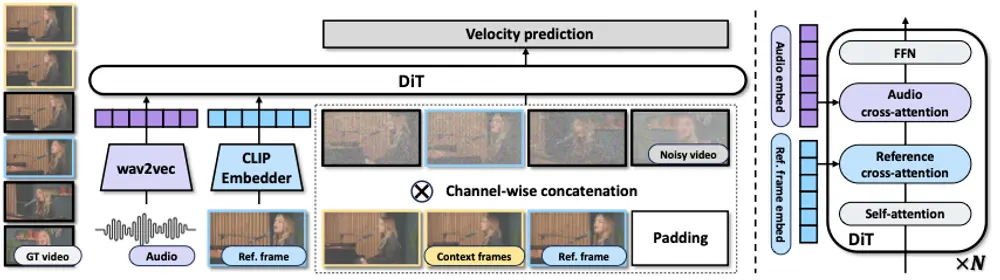
清华大学 & 字节跳动联合推出 HuMo:一个以人为中心的多模态视频生成框架一段文字描述 + 一张人物照片 + 一段语音音频,能否生成一个口型同步、动作自然、形象一致的高质量人物视频? 现在,可以了。 清华大学与字节跳动智能创作团队合作推出 HuMo(Human-Centri...视频模型# HuMo# 字节跳动5个月前0940
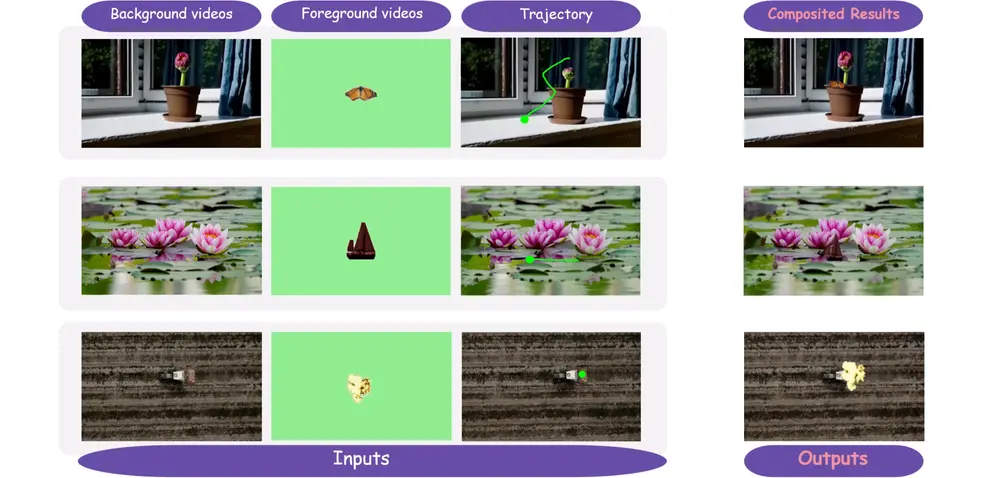
新型视频合成方法GenCompositor:实现轨迹可控的视频级前景融合由北京大学经济与管理学院、腾讯PCG ARC实验室、大湾区大学与香港中文大学联合提出的新型视频合成方法 GenCompositor,为视频创作中的“前景-背景融合”问题提供了一种自动化解决方案。该方法...视频模型# GenCompositor# 视频合成5个月前0790
Pusa Wan2.2 V1.0:将开创性的 Pusa 范式扩展到先进的 Wan2.2-T2V-A14B 架构Pusa Wan2.2 V1.0 将开创性的 Pusa 范式扩展到先进的 Wan2.2-T2V-A14B 架构,该架构采用 MoE DiT 设计,包含独立的噪声和高噪声模型。这种架构提供了增强的质量控...视频模型# Pusa Wan2.2 V1.0# Wan2.2-T2V-A14B5个月前01840
腾讯微信视觉团队发布 Stand-In:轻量级身份保持视频生成新框架在文本到视频(T2V)生成领域,一个长期存在的难题是:如何让生成的视频中的人物始终“长成你想要的样子”? 尽管现有模型能生成流畅、高质量的视频,但在身份一致性(identity-preserving...视频模型# Stand-In# 视频生成框架5个月前04600
