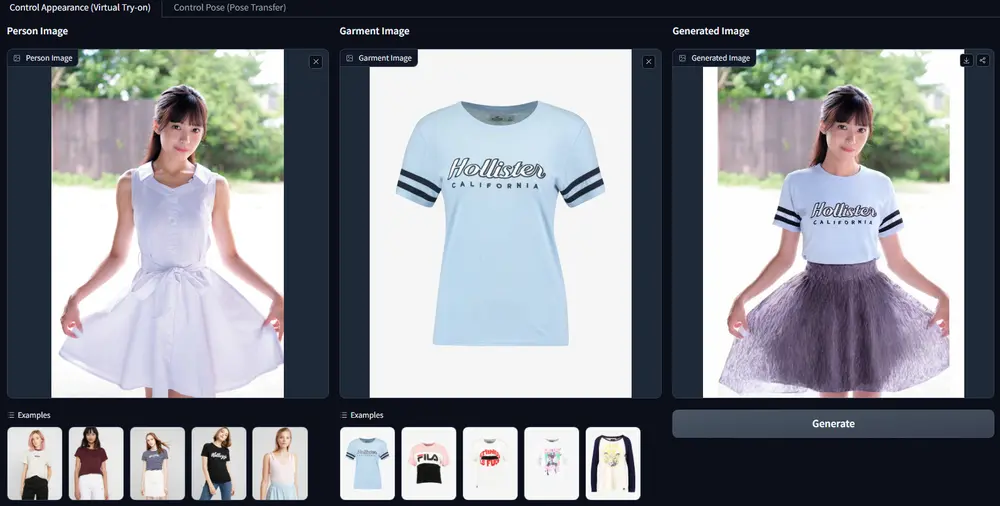
Leffa:通过参考图像生成人物图像,允许对人物的外观或姿势进行精确控制可控人物图像生成的目标是根据参考图像生成高质量的人物图像,同时允许对人物的外观或姿势进行精确控制。尽管现有的方法在整体图像质量上取得了显著进展,但它们往往会在生成过程中扭曲参考图像中的细粒度纹理细节...图像模型# Leffa# 虚拟试穿12个月前03190
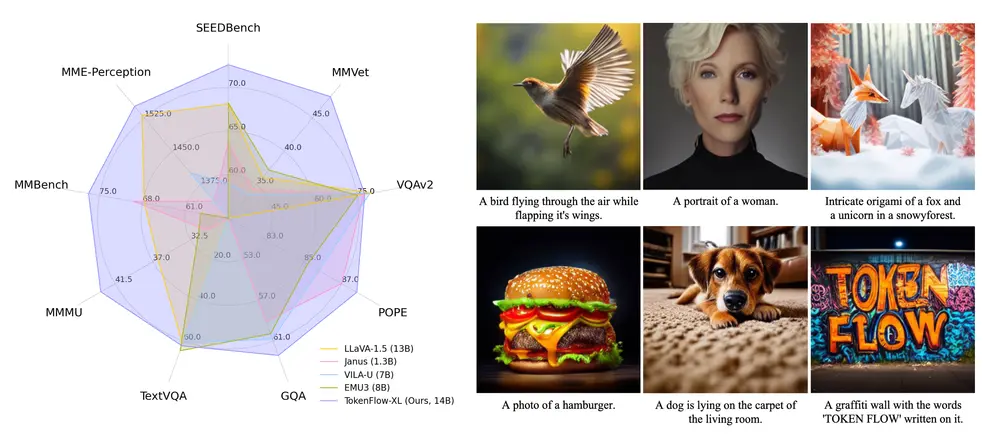
字节跳动推出新型统一图像标记器TokenFlow:弥合多模态理解和生成之间的长期存在的差距字节跳动的研究团队提出了TokenFlow,这是一种新颖的统一图像标记器,旨在弥合多模态理解和生成之间的长期存在的差距。先前的方法尝试使用单一的重建导向向量量化(VQ)编码器来统一这两项任务,但这种做...图像模型# TokenFlow# 统一图像标记器12个月前03190
自动T2I生成系统ChatGen:以自由聊天的形式简单描述需求,从而轻松获得高质量的图像尽管文本到图像(T2I)生成模型在近年来取得了显著进展,用户在实际应用中仍然面临着诸多挑战。制作合适的提示、选择适当的模型和配置特定参数等繁琐步骤的复杂性和不确定性,使得用户不得不通过反复试验来获得满...图像模型# ChatGen12个月前03190
SANA模型的升级版SANA 1.5:实现高质量的图像生成,同时显著降低了训练和推理成本英伟达、麻省理工学院、清华大学、Playground和北京大学的研究团队推出了SANA模型的升级版SANA 1.5,这是一款高效的DiT架构模型,通过创新的训练和推理策略,实现文本到图像生成任务中的高...图像模型# DiT架构模型# SANA 1.5# 文生图模型11个月前03130
字节跳动发布 Seedream 4.0:首次支持多模态生图,同一模型实现 文生图、图像编辑、组图生成字节跳动正式推出 Seedream 4.0(即梦图片4.0),新一代图像创作模型。该模型在前代 Seedream 3.0 和 SeedEdit 3.0 的基础上,全面增强逻辑理解与多模态推理能力,首次...图像模型# Seedream 4.0# 即梦图片4.0# 字节跳动5个月前03100
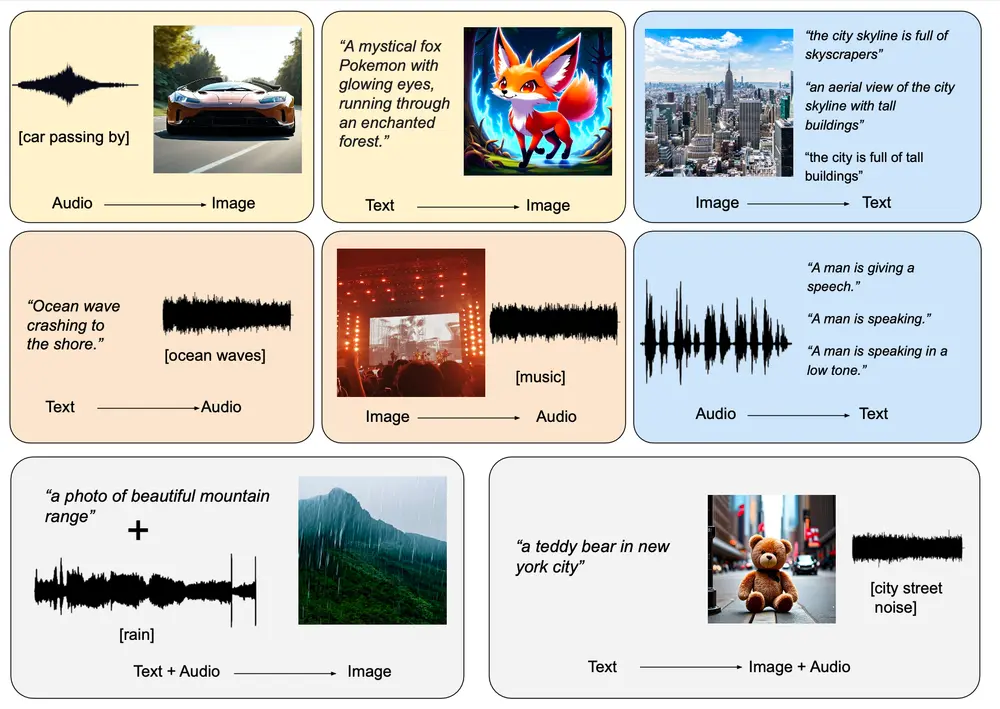
新型生成模型OmniFlow:用于处理任何到任何(any-to-any)的多模态生成任务,例如文本到图像、文本到音频以及音频到图像的合成加州大学洛杉矶分校、松下AI研究院和Salesforce AI研究院的研究人员共同提出了OmniFlow,这是一种新颖的生成模型,专为处理“任何到任何”(any-to-any)生成任务设计,如文本到图...图像模型# OmniFlow# 多模态生成12个月前03100
