南大、复旦联合英伟达提出LongVie:可控超长视频生成突破1分钟,解决时间不一致难题可控超长视频生成(如生成1分钟以上、场景与动作精准可控的视频)是AI生成领域的核心挑战——现有方法在短视频生成中表现尚可,但扩展到长视频时,常出现时间不一致(帧间突变、物体位置漂移)与视觉质量下降(颜...视频模型# LongVie# 视频生成5个月前01520
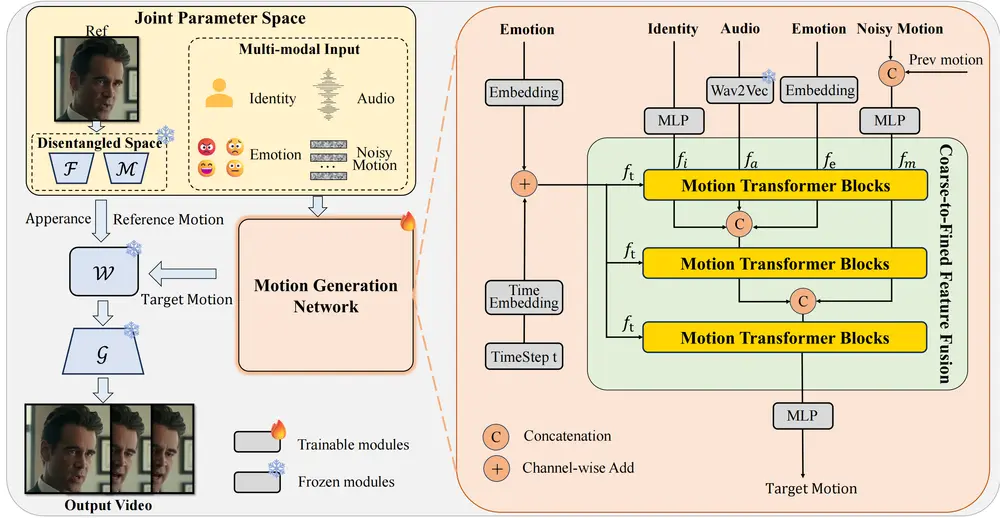
多模态扩散架构MoDA:用于生成具有任意身份和语音音频的“会说话的头像”阿里达摩院、浙江大学、湖畔实验室的研究人员推出多模态扩散架构MoDA,用于生成具有任意身份和语音音频的“会说话的头像”(talking head)。 项目主页:https://lixinyyang.g...视频模型# MoDA# 多模态5个月前01120
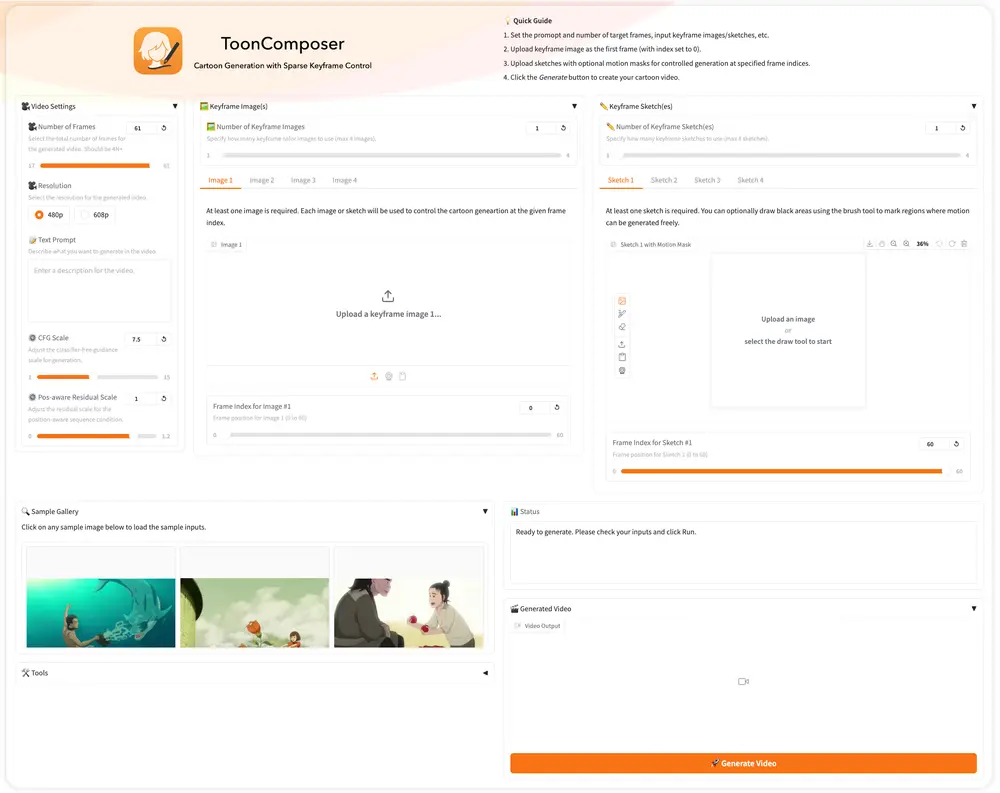
ToonComposer:通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程香港中文大学、腾讯PCG ARC Lab和北京大学的研究人员推出 ToonComposer ,通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程。传统的卡通和动画制作涉及关键帧绘...视频模型# ToonComposer# 卡通制作6个月前01,0170
视频处理引擎ViPE:用于从普通视频中估计相机运动、相机内参以及密集的度量深度图英伟达、多伦多大学、矢量研究所和德克萨斯大学奥斯汀分校的研究人员推出视频处理引擎ViPE(Video Pose Engine) ,用于从普通视频中估计相机运动、相机内参以及密集的度量深度图,能够从普通...视频模型# ViPE# 视频处理引擎6个月前02640
StableAvatar:首个端到端生成无限长度虚拟人视频的扩散模型你是否曾想过,仅凭一张静态照片和一段语音,就能让照片中的人物“开口说话”,并持续数分钟自然表达?这正是音频驱动虚拟人视频生成(Audio-Driven Talking Head Generation...视频模型# StableAvatar# 虚拟人6个月前04610
阿里发布 Omni-Effects:首个支持空间可控复合特效生成的统一框架在现代电影与视频制作中,视觉特效(VFX)是实现创意表达的核心工具。然而,传统 VFX 制作成本高昂、周期长,依赖专业团队和复杂软件。 近年来,AI 视频生成模型为 VFX 提供了更具成本效益的替代方...视频模型# Omni-Effects# 视觉特效6个月前02230
