TurboDiffusion:视频扩散模型提速 100–200 倍,质量几乎无损视频扩散模型虽能生成高质量内容,但其缓慢的推理速度长期制约实际应用。近日,清华大学、生数科技与加州大学伯克利分校联合提出 TurboDiffusion——一个端到端视频生成加速框架,在单张 RTX 5...视频模型# TurboDiffusion# Wan2.21个月前0240
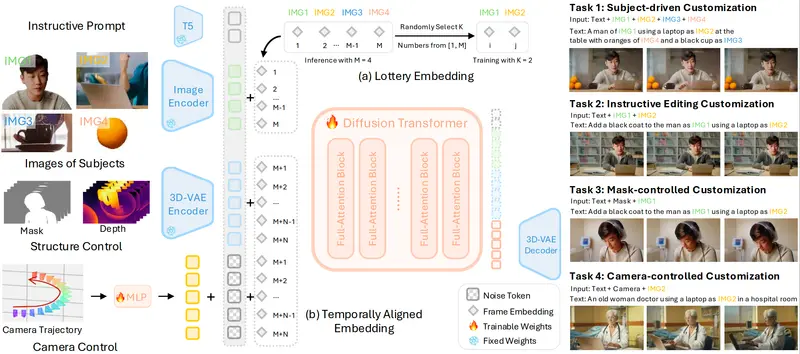
OmniVCus:用多模态控制信号实现前馈式主题驱动视频定制在视频生成领域,一个长期挑战是:如何让用户通过简单指令(如文本、草图或相机轨迹),灵活定制视频中一个或多个主体的外观、动作与空间关系? 由约翰·霍普金斯大学、Adobe 研究院、香港大学、香港中文大学...视频模型# OmniVCus# 视频1个月前0210
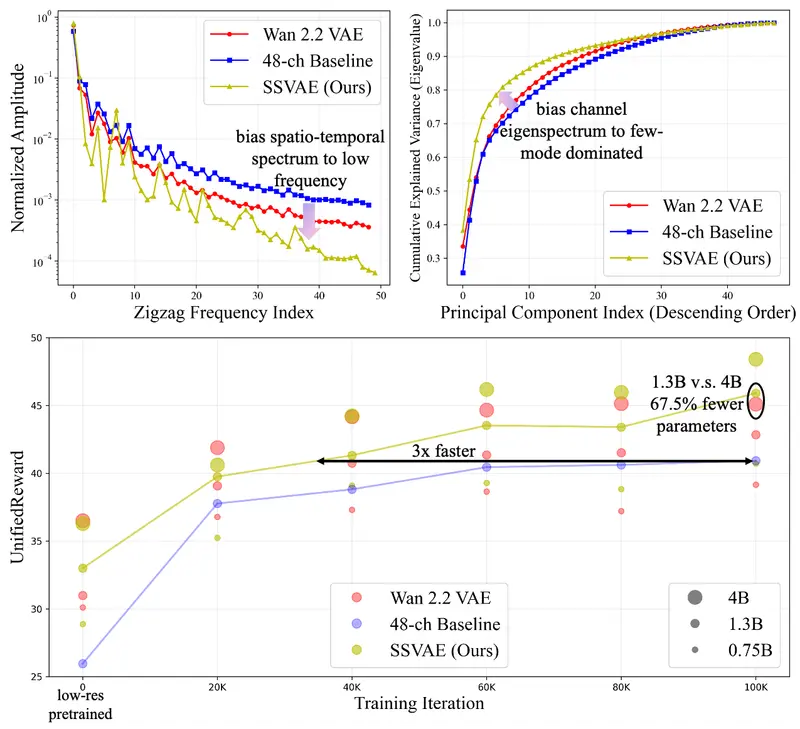
智谱AI提出 SSVAE:通过谱结构优化提升视频VAE“可扩散性”的新方法在基于扩散模型的视频生成系统中,视频变分自编码器(VAE) 扮演着关键角色:它将像素空间视频压缩到潜在空间,供扩散模型高效训练。然而,现有视频 VAE 的设计往往过度聚焦于重建保真度,却忽视了一个更根...视频模型# SSVAE# 智谱AI2个月前0200
美团 LongCat 发布统一音频驱动视频模型LongCat-Video-Avatar:支持长视频、多模态输入与多人物动画音频驱动的人类视频合成(Audio-Driven Talking Head)近年来在唇形同步和画面逼真度上取得显著进展。但生成长时间、高动态、身份一致的视频仍是行业难题:现有方法要么在长序列中出现身份...视频模型# LongCat-Video-Avatar# 美团1个月前0190
Lightricks发布LTX-2:首个基于 DiT 的开源音视频基础模型Lightricks发布了首个基于 Diffusion Transformer(DiT) 架构的开源音视频联合生成模型LTX-2。它在一个统一框架中集成了现代视频生成的核心能力:同步的音频与视频输出...视频模型# Lightricks# LTX-2# 音视频模型4周前0170
