加州理工推出Conversational Image Segmentation:对话式图像分割,让 AI 真正听懂“这个稳不稳”、“那个能不能坐”在传统的计算机视觉中,AI 擅长回答“这是什么?”(分类)或“它在哪里?”(检测/分割)。如果你问它:“把左边那个红色的杯子框出来”,它能做得很好。 但如果你问:“哪个行李箱可以单独拿走而不弄倒整堆行...多模态模型# Conversational Image Segmentation# 对话式图像分割2个月前0160
字节跳动开源 BitDance:14B 参数自回归模型,生成速度超越扩散模型 30 倍在 AI 绘画领域,长期存在着“画质”与“速度”的博弈,以及“扩散模型”与“自回归模型”的路线之争。扩散模型(如 Stable Diffusion)画质优异但推理步骤繁琐;自回归模型(类似 LLM 生...图像模型# BitDance# 字节跳动# 自回归模型2个月前02140
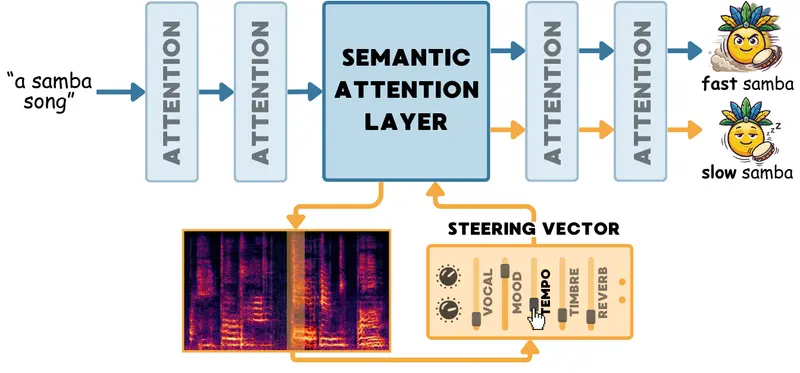
TADA:给AI音乐生成装上"调音台",让创作精准可控想象一下,你对AI说"生成一首桑巴舞曲",它确实生成了一段不错的音乐。但你现在觉得节奏稍微快了点,或者想把女声换成男声,又或者想加点钢琴伴奏——用传统的文字提示,你只能说"一首快节奏的男性演唱桑巴舞曲...语音模型# TADA# 音频扩散模型2个月前0180
阿里发布Qwen3.5 系列大模型:两大旗舰模型登场,多项评测超越国际一线今天下午,阿里并未进行大规模宣传,而是在其官方对话页面chat.qwen.ai上低调上线了Qwen3.5系列的两款全新大语言模型——Qwen3.5-Plus与Qwen3.5-397B-A17B。 项目...大语言模型早报# Qwen3.5# Qwen3.5-397B-A17B# Qwen3.5-Plus2个月前0670
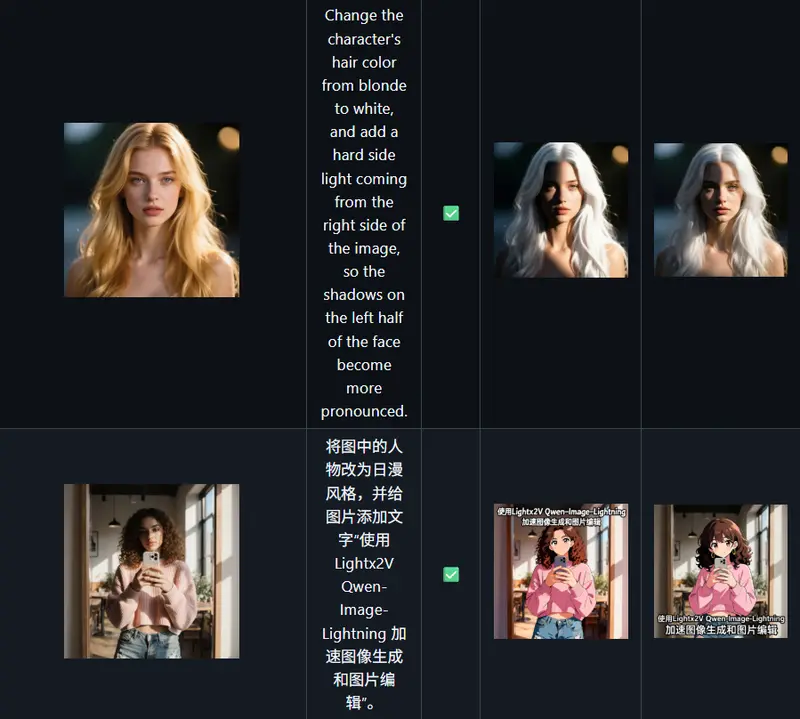
