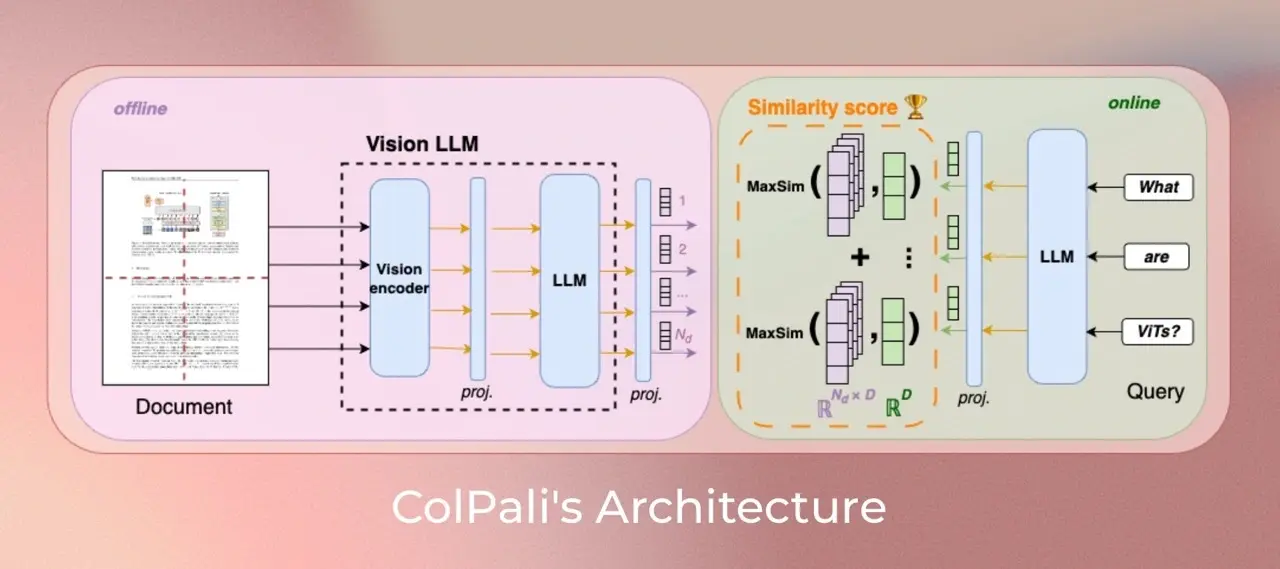
ColPali:基于视觉语言模型的新型高效文档检索系统由 Illuin科技、Equall.ai、巴黎-萨克雷大学和苏黎世联邦理工学院 联合提出,ColPali 是一种基于视觉语言模型(VLMs)的文档检索模型,能够直接从文档图像中提取信息,实现快速、准确...多模态模型# ColPali# 文档检索8个月前01400
ColQwen2.5-Omni:首个支持视觉+音频检索的ColBERT风格模型ColQwen2.5-Omni 是基于 Qwen2.5-Omni-3B-Instruct 的新一代多模态检索模型。该模型采用 ColBERT 策略,支持从图像、音频等多模态内容中高效检索信息,是目前首...多模态模型# ColQwen2.5-Omni8个月前01700
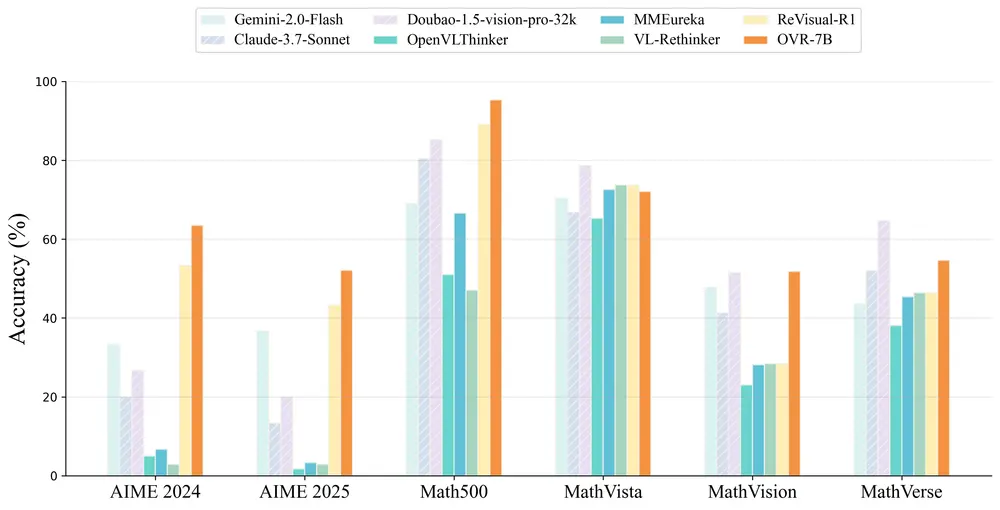
Open-Vision-Reasoner(OVR):基于语言认知迁移的多模态视觉推理新范式大语言模型(LLMs)之所以具备强大的推理能力,关键在于其通过可验证奖励机制的强化学习所涌现的认知行为。