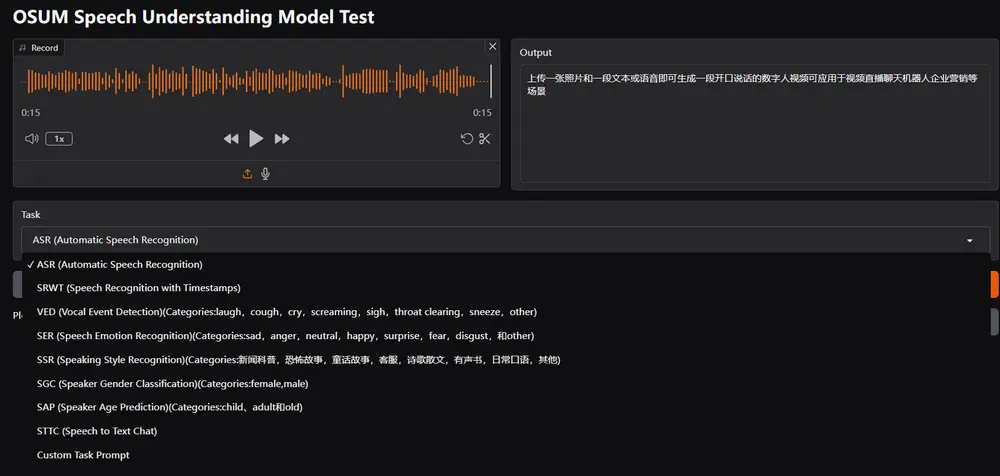
西北工业大学开源语音理解模型OSUM近年来,大语言模型(LLMs)在自然语言处理领域取得了显著进展,这启发了业界对语音理解语言模型(Speech Understanding Language Models, SULMs)的开发。SULM...语音模型# OSUM# 西北工业大学# 语音理解模型11个月前04100
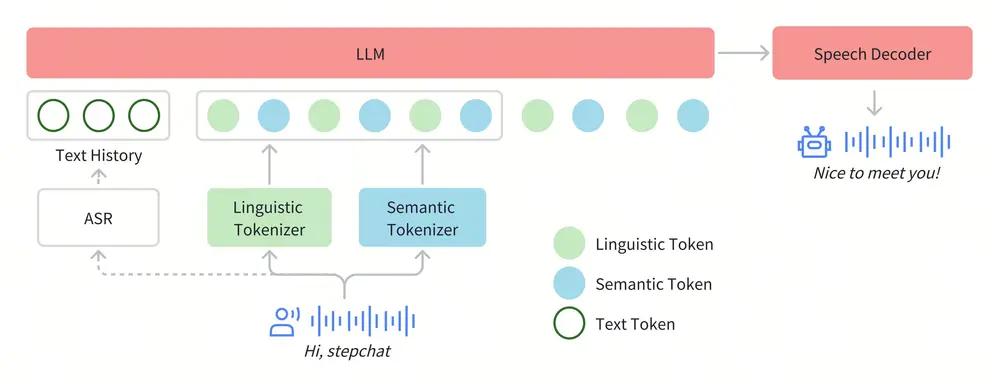
新型语音语言基础模型Voila :实现自然、实时、自主的语音交互Maitrix.org、加州大学圣地亚哥分校和MBZUAI的研究人员推出新型语音语言基础模型Voila ,旨在实现自然、实时、自主的语音交互。Voila 通过端到端的架构设计,突破了传统语音交互系统...语音模型# Voila# 语音语言基础模型9个月前04070
IBM 首个开源的语音转文本(STT)和自动语音翻译(AST)模型Granite Speech 3.3 8B随着AI在企业系统中的深度集成,对灵活性、效率和透明度兼具的模型需求日益增加。然而,当前市场上的解决方案往往难以满足这些要求:开源模型可能缺乏特定领域的能力,而专有系统则可能限制访问或适应性。尤其在语...语音模型# AST# Granite Speech 3.3 8B# IBM9个月前03910
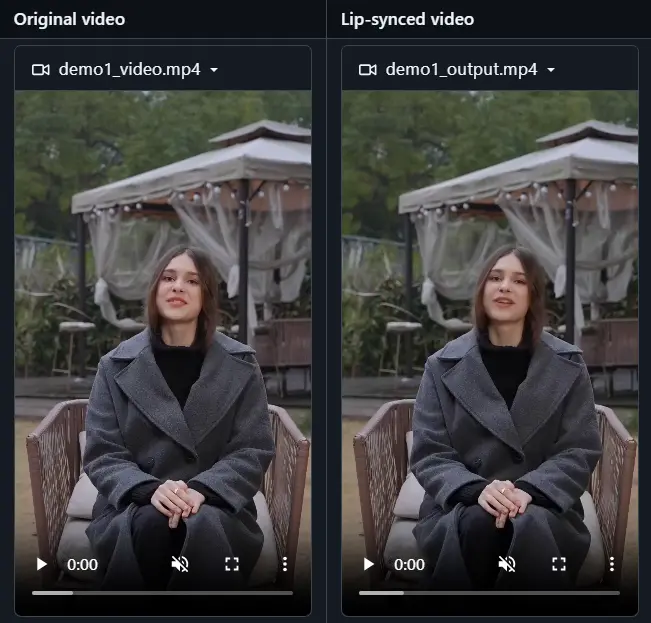
端到端唇音同步框架LatentSync:可以分析新的音频信号,并生成与音频同步的口型字节跳动与北京交通大学的研究团队共同提出了一种名为LatentSync的新方法,旨在解决唇音同步的问题。这一框架利用了Stable Diffusion的强大能力,通过一个端到端的流程直接建模复杂的音视...语音模型# LatentSync# 唇音同步12个月前03880
