清华、腾讯等联合推出基于语言模型的高质量歌曲生成框架 LeVo随着大语言模型(LLMs)和音频语言模型的快速发展,AI 在音乐生成领域的能力显著提升,特别是在 歌词到歌曲生成 的方向上取得了突破性进展。 然而,现有方法仍面临两大核心挑战: 歌曲结构复杂,难以同时...语音模型# LeVo# SongGeneration# 音乐生成8个月前02510
音频描述数据集FusionAudio-1.2M:通过多模态上下文融合来生成细粒度的音频描述香港中文大学(深圳)和华南理工大学的研究人员推出推出一个名为FusionAudio-1.2M的音频描述数据集,通过多模态上下文融合来生成细粒度的音频描述。该数据集通过模拟人类听觉感知的方式,整合了多种...语音模型# FusionAudio-1.2M8个月前01680
昆仑万维推出 SkyReels-Audio:多模态驱动、无限长度的高质量会说话肖像视频生成框架昆仑万维旗下 SkyReels 团队 发布了全新音视频生成模型——SkyReals-Audio,一个用于合成高保真、时间一致的“会说话”肖像视频的统一框架。 项目主页:https://skyworka...语音模型# SkyReels-Audio# 昆仑万维8个月前02580
Vui:轻量级、可本地运行的开源对话语音模型Vui 是一组轻量级、可本地运行的开源对话语音模型,支持设备端部署,适用于对话生成、语音克隆及非语音声音合成等任务。 GitHub:https://github.com/fluxions-ai/vui...语音模型# Vui# 对话语音模型8个月前03540
