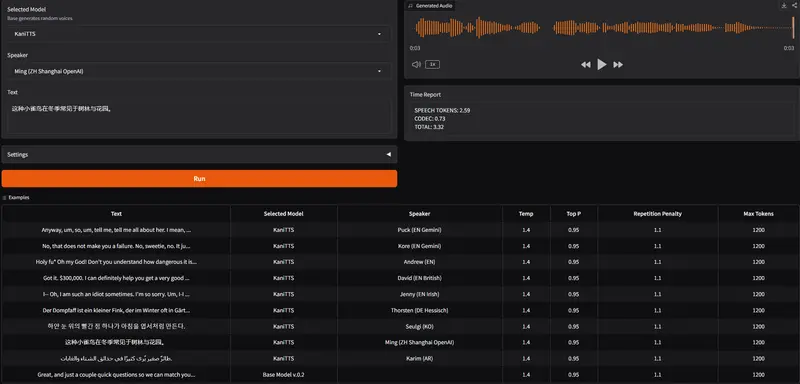
KaniTTS 发布:一种高效且富有表现力的文本到语音模型NineNineSix 团队近日推出 KaniTTS ——一个专为低延迟、高保真语音合成设计的开源文本到语音(TTS)系统。 GitHub:https://github.com/nineninesix...语音模型# KaniTTS4个月前01720