阿里通义项目组更新 Qwen-TTS:合成语音自然度接近人类水平阿里通义实验室通过 Qwen API 发布了最新版本的 Qwen-TTS 语音合成模型(支持 qwen-tts-latest 或 qwen-tts-2025-05-22)。该模型在语音合成领域实现了多...语音模型# Qwen-TTS7个月前03830
FlashLabs推出Chroma 1.0:首个开源实时语音对话模型,支持低延迟个性化语音克隆在虚拟人交互与语音合成领域,兼顾低延迟、高保真语音克隆、多轮对话理解的模型一直是技术难点。由FlashLabs开发的 Chroma 1.0 正是一款突破性的多模态因果语言模型,它不仅能直接处理音频输入...语音模型# Chroma# FlashLabs# 实时语音对话模型1周前03800
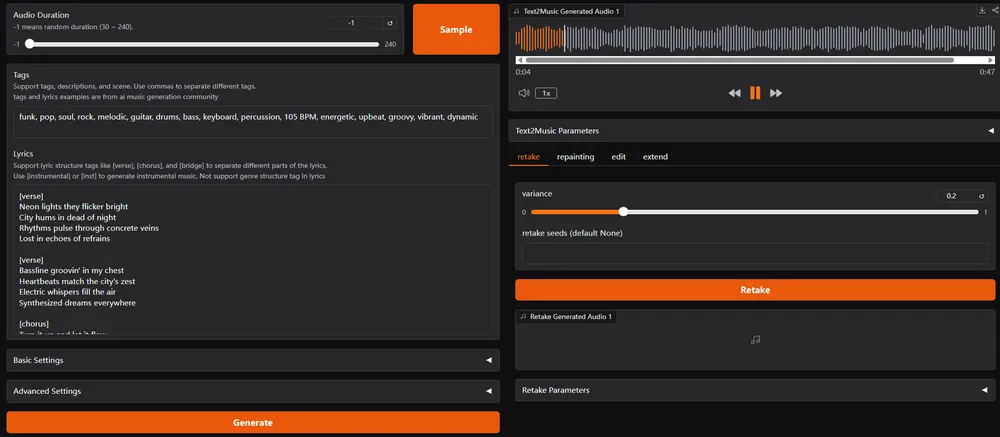
音乐生成基础模型ACE-Step:通过创新的整体架构设计,快速生成高质量音乐ACE Studio和阶跃星辰(StepFun)联合推出了一款全新的开源音乐生成基础模型ACE-Step,该模型通过创新的整体架构设计,突破了现有方法的局限性,实现了卓越的性能表现。 GitHub:h...语音模型# ACE-Step# 音乐模型9个月前03780
OpenAudio S1:Fish Audio 推出媲美语音演员的尖端文本转语音模型Fish Audio 重磅推出 OpenAudio S1 —— 一款在表现力、自然度和可控性方面达到新高度的文本转语音(TTS)模型。作为目前全球最先进的开源 TTS 模型之一,S1 在超过 200万...语音模型# Fish Audio# OpenAudio S1# TTS模型8个月前03750
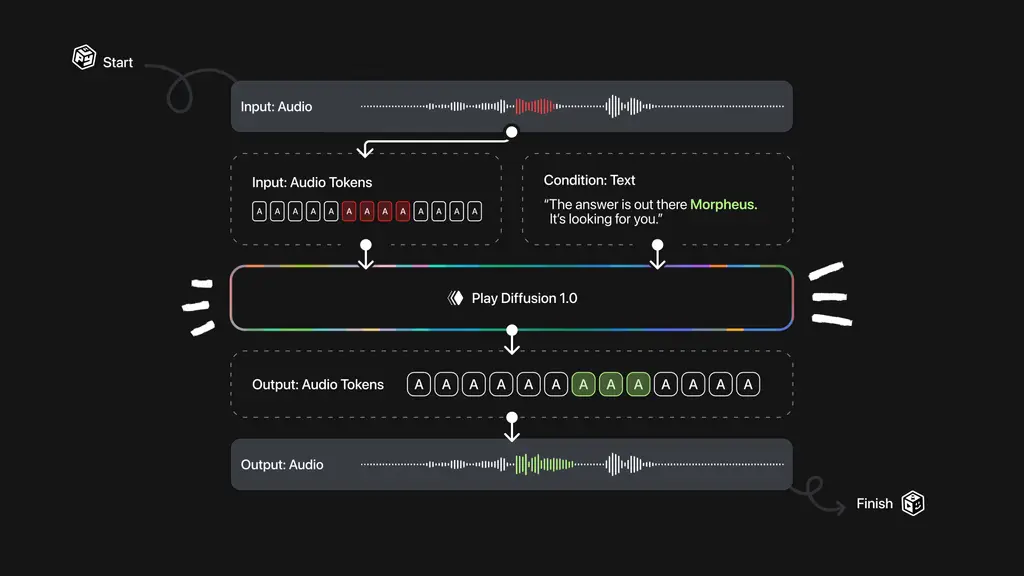