Fish Audio 发布 OpenAudio S1-mini:支持 14 种语言、50+ 情感语气的开源 TTS 模型文本转语音(TTS)领域迎来一位重量级开源选手 —— OpenAudio S1-mini。 这是由 Fish Audio 团队 推出的 S1 模型的轻量化版本,参数规模为 5亿(0.5B),基于超过 ...语音模型# Fish Audio# OpenAudio S1-mini# TTS 模型8个月前06710
OpenAudio S1:Fish Audio 推出媲美语音演员的尖端文本转语音模型Fish Audio 重磅推出 OpenAudio S1 —— 一款在表现力、自然度和可控性方面达到新高度的文本转语音(TTS)模型。作为目前全球最先进的开源 TTS 模型之一,S1 在超过 200万...语音模型# Fish Audio# OpenAudio S1# TTS模型8个月前03750
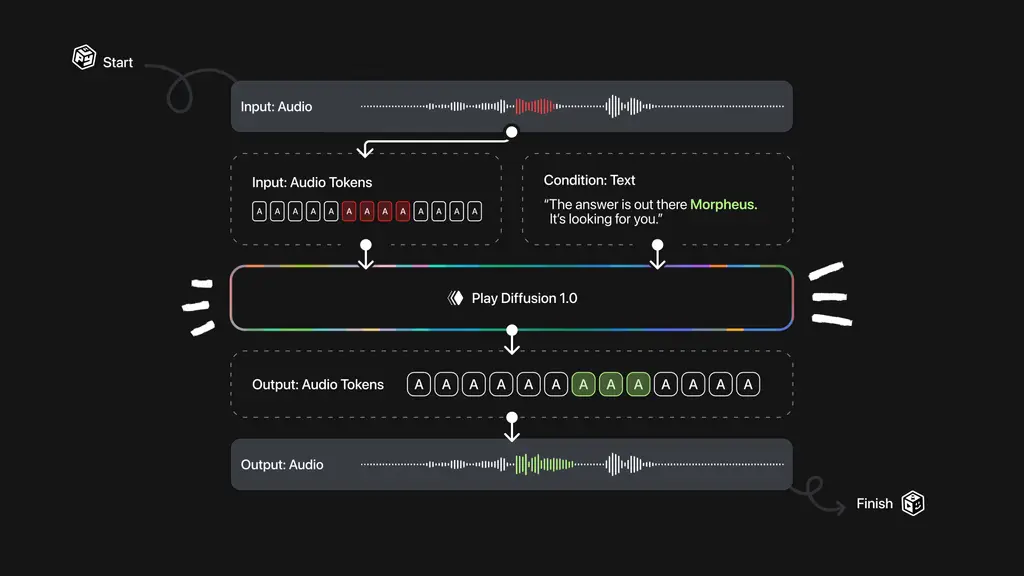
PlayAI 推出基于扩散机制的新型音频编辑模型 PlayDiffusion:能够实现对已有语音片段的精准修改,无需重新生成整段语音在语音合成领域,自回归变换器模型已被广泛应用于文本转语音(TTS)任务中,并取得了显著成果。然而,这些模型在处理一个关键问题时存在明显短板:如何在生成后的音频中进行局部修改(即“修补”),而不会破坏整...语音模型# PlayDiffusion# 音频编辑模型8个月前03750
Resemble AI推出首个情感可控的开源TTS模型ChatterboxResemble AI正式发布了其首个生产级开源TTS模型——Chatterbox。这是目前市面上少有的、具备高质量语音合成能力并支持情感控制的开源项目。目前仅支持英文。 GitHub:https...语音模型# Chatterbox# Resemble AI# TTS模型5个月前03230
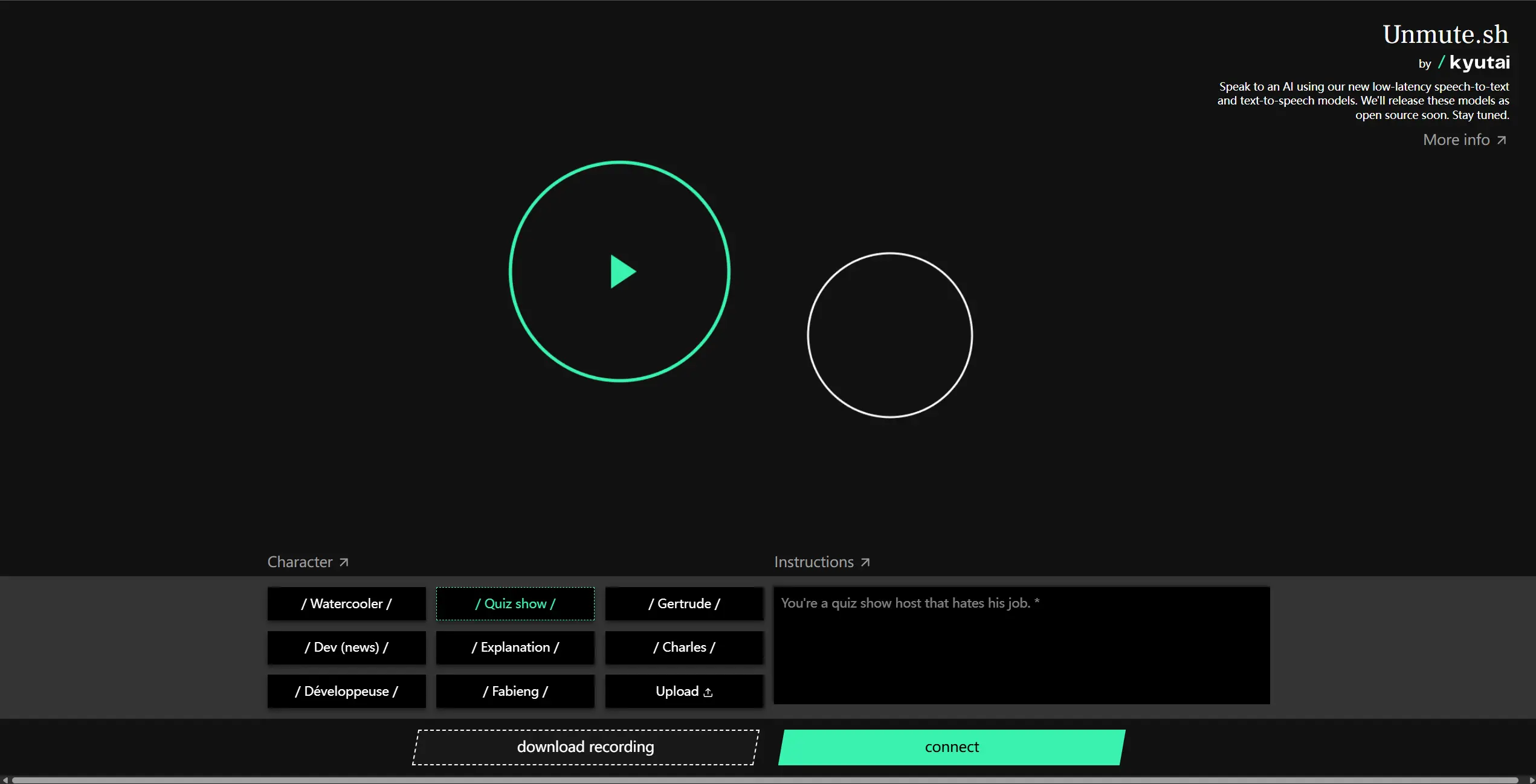
