
在图像生成领域,如何让模型输出更符合人类审美与偏好,已成为对齐研究的核心目标。基于流匹配(Flow Matching)的生成模型近年来展现出强大潜力,而 Group Relative Policy Optimization(GRPO)等强化学习式对齐方法,进一步提升了生成结果的主观质量。
然而,现有方法如 FlowGRPO 和 DanceGRPO 存在一个共性瓶颈:它们将整个去噪过程建模为马尔可夫决策过程(MDP),并在所有时间步上进行采样与梯度优化。这种全路径优化带来了高昂的计算成本,严重制约了训练效率。

针对这一问题,腾讯混元项目组联合北京大学提出了一种新框架——MixGRPO,通过融合随机微分方程(SDE)与常微分方程(ODE) 的采样机制,引入滑动窗口内的局部优化策略,在不牺牲性能的前提下,显著降低训练开销。
- 项目主页:https://tulvgengenr.github.io/MixGRPO-Project-Page
- GitHub:https://github.com/Tencent-Hunyuan/MixGRPO
- 模型:https://huggingface.co/tulvgengenr/MixGRPO
实验表明,MixGRPO 相比 DanceGRPO 训练时间减少近 50%,其高速变体 MixGRPO-Flash 更是实现了 71% 的训练耗时压缩,同时在多个偏好对齐指标上实现反超。

问题背景:全路径优化为何低效?
在基于流匹配的图像生成中,模型通过逐步去噪从噪声数据恢复出目标图像。GRPO 类方法将这一过程视为强化学习任务,利用人类偏好数据构建奖励信号,指导模型生成更高质量图像。
但这类方法通常要求:
- 在每一轮训练中,对完整去噪路径上的多个时间步进行采样;
- 对每个采样步骤执行策略梯度更新;
- 依赖高频率的样本回放与奖励评估。
这导致两个主要问题:
- 计算冗余:早期和中期去噪步骤噪声大、语义模糊,过度优化这些阶段收益有限;
- 梯度稀疏:奖励信号在整个路径上传播衰减,难以有效引导关键阶段的改进。
因此,是否必须在整个去噪轨迹上进行优化?能否聚焦于更具决定性的阶段?
MixGRPO 给出了肯定回答。
核心思路:混合采样 + 滑动窗口
MixGRPO 的核心创新在于解耦采样与优化过程,并通过混合微分方程策略实现效率与性能的平衡。
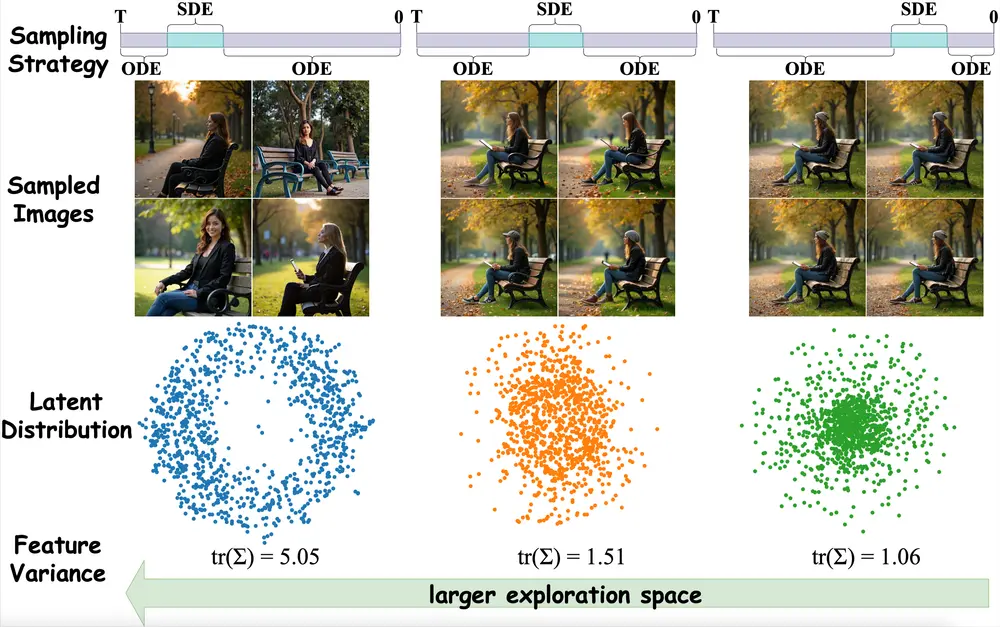
1. 混合 ODE-SDE 采样机制
- 窗口内(关键阶段):采用 SDE 采样,保留随机性,支持探索不同生成路径,适合作为 GRPO 优化的基础;
- 窗口外(稳定阶段):切换为 ODE 采样,以确定性方式快速推进去噪,避免不必要的随机扰动。
⚙️ 简单理解:SDE 像“带噪声的导航”,适合复杂地形探索;ODE 像“高速公路”,适合已知路径的高效通行。
通过这种方式,模型仅在最具优化价值的时间段保留随机性,其余阶段则追求效率。
2. 滑动窗口优化机制
