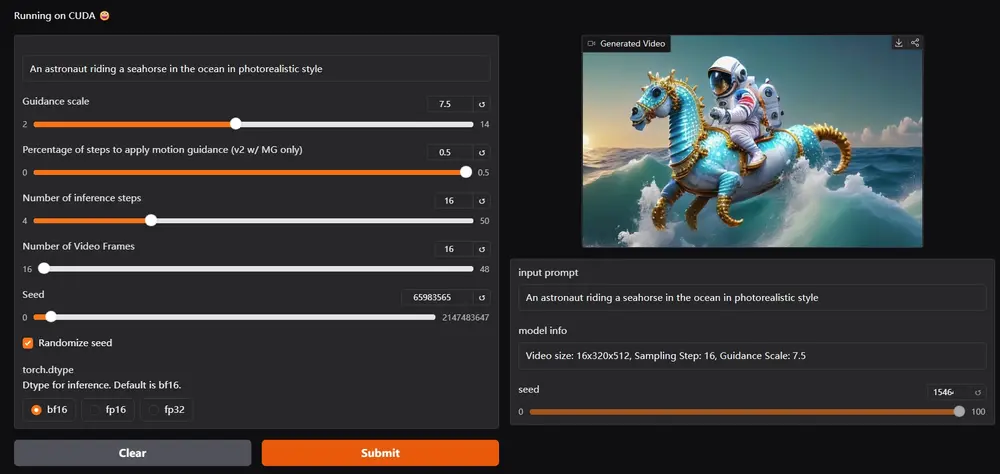
新型视频生成模型T2V-Turbo-v2:基于VideoCrafter2模型提炼,提升视频生成的质量和效率加州大学圣巴巴拉分校、加州大学洛杉矶分校、亚马逊 AGI和滑铁卢大学的研究人员推出新型视频生成模型T2V-Turbo-v2,它旨在提升基于扩散的文本到视频(T2V)生成的质量和效率。简单来说,这项技术...视频模型# T2V-Turbo-v2# 视频生成模型1年前07830
VectorJourney| Pretend to Travel:卡通插画与真实结合的FLUX LoRA模型VectorJourney| Pretend to Travel是由Muertu基于FLUX.1-dev上训练的LoRA模型,巧妙融合现实与插画元素。前景角色以插画风格呈现,而背景则为逼真的写实风格...Flux衍生# FLUX# LoRA模型# VectorJourney1年前07820
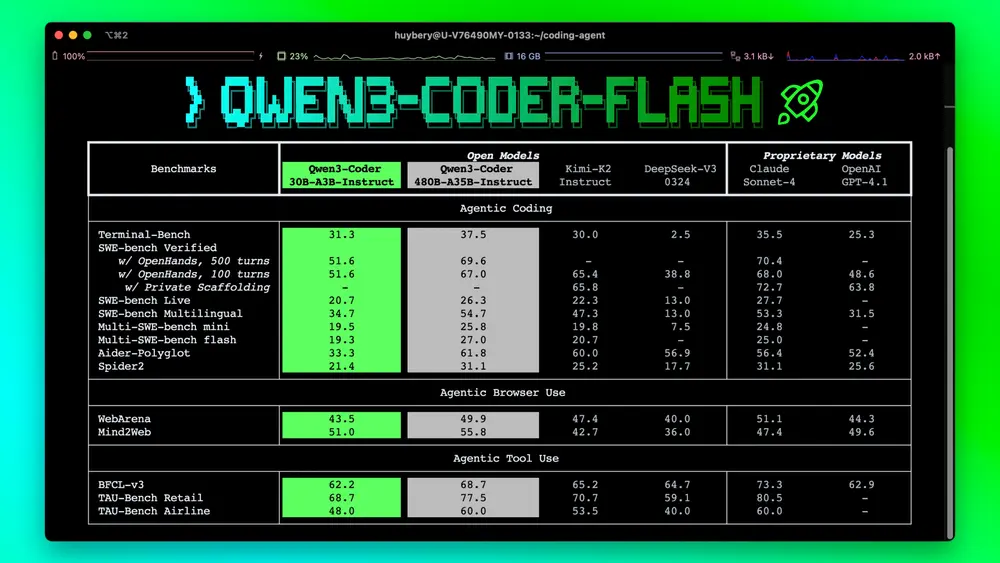
阿里推出 Qwen3-Coder-30B-A3B-Instruct:轻量级代码大模型,支持 256K 上下文继发布超大规模的 Qwen3-Coder-480B-A35B-Instruct 后,阿里通义千问团队近日推出一款更轻量但性能强劲的新版本: Qwen3-Coder-30B-A3B-Instruct 这...大语言模型# Qwen3-Coder-30B-A3B-Instruct# 代码大模型8个月前07730