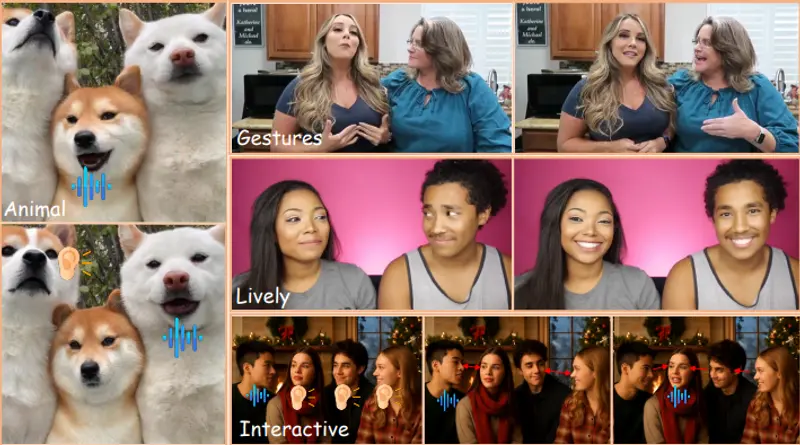
AnyTalker:用单人数据生成自然互动的多人对话视频多人对话视频的自动生成,长期以来受限于两个关键难题:一是高质量多人视频数据极难获取,二是多个角色之间的互动行为难以建模。为解决这些问题,来自香港科技大学、Video Rebirth、浙江大学和北京交通...视频模型# AnyTalker2个月前0170
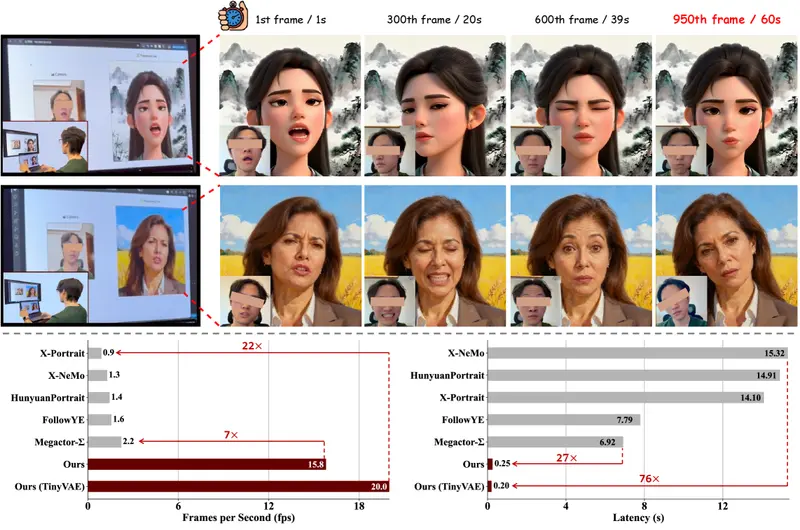
PersonaLive:基于扩散模型的实时肖像动画系统,延迟仅0.25秒在数字人、虚拟主播和直播场景中,高质量、低延迟、身份一致的肖像动画是核心需求。然而,主流扩散模型虽能生成逼真画面,却因高计算成本与多步去噪,难以满足实时交互要求——生成一段3秒视频往往需要数十秒,远不...视频模型# PersonaLive# 肖像动画1个月前0160
巨人网络AI实验室推出YingVideo-MV:音乐驱动的多阶段视频生成框架,让 AI 会“演”一首歌巨人网络AI实验室推出 YingVideo-MV,这是一个用于音乐驱动的多阶段视频生成框架,能够从音频信号中自动生成高质量的音乐表演视频。YingVideo-MV 集成了音频语义分析、可解释的镜头规划...视频模型# YingVideo-MV2个月前0140
UniVideo:滑铁卢大学与快手推出统一视频生成与编辑模型,支持理解、生成、编辑一体化长久以来,视频 AI 能力被割裂为多个独立任务: 理解:靠视觉语言模型(如 Qwen-VL) 生成:依赖扩散模型(如 Sora、HunyuanVideo) 编辑:需专门的编辑网络或掩码引导 这种碎片化...视频模型# UniVideo# 视频生成# 视频编辑3周前0130
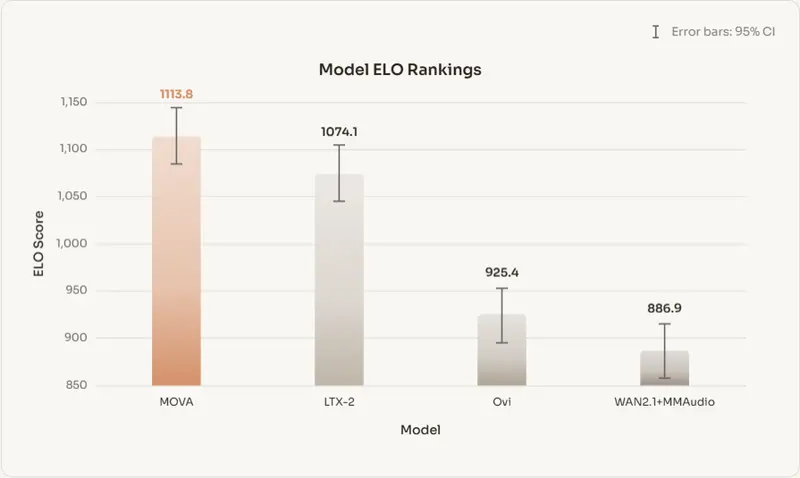
新模思智能推出 MOVA:开源同步音视频生成基座模型,打破“无声视频”困局模思智能正式开源 MOVA(MOSS Video and Audio)——一款专注于原生同步生成视频与音频的基座模型。针对当前主流系统(如 Sora 2、Veo 3)普遍采用的“先画后音”级联流程,M...视频模型# MOVA# 模思智能19小时前040