LIA-X:一种可解释的肖像动画方法,让面部动作“看得见、控得住”上海人工智能实验室和蔚蓝海岸大学的研究人员推出一种新颖的可解释肖像动画器LIA-X,旨在将驱动视频中的面部动态转移到源肖像上,并实现精细控制。 项目主页:https://wyhsirius.githu...视频模型# LIA-X# 肖像动画6个月前03240
EchoMimicV3:用一个13亿参数模型,统一处理音频、文本、图像驱动的人体动画你是否想象过这样的场景? 输入一段语音,AI 自动生成人物说话的视频,唇形精准对齐,表情自然生动; 给一张静态肖像,加上一句“他开始微笑并挥手”,画面立刻动起来; 结合提示词和参考图,生成一段人物动作...视频模型# EchoMimicV3# 人体动画6个月前02120
阿里云 PAI发布 Wan2.2-Fun:扩展Wan2.2文生视频与可控视频生成的能力边界阿里云 PAI 团队昨日正式推出 Wan2.2-Fun 系列模型,作为其 VideoX-Fun 项目的重要更新,进一步扩展了文生视频与可控视频生成的能力边界。 模型:https://huggingfa...视频模型# Wan2.2-Fun# 阿里云 PAI6个月前03250
MiniMax-Remover:港中大等联合提出高效视频目标移除新方法在视频编辑中,目标移除是一项关键任务:从视频中删除指定对象(如行人、车辆、水印),同时保持背景的视觉一致性与时间连贯性。然而,现有方法常面临三大挑战: 生成伪影或“幻觉对象” 推理速度慢,依赖高步数采...视频模型# MiniMax-Remover6个月前01730
阿里 WAN 项目组正式推出 Wan2.2:MoE 架构 + 高压缩设计,开源视频生成再进化阿里 WAN 项目组正式推出 Wan2.2,这是对 WAN 系列视频生成模型的一次重大升级。本次发布涵盖多个模型变体,全面支持文本到视频(T2V)、图像到视频(I2V)以及混合输入(TI2V)任务,在...视频模型# Wan2.2# 视频生成模型6个月前01,0340
交互式世界生成模型 Yume:通过输入图像、文本或视频来创建一个动态、逼真且可交互的世界由上海市人工智能实验室、复旦大学与上海创新研究院联合研发的新型生成模型 Yume 正式亮相。该模型旨在突破传统生成式 AI 的静态局限,构建一个可探索、可控制、高保真且动态演化的虚拟世界。 项目主页...视频模型# Yume# 交互式世界生成模型6个月前01980