那么,是否可以将这一原则迁移至多模态大语言模型(MLLMs),从而解锁其高级视觉推理能力? 本研...多模态模型# Open-Vision-Reasoner# 多模态大语言模型8个月前03270
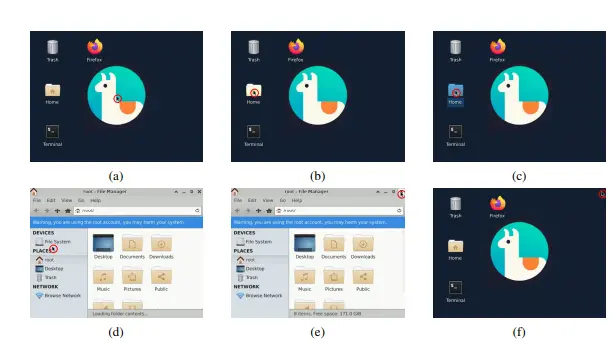
NeuralOS:用神经生成模型模拟操作系统图形界面滑铁卢大学与加拿大国家研究院的研究团队提出了一项极具前瞻性的项目:NeuralOS —— 一个通过神经生成模型模拟操作系统图形用户界面(GUI)的框架。 项目主页:https://neural-os...多模态模型# NeuralOS# 操作系统8个月前0850
PyVision:基于动态工具生成的多模态智能视觉推理框架随着大语言模型(LLMs)的发展,我们正进入一个代理式人工智能(Agent AI)时代。这些模型不仅能够生成文本,还能进行任务规划、逻辑推理,并调用外部工具来扩展能力边界。 但真正的前沿在于:不是仅仅...多模态模型# PyVision# 多模态智能视觉推理8个月前02200