腾讯发布混元世界模型 - Voyager:单图生成 3D 场景,实现长距离沉浸式探索腾讯今天正式推出混元世界模型 - Voyager(HunyuanWorld-Voyager),这是一款创新的视频扩散框架。其核心能力在于:基于单张输入图像即可生成具备世界一致性的 3D 点云,支持用户...视频模型# HunyuanWorld-Voyager# 混元世界模型 - Voyager# 腾讯5个月前0700
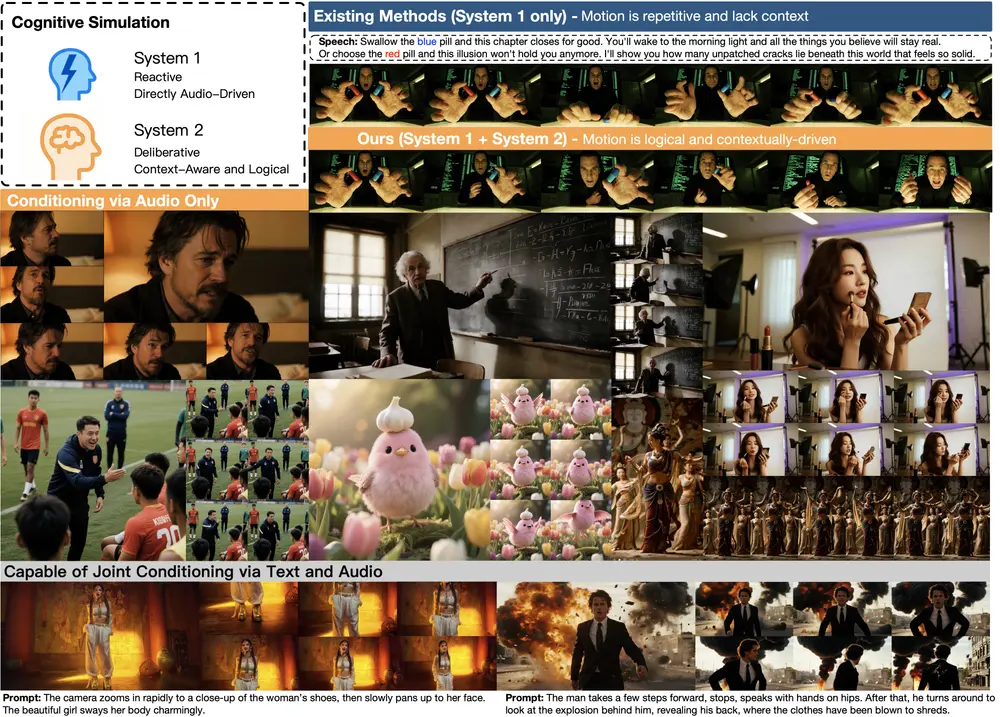
字节跳动发布OmniHuman-1.5:模拟人类双重认知,生成语义连贯的高逼真角色动画字节跳动近期推出新型视频角色生成框架 OmniHuman-1.5,核心突破在于模拟人类“系统1(快速直觉反应)+系统2(缓慢深思规划)”的双重认知过程,实现从“单一图像+语音轨道”到“物理逼真、语义连...视频模型# OmniHuman-1.5# 字节跳动5个月前0720
InfiniteTalk:支持稀疏帧输入的全动态音频驱动视频生成,实现全身协调的说话视频生成在虚拟人、影视后期、跨语言内容本地化等场景中,理想的配音技术不仅要实现精准的唇部同步,还需让头部运动、面部表情、身体姿态自然地跟随语音节奏变化,同时保持人物身份一致性。 项目主页:https://me...视频模型# InfiniteTalk# 对口型5个月前01020
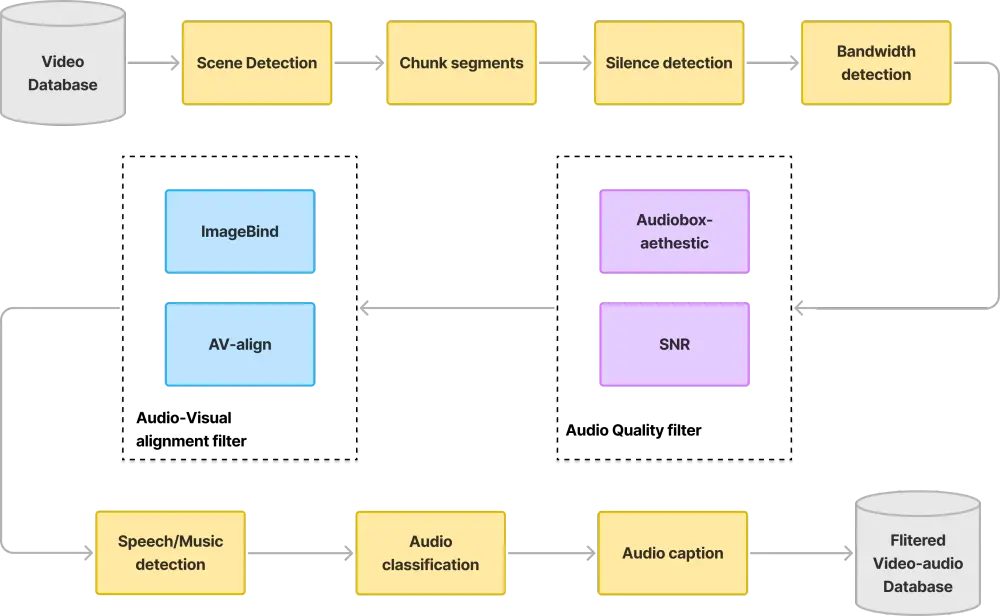
腾讯开源混元视频音效生成模型HunyuanVideo-Foley:端到端TV2A模型,为创作者打造高保真音视频体验腾讯今天正式开源 HunyuanVideo-Foley —— 一个端到端的文本-视频-音频(Text-Video-to-Audio, TV2A)生成模型,专注于为视频内容自动生成高保真、语义对齐的音效...视频模型# HunyuanVideo-Foley# 混元视频音效生成模型# 腾讯5个月前0930