Science-T2I框架:通过整合科学知识,提升图像合成模型生成图像的现实感和科学一致性纽约大学、华盛顿大学、宾夕法尼亚大学和 加州大学圣地亚哥分校介绍了一个名为 Science-T2I 的框架,旨在通过整合科学知识,提升图像合成模型生成图像的现实感和科学一致性。该研究的核心是解决现有图...图像模型# Science-T2I# 图像生成模型# 科学9个月前03090
专注于精确角色细节转录的线稿上色模型MangaNinja香港大学、香港科技大学、通义实验室和蚂蚁集团的研究人员合作推出了一款专注于精确角色细节转录的线稿上色模型——MangaNinja。MangaNinja专门用于将线稿图像转换为彩色图像,同时保持与参考图...图像模型# MangaNinja# 线稿上色模型12个月前03080
腾讯混元项目组联合北京大学提出新框架MixGRPO:用混合微分方程提升图像对齐效率在图像生成领域,如何让模型输出更符合人类审美与偏好,已成为对齐研究的核心目标。基于流匹配(Flow Matching)的生成模型近年来展现出强大潜力,而 Group Relative Policy O...图像模型# MixGRPO6个月前03060
新型插件式适应方法EasyRef:允许扩散模型根据多个参考图像和文本提示进行条件生成在个性化生成任务中,扩散模型(Diffusion Models)已经取得了显著的成就。传统的无需调优的方法通常通过平均多个参考图像的图像嵌入作为注入条件来编码,但这种与图像无关的操作无法在图像之间进行...图像模型# EasyRef# 扩散模型12个月前03050
北京人工智能研究院推出新一代统一多模态图像生成模型OmniGen2:视觉理解、文本到图像生成、指令驱动编辑和基于主体的上下文生成能力在上一代模型 OmniGen 发布仅 7 个月后,北京人工智能研究院正式推出了其升级版——OmniGen2,一个集成了视觉理解、文本到图像生成、指令驱动编辑和基于主体的上下文生成能力的统一多模态模型...图像模型# OmniGen2# 北京人工智能研究院# 统一多模态图像生成7个月前03030
字节跳动发布OneReward 框架:用单一奖励模型革新多任务图像编辑在图像生成领域,AI 已经能完成许多复杂操作:补全残缺画面、扩展图像边界、移除干扰物体,甚至在图中添加可读文本。但这些任务通常由不同模型分别处理——每个任务有自己的训练流程、评估标准和奖励机制。 这带...图像模型# FLUX.1-Fill-dev-OneReward# OneReward# 字节跳动5个月前02990