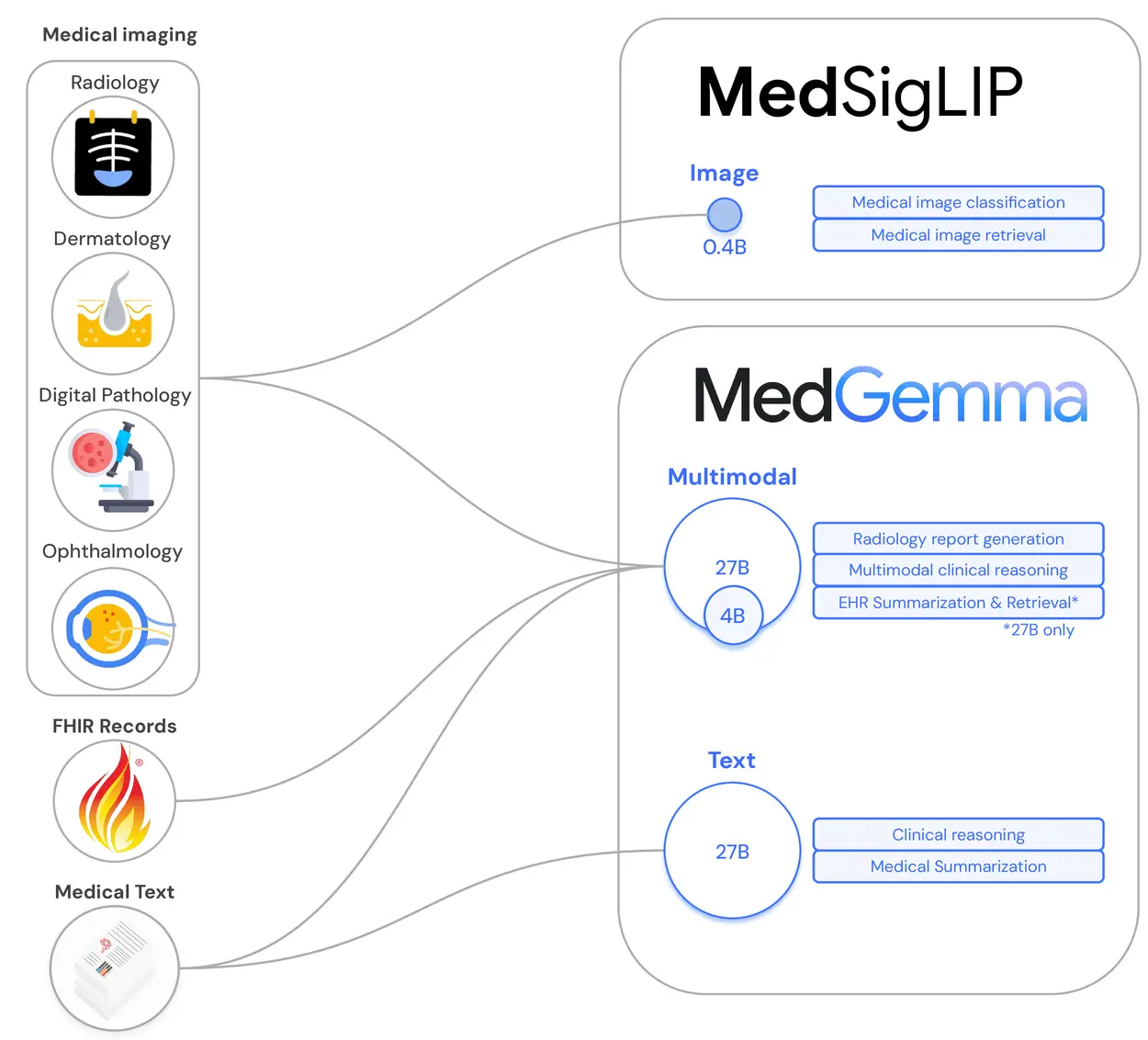
谷歌推出开源医疗 AI 模型系列MedGemma及轻量级图像编码器 MedSigLIP谷歌近日宣布推出其最新的开源医疗 AI 模型系列——MedGemma,并同时发布了轻量级图像编码器 MedSigLIP。这是继健康 AI 开发者基础(HAI-DEF)项目之后,谷歌在医疗 AI 领域迈...多模态模型# MedGemma# MedSigLIP# 谷歌8个月前01570
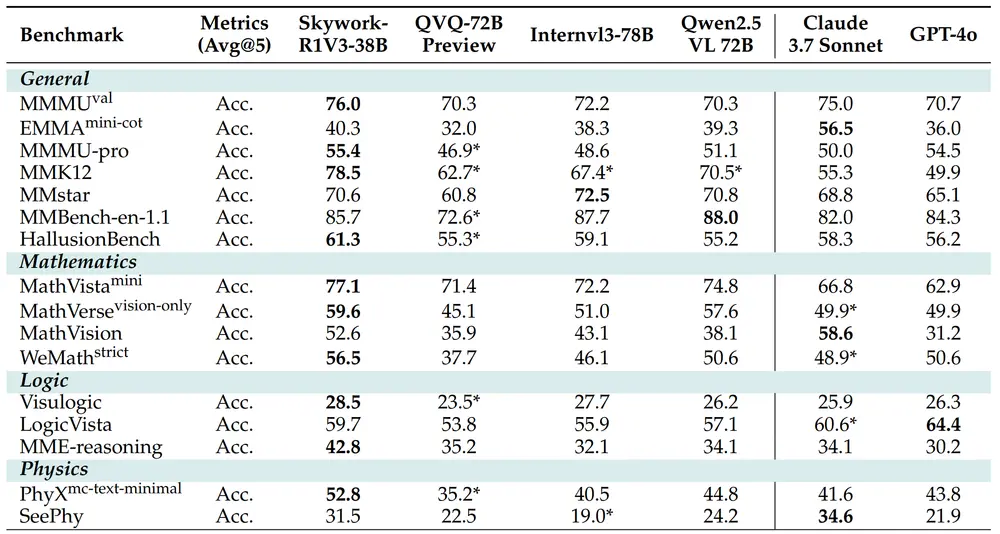
昆仑万维天工项目组推出多模态推理模型 Skywork-R1V3-38B昆仑万维天工项目组近日发布了 Skywork-R1V3-38B,这是其开源视觉-语言模型(VLM)系列 Skywork-R1V 的最新迭代版本,也是目前该系列中性能最强的多模态推理模型。基于 Inte...多模态模型# Skywork-R1V3-38B# 多模态推理模型# 昆仑万维8个月前02340
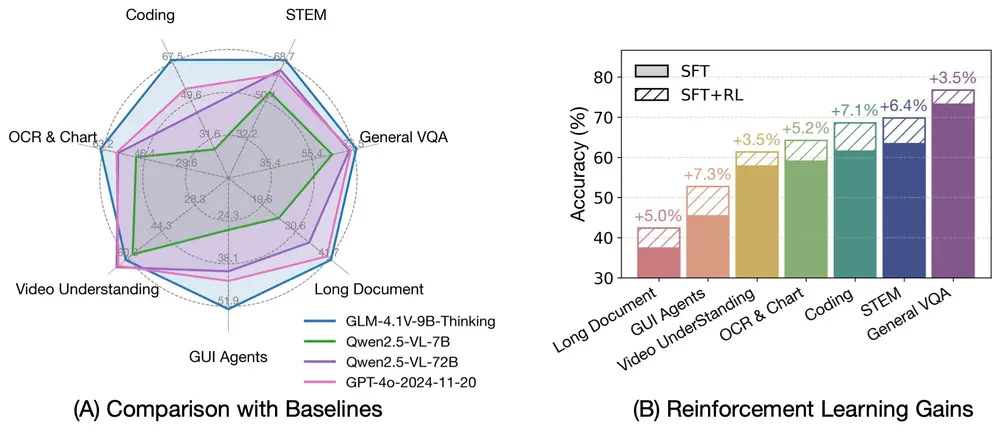