Shuttle 3 Diffusion:基于 Flux.1 Schnell 构建的一款微调模型,能够以简化的四步流程生成高质量的图像Shuttle 3 Diffusion 是由 ShuttleAI 基于 Flux.1 Schnell 构建的一款微调模型,能够以简化的四步流程生成高质量的图像,其表现与 Flux Dev 或 Pro ...Flux衍生# FLUX.1 [schnell]# Shuttle 3 Diffusion1年前07680
Stable Diffusion XL(SDXL)Stability AI于北京时间2023年 7 月 27 日正式发布 Stable Diffusion XL 首个正式版 1.0,SDXL 1.0 能生成更加鲜明准确的色彩,在对比度、光线和阴影方面...图像模型# AI绘画# SDXL# Stable Diffusion XL1年前07650
Sand AI推出新型视频生成模型MAGI-1:通过自回归预测视频块序列来生成视频MAGI-1是由Sand AI研究团队开发的一种新型视频生成模型。该模型通过自回归预测视频块序列来生成视频,每个视频块由固定长度的连续帧组成。MAGI-1的核心目标是实现高保真、实时、因果一致的视频生...视频模型# MAGI-1# Sand AI# 自回归11个月前07600
统一框架UniFL:通过统一的反馈学习来提升稳定扩散模型(Stable Diffusion)的性能来自字节跳动和中山大学的研究人员推出利用反馈学习机制来全面增强扩散模型的统一框架UniFL,它通过统一的反馈学习来提升稳定扩散模型(Stable Diffusion)的性能。UniFL作为一种通用、高...图像模型# Stable Diffusion# UniFL1年前07600
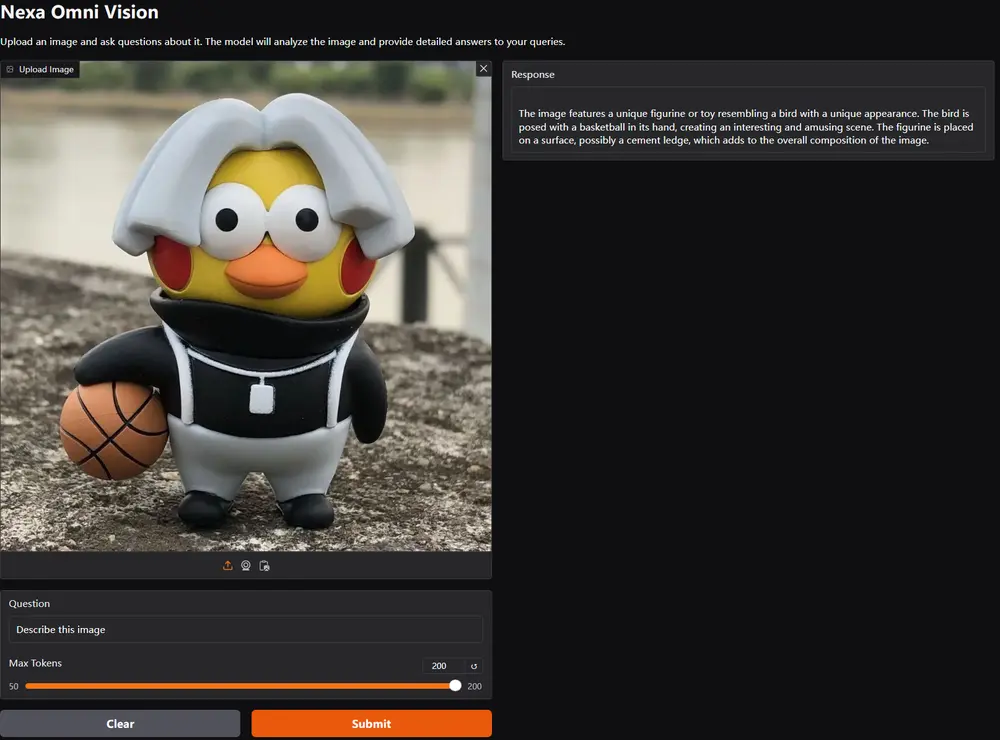
Nexa AI 推出迷你视觉语言模型 OmniVision-968MNexa AI 最新发布了 OmniVision-968M,这是一款专为边缘设备设计的视觉语言模型,它通过技术创新,将图像标记数量大幅减少,显著降低了延迟和计算负担,还提升了处理速度,为边缘计算领域带...多模态模型# Nexa AI# OmniVision-968M# 视觉语言模型1年前07490
腾讯混元发布 HunyuanImage-3.0:800亿参数开源原生多模态模型,实现“语义理解-图像生成”的深度融合腾讯混元项目组正式发布并开源HunyuanImage-3.0——当前开源社区规模最大、性能最强的文生图模型。该模型总参数量突破800亿,推理时每token仅激活130亿参数(兼顾性能与效率),基于原生...图像模型# HunyuanImage-3.0# 腾讯混元6个月前07470
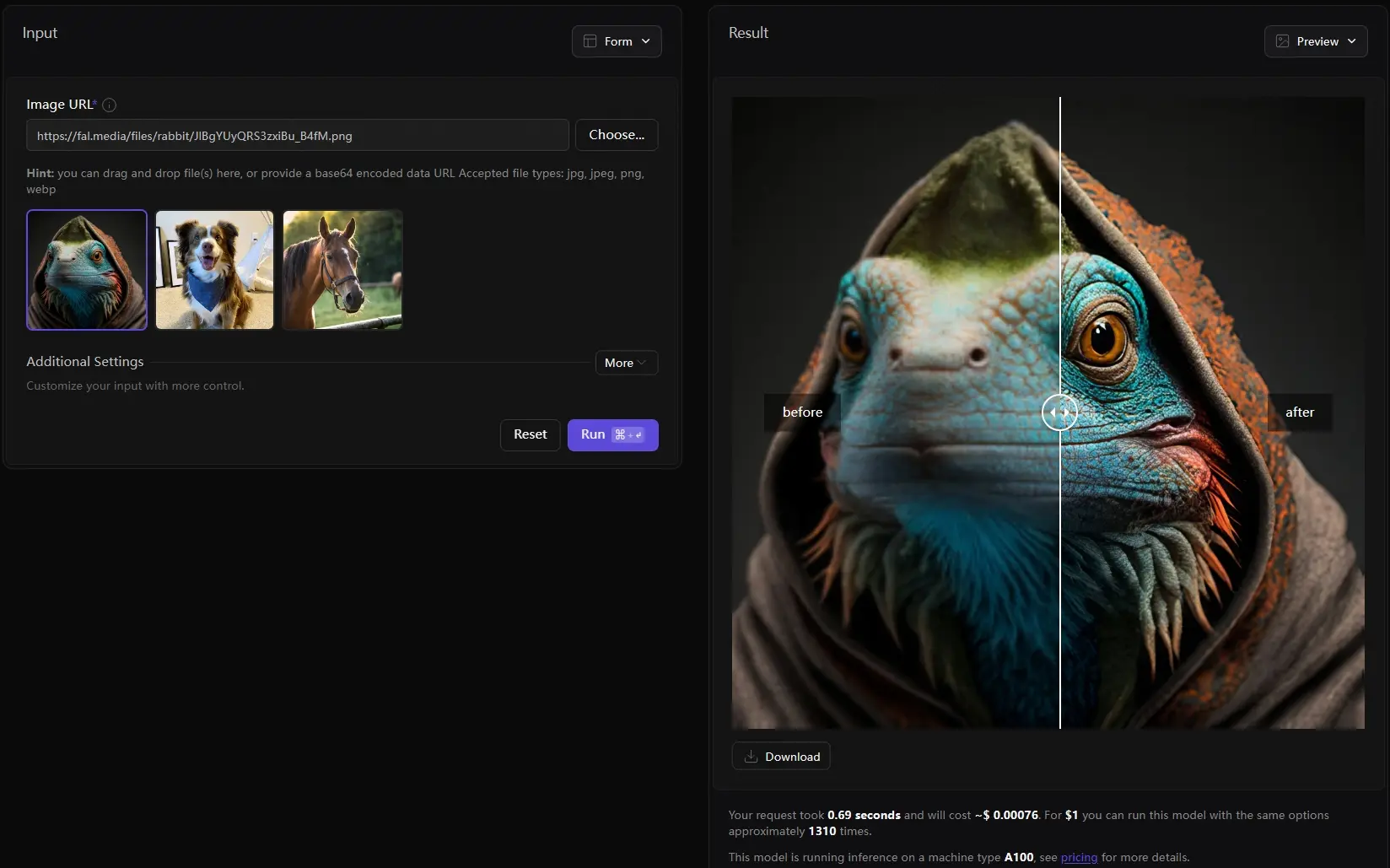
