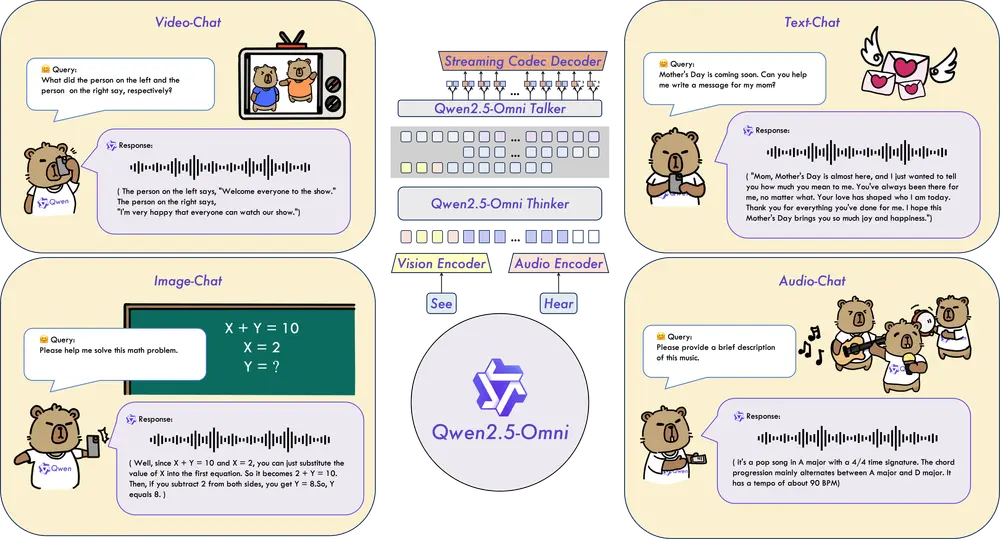
阿里通义实验室发布新一代端到端多模态旗舰模型Qwen2.5-Omni阿里通义实验室发布了 Qwen2.5-Omni,这是 Qwen 模型家族中的新一代端到端多模态旗舰模型。Qwen2.5-Omni 专为全方位多模态感知设计,能够无缝处理文本、图像、音频和视频等多种输入...多模态模型# Qwen2.5-Omni# 多模态模型10个月前02630
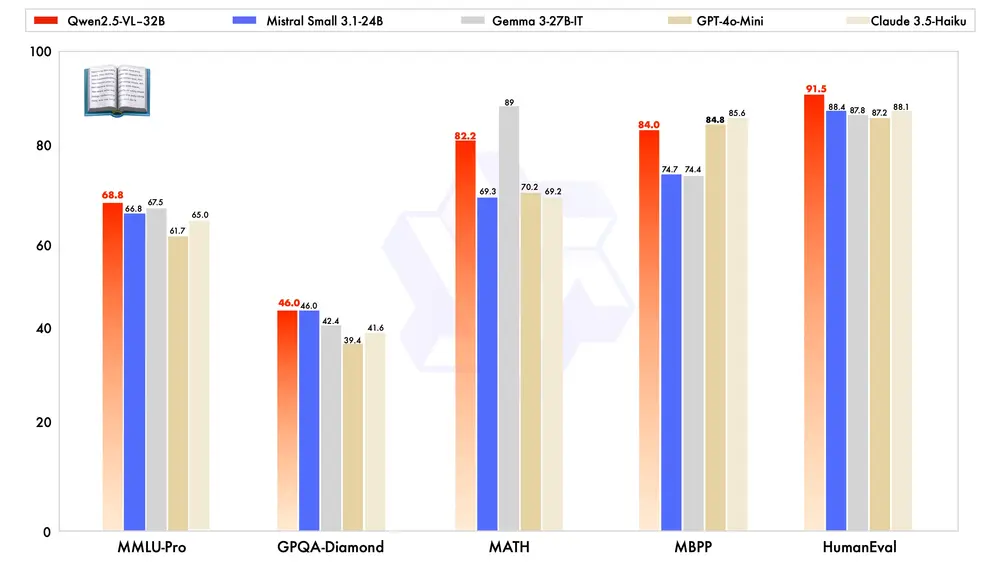
阿里通义实验室开源32B参数的多模态模型 Qwen2.5-VL-32B-Instruct今年一月底,阿里通义实验室推出了 Qwen2.5-VL 系列模型,凭借其卓越的性能和广泛的应用潜力,迅速获得了社区的广泛关注和积极反馈。在此基础上,团队通过强化学习持续优化模型,并于近期开源了备受期待...多模态模型# Qwen2.5-VL-32B-Instruct# 多模态模型# 阿里通义实验室10个月前03040
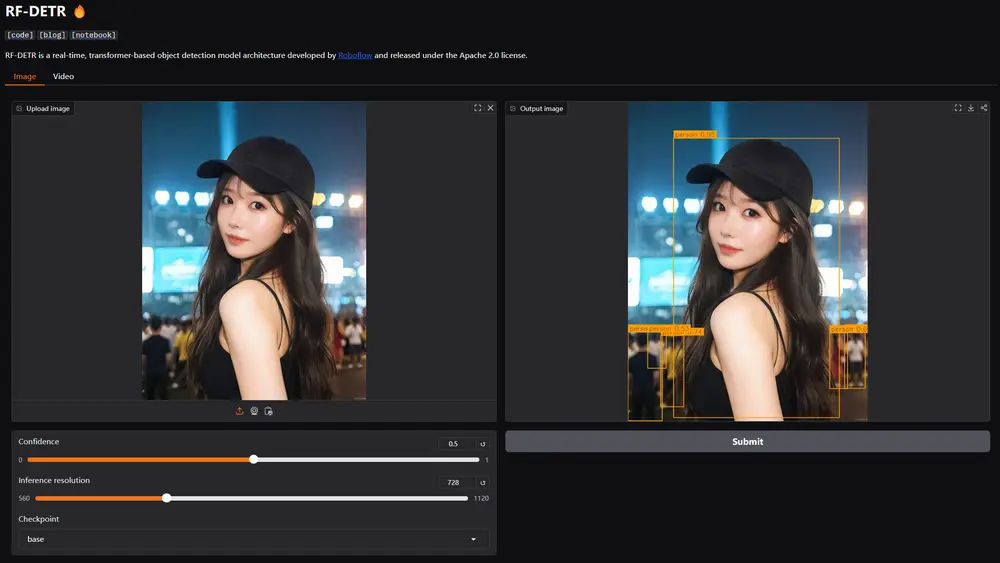
Roboflow开源基于Transformer的实时目标检测模型 RF-DETRRoboflow 近日正式发布了 RF-DETR,一种基于Transformer的实时目标检测模型。RF-DETR 在多个现实世界数据集上的表现超越了所有现有的目标检测模型,并且是首个在 COCO 数...多模态模型# RF-DETR# Roboflow# 实时目标检测模型10个月前02650