智谱AI联合清华推出新一代视觉语言推理模型开源 GLM-4.1V-9B-Thinking随着智能任务日益复杂,视觉语言大模型(VLM)正从基础的多模态感知迈向更高层次的推理能力提升。为了应对这一趋势,智谱AI 与清华大学联合推出了新一代 VLM 开源模型 —— GLM-4.1V-9B-T...多模态模型# GLM-4.1V-9B-Thinking# 智谱AI8个月前03090
快手 Keye 团队发布 Kwai Keye-VL :专注短视频理解的多模态大模型快手 Keye 团队近日推出了一款全新的多模态大型语言模型(MLLM)——Kwai Keye-VL。该模型拥有 80 亿参数,专注于提升对短视频的理解能力,同时保持强大的通用视觉-语言能力。 GitH...多模态模型# Kwai Keye-VL# 多模态大模型# 快手8个月前02940
阿里 Qwen 项目组正式推出全新多模态模型Qwen VLo随着多模态大模型的不断发展,我们对技术边界的认知也在持续被刷新。从最初的 QwenVL 到如今的 Qwen2.5 VL,我们在提升模型图像理解能力方面不断取得进步。 项目主页:https://qwen...多模态模型# Qwen VLo# Qwen 项目组# 阿里巴巴8个月前02160