Fal.ai平台推出了新一代GAN 图像放大工具AuraSR的第二版AuraSR-v2Fal.ai平台推出了新一代GAN 图像放大工具AuraSR的第二版,上个月它们推出了AuraSR 第一版后,得到了开源社区积极回应,让他们立刻着手开发新版。AuraSR 以 Adobe 的 Giga...图像模型# AuraSR# AuraSR-v2# Fal.ai1年前07420
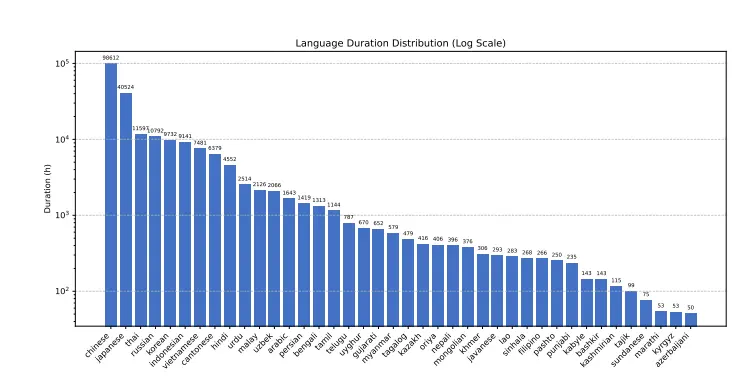
多语言、多任务 ASR 模型Dolphin:支持东亚、南亚、东南亚和中东地区的 40 种东方语言,同时也支持 22 种中国方言近年来,自动语音识别(ASR)技术取得了显著进展,这主要得益于模型架构的改进和大规模数据集的可用性。然而,现有的多语言 ASR 模型(如 Whisper)在处理东方语言时表现不佳,且存在可重复性问题 ...语音模型# ASR 模型# Dolphin# 语音识别12个月前07410
日本团队推出浮世绘风格专用生成模型Evo-Ukiyoe和浮世绘上色模型Evo-Nishikie日本AI团队Sakana AI发布了专门用于生成浮世绘风格的生成模型Evo-Ukiyoe和浮世绘上色模型Evo-Nishikie,此模型是是以转为日语打造的图像生成模型Evo-SDXL-JP为基础,通...图像模型# Evo-Nishikie# Evo-Ukiyoe# 浮世绘1年前07410