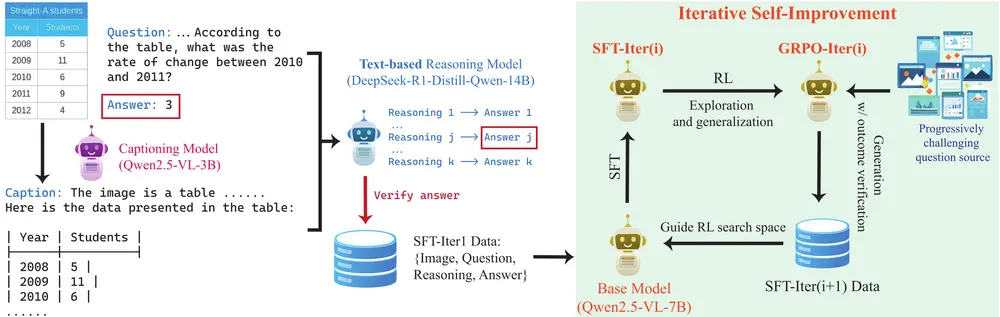
OpenVLThinker:通过迭代自我改进的方法,将复杂的推理能力(如自我验证和自我修正)整合到大型视觉语言模型中加州大学洛杉矶分校的研究人员推出OpenVLThinker,通过迭代自我改进的方法,将复杂的推理能力(如自我验证和自我修正)整合到大型视觉语言模型(LVLMs)中,并评估其在多模态推理任务中的表现。 ...多模态模型# OpenVLThinker# 多模态推理模型10个月前03590
英伟达开源了世界上第一个人形机器人基础模型 GR00T N1,加速通用人形机器人开发人形机器人旨在适应人类工作空间,处理重复性或高要求任务。然而,为现实世界的任务和不可预测环境开发通用人形机器人具有挑战性。每项任务通常需要专用的AI模型。从头开始为每个新任务和环境训练这些模型是一个繁...多模态模型# GR00T N1# 人形机器人基础模型# 英伟达11个月前02830
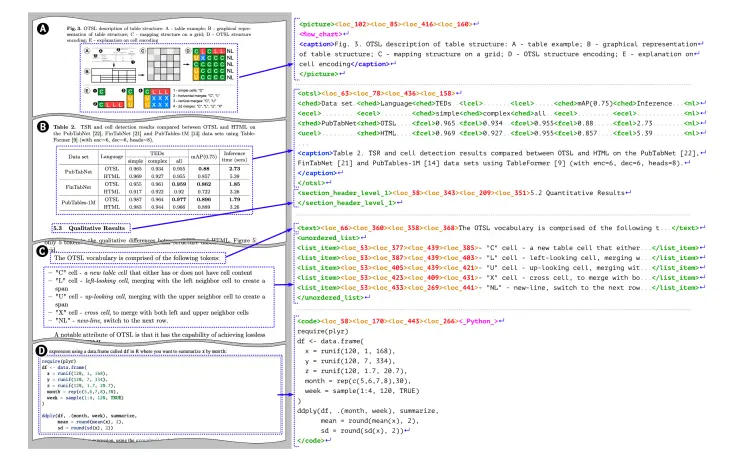
视觉语言模型SmolDocling:以高效的方式实现端到端的多模态文档转换在数字化时代,文档处理和理解是许多行业和研究领域的核心需求。从学术论文到商业报告,从技术手册到专利文件,文档的高效转换和理解对于信息提取、知识管理和自动化流程至关重要。然而,传统的文档处理方法往往依赖...多模态模型# SmolDocling# 文档转换# 视觉语言模型11个月前05080