Jina AI推出文本嵌入模型Jina Embeddings v4:多模态多语言检索的通用嵌入模型Jina AI正式发布 jina-embeddings-v4 —— 一款全新的38亿参数通用嵌入模型,支持文本与图像输入,适用于多种检索任务。该模型在多个基准测试中表现优异,特别是在处理表格、图表等视...多模态模型# Jina AI# Jina Embeddings v4# 文本嵌入模型9个月前03890
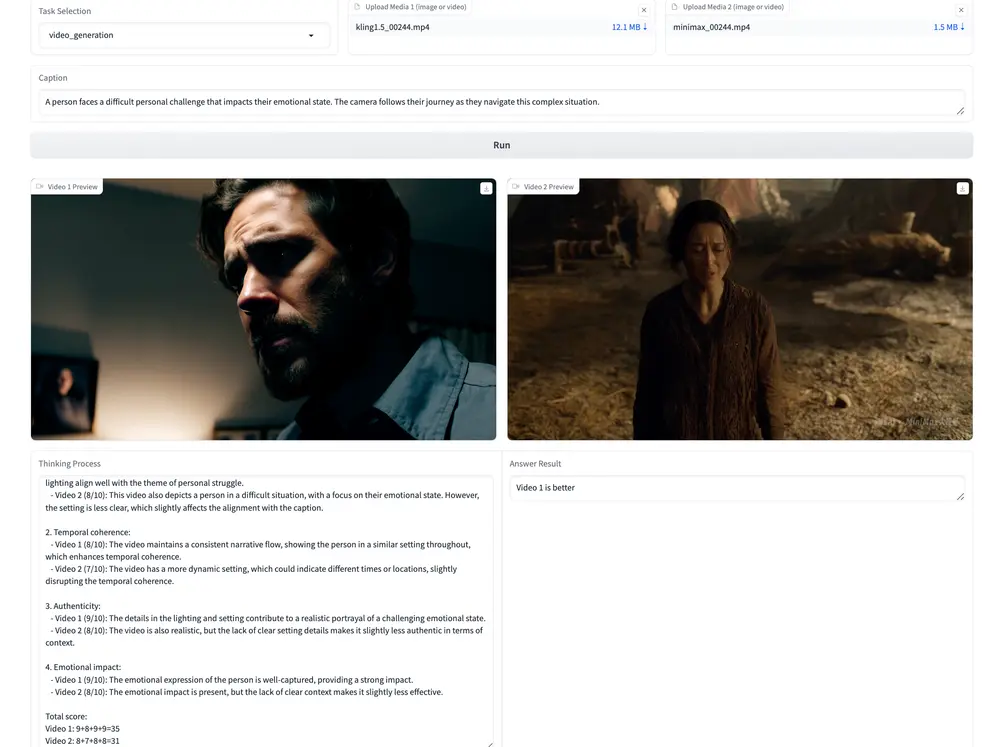
复旦联合团队发布首个统一多模态奖励模型UNIFIEDREWARD:图像视频都能评,还能优化视觉生成近日,由复旦大学、上海创新创意设计研究院、上海人工智能实验室和上海人工智能科学院组成的研究团队,正式发布了全球首个支持图像与视频理解与生成任务评估的统一奖励模型 —— UNIFIEDREWARD。 项...多模态模型# UNIFIEDREWARD# 统一多模态奖励模型9个月前04010