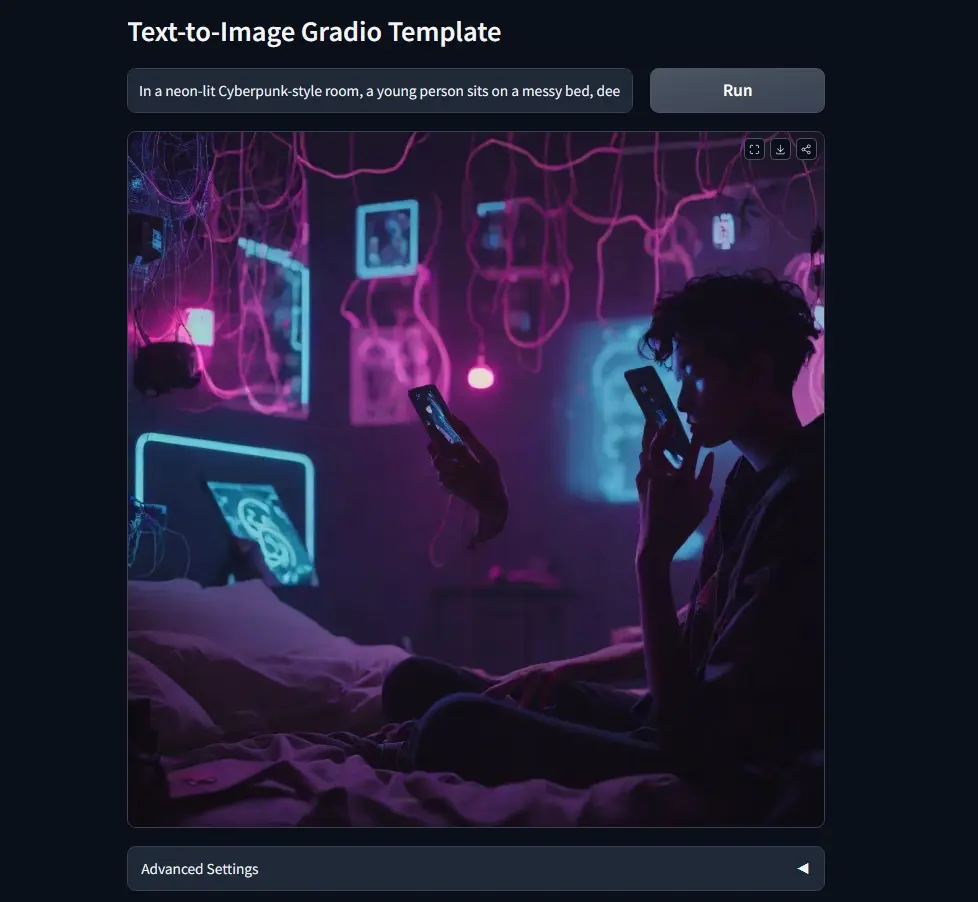
Flex.2-preview:基于 Flux.1 Schnell 微调而成的开源 80 亿参数文生图模型Flex.2-preview 是一款开源的文本到图像扩散模型,具有 80 亿参数,支持通用控制和图像修复功能。它基于 Flux.1 Schnell 微调而成,旨在为用户提供更灵活、更强大的图像生成能力...图像模型# Flex.2-preview# FLUX.1 [schnell]# 文生图模型9个月前06630
LibreFLUX:基于FLUX.1 [schnell]的免费、开源、去蒸馏FLUX 模型LibreFLUX是基于FLUX.1 [schnell] 的去蒸馏版本,旨在提供完整的 T5 上下文长度支持,使用注意力掩码,恢复无分类器指导,并移除了大部分 FLUX 美学微调/DPO。这些改动使得...Flux衍生# FLUX 模型# FLUX.1 [schnell]# LibreFLUX12个月前06630
创新图像生成框架BeyondScene:能够生成高分辨率(超过8K)、以人为中心的场景图像来自韩国首尔国立大学的研究团队推出创新图像生成框架BeyondScene,它能够生成高分辨率(超过8K)、以人为中心的场景图像。这个框架特别擅长处理包含多个人物和复杂细节的场景,即使这些场景的描述超出...图像模型# BeyondScene# 图像生成框架# 高分辨率12个月前06620