谷歌Gemini 2.0 Flash重磅升级:原生多模态生成,图像编辑进入对话时代谷歌在昨天除了发布了开源模型Gemma 3,还正式开放了Gemini 2.0 Flash的原生图像生成编辑功能,这款实验性模型凭借单模型多模态生成能力,正在重塑AI创作逻辑。相比传统需要「语言模型+扩...多模态模型# Gemini 2.0 Flash# gemini-2.0-flash-exp# Gemma 311个月前02770
谷歌推出"功能强大的图像安全检查器"ShieldGemma2去年,谷歌发布了 ShieldGemma,这是一套基于 Gemma 2 构建的安全内容分类器模型,旨在检测 AI 模型文本输入和输出中的有害内容。今天,随着 Gemma 3 的亮相,谷歌宣布推出Shi...多模态模型# Gemma 2# Gemma 3# ShieldGemma 211个月前02720
阿里通义实验室开源R1-Omni:用强化学习解锁全模态大模型的新潜力随着DeepSeek R1的发布,强化学习在大模型领域的潜力得到了进一步挖掘。Reinforcement Learning with Verifiable Reward(RLVR)方法为多模态任务提供...多模态模型# R1-Omni# 全模态大模型# 强化学习11个月前02200
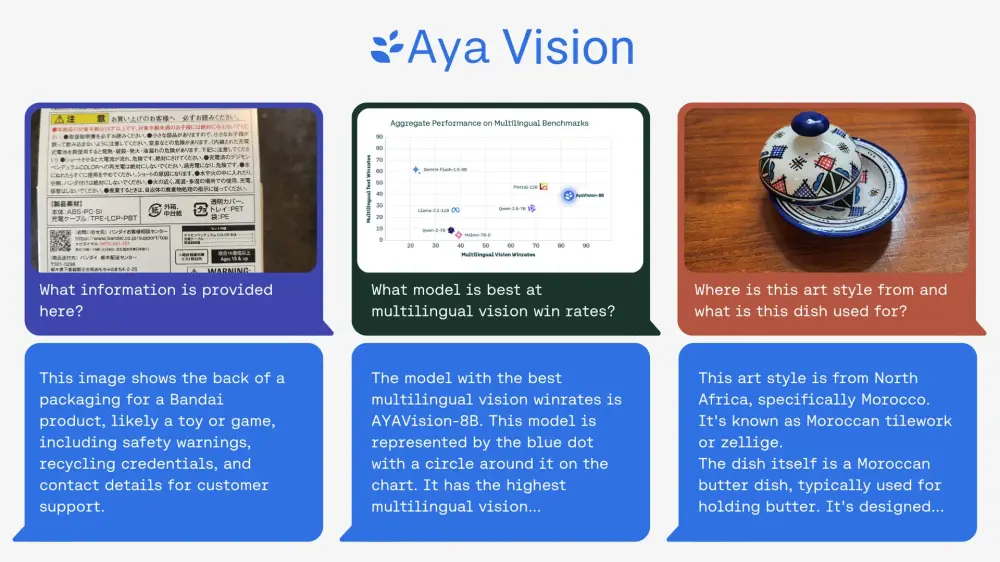
Cohere 推出多语言多模态视觉模型 Aya Vision:集成了语言和视觉功能,并支持多达 23 种语言的输入加拿大 AI 初创公司 Cohere 于 2019 年成立,专注于为企业提供 AI 解决方案。尽管在与 OpenAI 和 Anthropic 等美国巨头的竞争中市场份额有限,且面临来自中国开源竞争对手...多模态模型# Aya Vision# Cohere# 多模态视觉模型11个月前02240
艾伦AI研究所推出 olmOCR:高性能的 PDF 和文档图像文本提取工具包艾伦AI研究所正式推出了 olmOCR,这是一款高性能的开源工具包,专为将 PDF 和文档图像转换为干净、结构化的纯文本而设计。 GitHub:https://github.com/allenai/o...多模态模型# olmOCR# 艾伦AI研究所11个月前01780
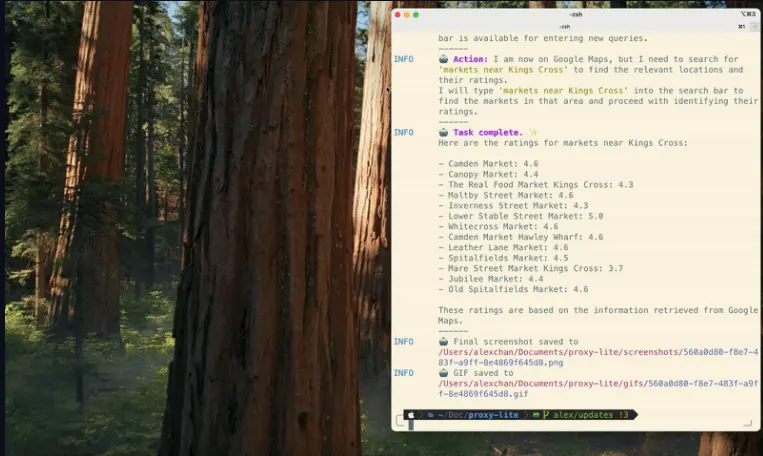
Convergence 发布基于视觉语言模型(VLM)的迷你开源模型 Proxy Lite在数字化时代,自动化与 Web 内容交互的需求日益增长。然而,现有的解决方案往往面临资源密集型、任务特定化以及缺乏透明性等问题。这些问题限制了它们的广泛适用性和社区参与度。 GitHub:https...多模态模型# Convergence# Proxy Lite# 视觉语言模型11个月前02970