Kyutai 推出全新语音系统Unmute,让任何大模型都能“说话”Kyutai 近日发布了一款名为 Unmute 的全新语音 AI 系统。与以往语音模型不同,Unmute 并不试图替代现有的语言模型,而是作为一个高度模块化的“插件”,可以无缝接入任意文本大语言模型...语音模型# Kyutai# Unmute# 语音模型8个月前01480
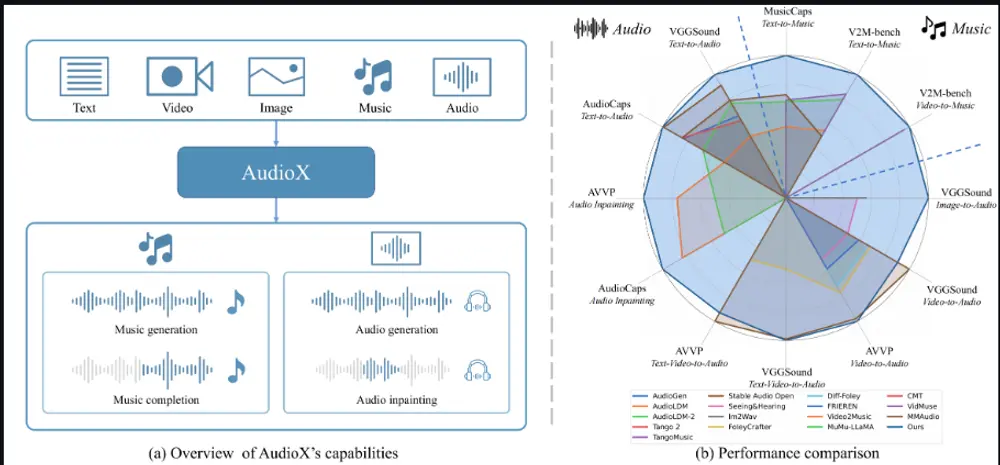
新型多模态音频生成框架AudioX:通过统一的模型架构实现从各种输入模态(如文本、视频、图像、音频等)生成高质量的音频和音乐香港科技大学的研究人员推出新型多模态音频生成框架“AudioX”,通过统一的模型架构实现从各种输入模态(如文本、视频、图像、音频等)生成高质量的音频和音乐。该框架通过创新的多模态掩码训练策略,强制模型...语音模型# AudioX# 多模态音频生成8个月前01750
高效语音分离模型TIGER:解决低延迟语音处理系统中的高效率问题清华大学的研究人员推出高效语音分离模型TIGER,解决低延迟语音处理系统中的高效率问题。语音分离是指从混合音频信号中准确分离出不同声音源的任务,类似于人类在嘈杂环境中专注于特定语音信号的“鸡尾酒会效应...语音模型# TIGeR# 语音分离模型8个月前03200
Stability AI发布可在智能手机运行的音频生成模型Stable Audio Open SmallAI 初创公司 Stability AI 发布了 Stable Audio Open Small,这是一款专为移动设备设计的音频生成模型。据公司宣称,这是目前市场上最快的音频生成模型,并且效率高到可以...语音模型# Stability AI# Stable Audio Open Small9个月前02150