阿里开源 Wan2.2-S2V-14B:输入一张图 + 一段音频,生成电影级数字人视频阿里Wan团队正式开源音频驱动视频生成模型Wan2.2-S2V-14B。这款模型打破了传统视频生成对复杂输入的依赖——用户仅需提供一张静态图像与一条音频,即可生成面部表情自然、口型精准同步、肢体动作流...视频模型# Wan2.2-S2V-14B# 数字人# 阿里5个月前04910
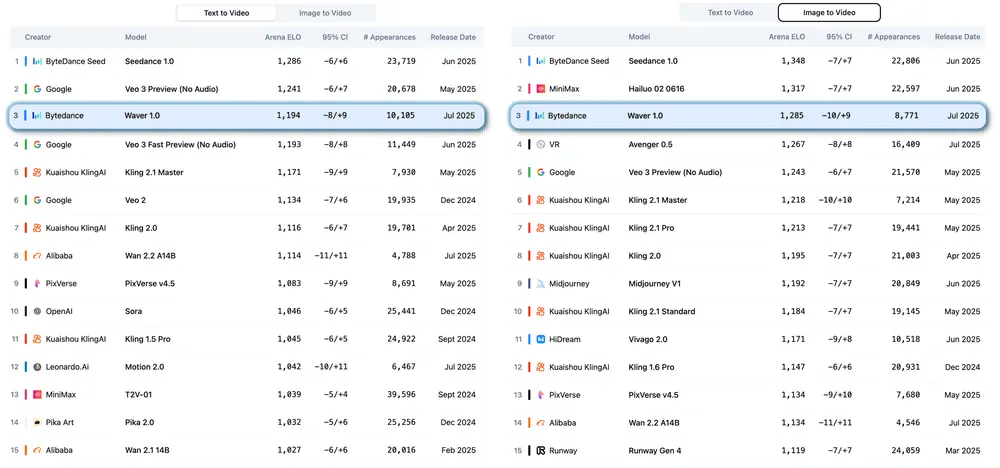
字节跳动 Waver 项目组推出一体化视频生成模型Waver 1.0:同时支持文生图、图生视频及文生图生成字节跳动 Waver 项目组近期正式推出 Waver 1.0 一体化视频生成模型,凭借多模态生成能力、高分辨率支持及卓越的运动建模效果,在视频生成领域实现重要突破,为工业级视频创作需求提供了全新解决方...视频模型# Waver 1.0# 字节跳动# 视频生成5个月前06080
阿里淘天 推出基于 DiT 的生成式视频修复方法Vivid-VR:概念蒸馏 + 双分支控制实现高纹理与时间连贯老旧视频模糊、噪点多、细节丢失,能否通过 AI 实现自然且真实的画质增强? 传统视频修复方法往往在提升分辨率的同时,引入伪影、纹理失真或帧间抖动。而基于扩散模型的新一代生成技术,虽然具备强大的细节生成...视频模型# Vivid-VR# 视频修复5个月前04150
解决高分辨率生成痛点:CineScale 新范式优化扩散模型,支持 8K 图像与 4K 视频合成视觉扩散模型虽已取得显著进展,但受限于“高分辨率训练数据稀缺”与“计算资源消耗大”,多数模型只能在低分辨率(如512×512)下训练,导致生成高保真图像、视频时容易出现“重复模式”“细节模糊”等问题...视频模型# CineScale# 高分辨率生成5个月前03150