MixGRPO 引入一个可移动的时间窗口,仅在窗口覆盖的时间步上执行 GRPO 优化。窗口通常设置在去噪过程的中前期——此时图像结构尚未定型,优化带来的增益最大。
这一设计带来三重优势:
- 减少优化变量:只需对窗口内步骤计算梯度,大幅降低反向传播开销;
- 集中梯度信号:奖励反馈更聚焦于关键阶段,提升学习效率;
- 支持高阶求解器:窗口外使用 ODE 后,可启用如 DPMSolver++ 等高阶快速求解器,进一步加速前向采样。
该机制类似于强化学习中的“时间折扣”思想:越早的决策影响越大,应优先优化。
3. MixGRPO-Flash:更快的工程实现
基于上述框架,团队进一步推出 MixGRPO-Flash,在以下方面做了增强:
- 使用更高阶的 ODE 求解器处理非窗口区域;
- 优化 KV 缓存复用策略,减少重复计算;
- 调整窗口长度与移动节奏,实现训练稳定性和速度的最佳平衡。
结果是:在几乎不损失性能的前提下,训练速度再次跃升。
实验验证:效率与质量双提升
在多个主流人类偏好对齐基准上,MixGRPO 表现出全面优势:
| 指标 | DanceGRPO | MixGRPO | 提升 |
|---|---|---|---|
| ImageReward | 1.436 | 1.629 | +13.4% |
| HPSv2 | 58.7 | 61.3 | +4.4% |
| Pick Score | 0.512 | 0.541 | +5.7% |
✅ 所有指标均基于相同基础模型(FLUX.1 Dev)测试。
更重要的是训练效率:
- MixGRPO:训练时间降低 49%;
- MixGRPO-Flash:训练时间减少 71%,接近三分之一耗时。
此外,MixGRPO 在单奖励与多奖励(HPSv2 + ImageReward + Pick Score)设置下均表现稳健,说明其对奖励信号组合具有良好的适应性。
开源与部署
目前,团队已发布基于 FLUX.1 Dev 架构、采用 MixGRPO 训练的模型版本,支持以下特性:
- 多重奖励模型联合训练(HPSv2、ImageReward、Pick Score);
- 兼容主流扩散采样流程;
- 支持 ODE/SDE 模式切换,便于推理阶段灵活配置。
该模型可用于高质量图文生成、AIGC 内容审核优化、个性化创作辅助等场景。
总结
MixGRPO 并非对 GRPO 的简单加速,而是一种结构化的效率重构。它通过以下方式重新定义了偏好对齐的训练范式:
- 将“全路径优化”转为“关键路径聚焦”;
- 利用 ODE/SDE 的互补性实现采样-优化解耦;
- 为高阶求解器创造应用空间,推动工程落地。
更重要的是,它证明了:在生成模型对齐任务中, smarter 的优化策略,比 brute-force 更有效。
当行业仍在追求更大规模、更多数据时,MixGRPO 提醒我们:算法设计的精细度,才是决定效率上限的关键。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