Qwen-Image-Edit-Causal:用分块因果注意力加速图像编辑推理Light AI 近日发布了 Qwen-Image-Edit-Causal V1.0,这是对 Qwen-Image-Edit-2511 的一次关键优化。新模型通过引入 分块因果注意力(block ca...图像模型# Qwen-Image-Edit-2511# Qwen-Image-Edit-Causal2个月前0640
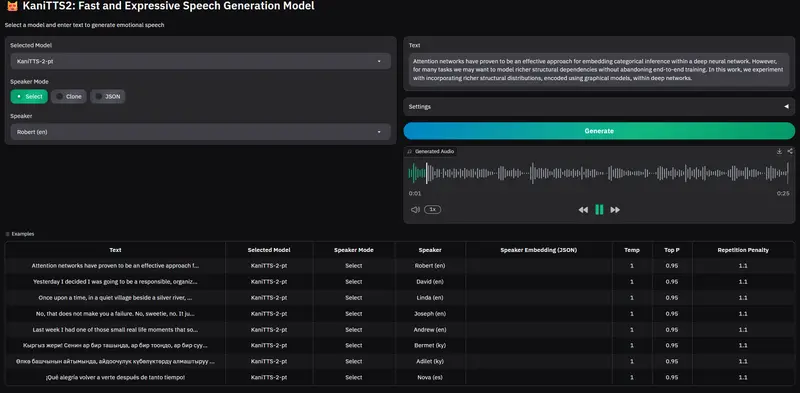
NineNineSix 开源 KaniTTS2:4 亿参数实时对话 TTS 模型,支持语音克隆与多语言AI 初创公司 NineNineSix 正式开源其新一代文本转语音(TTS)模型 KaniTTS2。该模型专为低延迟、高自然度的实时对话场景设计,支持语音克隆、多语言输出,并提供完整的从零预训练代码框...语音模型# KaniTTS2# TTS 模型2个月前0390
让视频"无中生有"的AI魔术师!PISCO:基于稀疏控制的精确视频实例插入技术想象一下,你拍了一段空无一人的街道视频,现在想把一只奔跑的猫放进画面里——不仅要让它看起来真实,还要让它和周围环境产生互动:地上要有影子,经过水坑要有倒影,被路灯照到要反光。更神奇的是,你只需要告诉A...视频模型# PISCO# 视频编辑2个月前0190
京东开源 JoyAI-LLM-Flash:3B 激活参数 MoE 模型,专为智能体与高吞吐场景优化京东在 Hugging Face 正式开源其最新大语言模型 JoyAI-LLM-Flash,标志着其在高效、低成本、智能体友好型 AI 基础模型领域的重大进展。 模型:https://huggingf...大语言模型# JoyAI-LLM-Flash# 京东2个月前0500
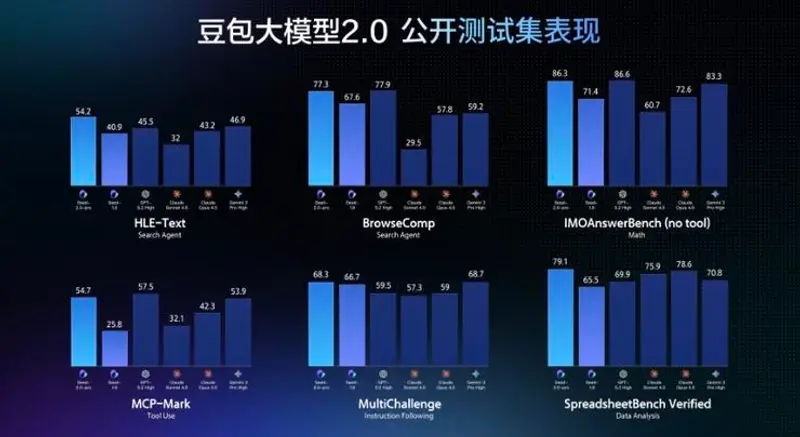
