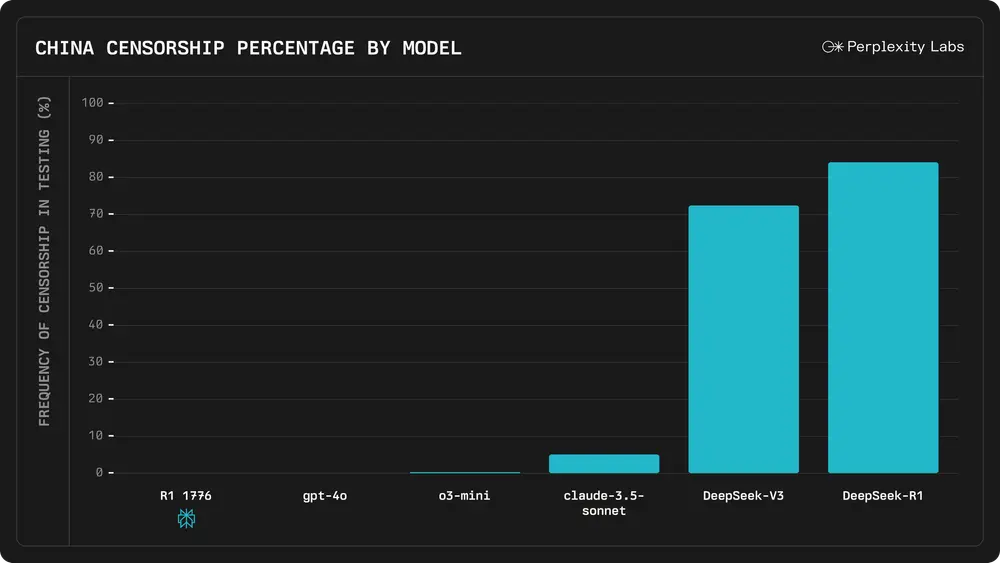
不影响性能!Perplexity 开源基于DeepSeek-R1推出的无审查版本R1 1776R1 1776是Perplexity基于DeepSeek-R1推出的无审查版本,该模型号称提供公正、准确和真实的信息,同时保持高推理能力。目前,用户可以在 HuggingFace 上下载该模型,或者通...大语言模型# DeepSeek-R1# Perplexity# R1 177611个月前07010
基于Mamba架构的自回归(AR)图像生成模型AiM:实现高质量和高效率的图像生成,同时保持推理速度的优势北京邮电大学、中国科学院大学、香港理工大学和中国科学院自动化研究所的研究人员推出自回归(autoregressive, AR)图像生成模型AiM,它基于Mamba架构构建。AiM模型的目的是实现高质量...图像模型# AiM# Mamba架构12个月前06940
3D内容生成模型Magic-Boost:将粗糙的3D模型转换成高质量的3D模型来自南洋理工大学和字节跳动的研究人员推出新型3D内容生成模型Magic-Boost,它能够将粗糙的3D模型转换成高质量的3D资产。Magic-Boost是一种多视角条件扩散模型。它能够通过短暂的SDS...3D模型# 3D模型# Magic-Boost12个月前06910
海贼王漫画风格LoRA模型:One Piece Manga StyleOne Piece Manga Style是一款基于 PONYDIFFUSION XL训练的LoRA模型,此LoRA需要搭配Pony Diffusion模型才能出好图,在书写提示词的时候需要添加触发词...图像模型# LoRA模型# 海贼王12个月前06880
AWPortrait-FL:基于FLUX.1-dev 的人物微调FLUX模型AWPortrait-FL是由DynamicWang在FLUX.1-dev 基础上微调的FLUX模型,其不仅使用了 AWPortrait-XL 的训练数据,还加入了近 2000 张审美价值极高的时尚摄...Flux衍生# AWPortrait-FL# DynamicWang# FLUX模型12个月前06870
阿里发布Qwen3-LiveTranslate-Flash :全球首个视、听、说全模态实时同传大模型阿里通义实验室今日推出 Qwen3-LiveTranslate-Flash——一款基于 Qwen3-Omni 基座模型打造的多语言实时音视频同声传译大模型。 Demo:https://huggingf...语音模型# Qwen3-LiveTranslate-Flash# 实时同传大模型4个月前06860
OpenAI 推出更快的语音转录模型Whisper large-v3-turbo,不牺牲质量、速度提升8 倍在10月1日的DevDay活动中,OpenAI宣布了一项重大更新:推出了Whisper large-v3-turbo语音转录模型。这款新模型在保持质量几乎不变的前提下,处理速度比之前的large-v3...语音模型# OpenAI# Whisper large-v3-turbo# 语音转录模型12个月前06800
新型目标检测模型Mamba-YOLO-World:能够理解并识别各种不同物体的智能系统,即使这些物体在训练时没有被明确标记复旦大学计算机学院、腾讯优图实验室、上海交通大学等的研究人体推出新型目标检测模型Mamba-YOLO-World,它专门设计用于开放词汇检测(Open-Vocabulary Detection,简称O...多模态模型# Mamba-YOLO-World# 目标检测模型12个月前06740
Fish Audio 发布 OpenAudio S1-mini:支持 14 种语言、50+ 情感语气的开源 TTS 模型文本转语音(TTS)领域迎来一位重量级开源选手 —— OpenAudio S1-mini。 这是由 Fish Audio 团队 推出的 S1 模型的轻量化版本,参数规模为 5亿(0.5B),基于超过 ...语音模型# Fish Audio# OpenAudio S1-mini# TTS 模型8个月前06710
Black Forest Labs发布FLUX.1 Tools系列开源模型:增强FLUX.1模型的控制与可操纵性Black Forest Labs发布了FLUX.1 Tools系列开源模型,这是一套旨在为FLUX.1模型增加控制和可操纵性的模型组合,使修改和重建真实及生成的图像成为可能。在发布时,FLUX.1 ...Flux衍生# Black Forest Labs# FLUX.1 Canny# FLUX.1 Depth12个月前06710
智谱AI推出CogVideoX 开源模型的升级版本CogVideoX1.5-5B智谱技术团队对于旗下开源视频生成模型CogVideoX进行了升级,今天释出了CogVideoX1.5-5B 系列模型,相比于原有模型,CogVideoX v1.5 将包含 5/10 秒、768P、16...视频模型# CogVideoX1.5-5B# 智谱AI# 智谱清影12个月前06680
Useful开源自动语音识别 (ASR) 模型Moonshine:专门针对实时转录和语音命令处理进行了优化Useful开源了一款名为 Moonshine 的全新语音转文本模型。这款模型不仅在速度和效率上超越了目前最领先的 OpenAI 的 Whisper 模型,而且在准确率方面也达到了同等水平甚至更优。M...语音模型# Moonshine# 语音识别模型12个月前06650