PlayAI 推出基于扩散机制的新型音频编辑模型 PlayDiffusion:能够实现对已有语音片段的精准修改,无需重新生成整段语音在语音合成领域,自回归变换器模型已被广泛应用于文本转语音(TTS)任务中,并取得了显著成果。然而,这些模型在处理一个关键问题时存在明显短板:如何在生成后的音频中进行局部修改(即“修补”),而不会破坏整...语音模型# PlayDiffusion# 音频编辑模型8个月前03750
Vui:轻量级、可本地运行的开源对话语音模型Vui 是一组轻量级、可本地运行的开源对话语音模型,支持设备端部署,适用于对话生成、语音克隆及非语音声音合成等任务。 GitHub:https://github.com/fluxions-ai/vui...语音模型# Vui# 对话语音模型8个月前03540
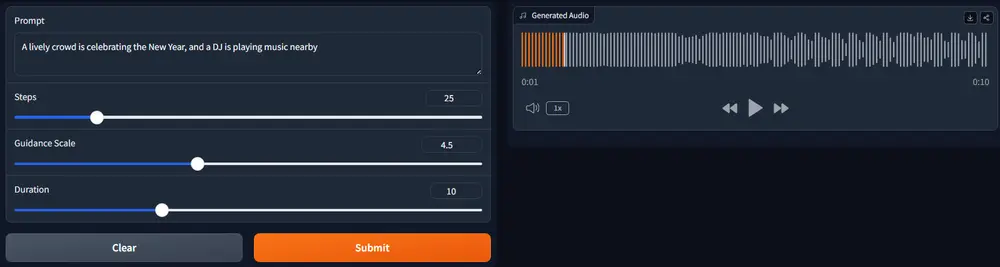
文本到音频生成模型TANGOFLUX:从文本描述中快速、忠实地生成高质量的音频内容随着人工智能技术的发展,文本到音频(TTA)生成模型正在逐渐改变我们与数字内容互动的方式。然而,创建高质量且自然的音频输出仍然是一个复杂的技术挑战,尤其是在对齐模型以产生符合人类期望的音频方面。新加坡...语音模型# TANGOFLUX# 文本到音频生成模型6个月前03480
阶跃星辰开源面向智能语音交互的框架Step-Audio:1300 亿参数的统一语音-文本多模态模型,能够实现语音理解与生成的统一阶跃星辰团队开源了面向智能语音交互的框架 Step-Audio,旨在解决当前开源语音模型在数据收集成本高、动态控制能力弱和智能水平有限等问题。Step-Audio 提出了一个 1300 亿参数的统一语...语音模型# Step-Audio# 语音-文本多模态模型# 语音交互12个月前03420