字节跳动发布豆包大模型2.0:数学推理顶尖,复杂任务执行强,API价格仅为竞品五分之一继 Seedance 2.0 视频模型和 Seedream 5.0 Lite 图像模型后,字节跳动于 2 月 14 日正式推出 豆包大模型 2.0(Doubao-Seed-2.0)系列。新版本针对大规...大语言模型早报# Doubao-Seed-2.0# 字节跳动# 豆包大模型2.02个月前0320
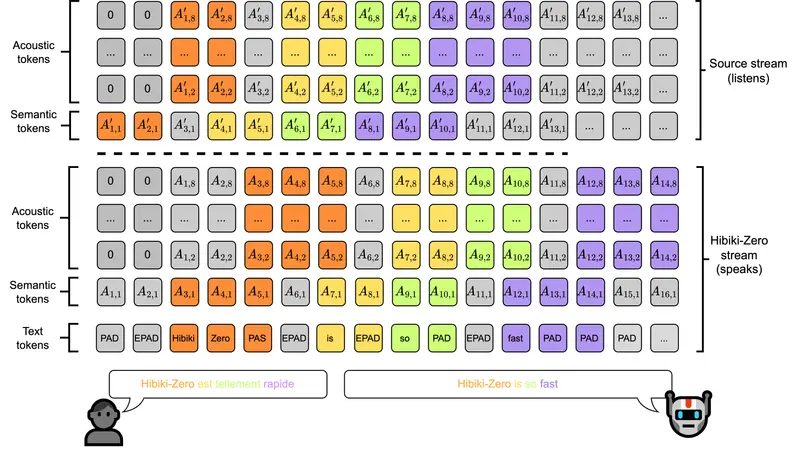
Kyutai 开源 Hibiki-Zero:3B 参数实时语音翻译模型,无需词级对齐,支持音色迁移实时语音翻译的核心挑战在于如何在翻译质量与系统延迟之间取得最佳平衡。传统方法通常需要大量精细标注的词级对齐数据来指导模型何时开始翻译,这不仅成本高昂,也极大地限制了模型向新语言的扩展能力。 为彻底解决...语音模型# Hibiki-Zero# 实时语音翻译模型2个月前0170
蚂蚁集团 inclusionAI 团队发布统一生成模型Ming-omni-tts:统一语音、音乐与声音生成,实现高精度细粒度可控音频合成蚂蚁集团 inclusionAI 团队近期正式发布了 Ming-omni-tts,这是一款设计简洁、运行高效的统一音频生成模型。它不仅可以在单一框架内合成高质量的语音,还能同时生成音乐与各类环境声音...语音模型# Ming-omni-tts# 统一生成模型2个月前0620
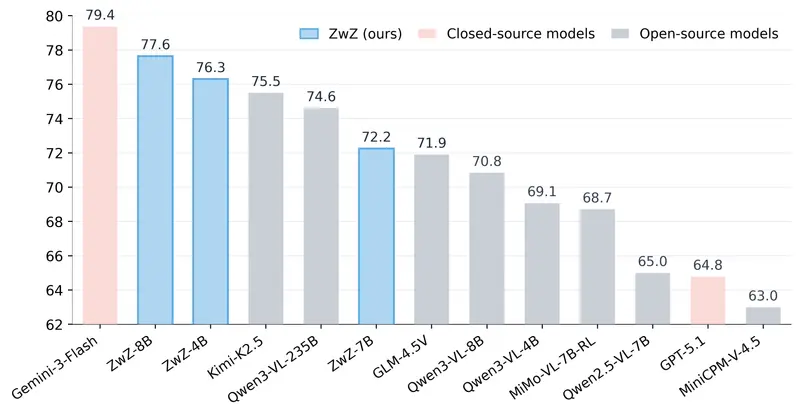
蚂蚁集团开源 ZwZ 模型:无需迭代缩放,单次 glance 实现细粒度多模态感知SOTA当前主流的“图像思考”方法,虽能通过迭代放大感兴趣区域提升细粒度感知能力,却存在致命短板——重复的工具调用与视觉重新编码,导致推理延迟居高不下,难以适配实际应用场景。 针对这一痛点,蚂蚁集团 incl...多模态模型# ZwZ# 蚂蚁集团2个月前0350