腾讯混元发布 HunyuanImage-3.0:800亿参数开源原生多模态模型,实现“语义理解-图像生成”的深度融合腾讯混元项目组正式发布并开源HunyuanImage-3.0——当前开源社区规模最大、性能最强的文生图模型。该模型总参数量突破800亿,推理时每token仅激活130亿参数(兼顾性能与效率),基于原生...图像模型# HunyuanImage-3.0# 腾讯混元4个月前06610
IterComp:为了解决文本到图像生成中的复杂和组合问题而设计的新框架清华大学、北京大学、LibAI Lab、中国科学技术大学、牛津大学和普林斯顿大学的研究人员推出AI绘画新框架IterComp,它是为了解决文本到图像生成中的复杂和组合问题而设计的。简单来说,就是当你给...图像模型# IterComp# 文本到图像12个月前06580
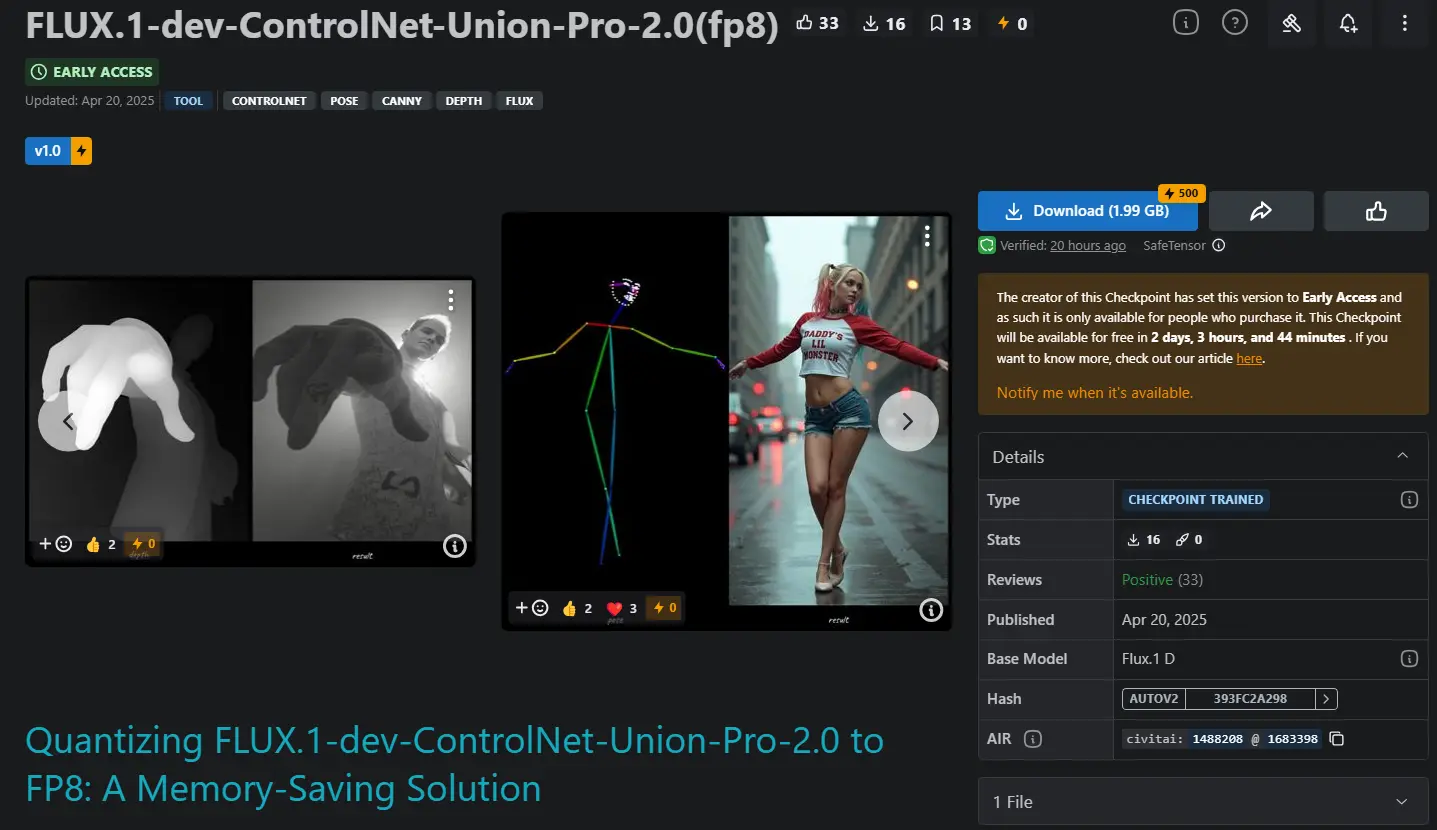
FLUX.1-dev-ControlNet-Union-Pro-2.0 FP8 量化版本:降低对于显存的需求近期Shakker Labs发布了FLUX.1-dev-ControlNet-Union-Pro-2.0,但原版模型对于显存要求过高,于是就有开发者推出了FP8 量化版本。这不是一个经过微调的模型,而...图像模型# FLUX.1-dev-ControlNet-Union-Pro-2.0# FP8 量化版本# Shakker Labs10个月前06560
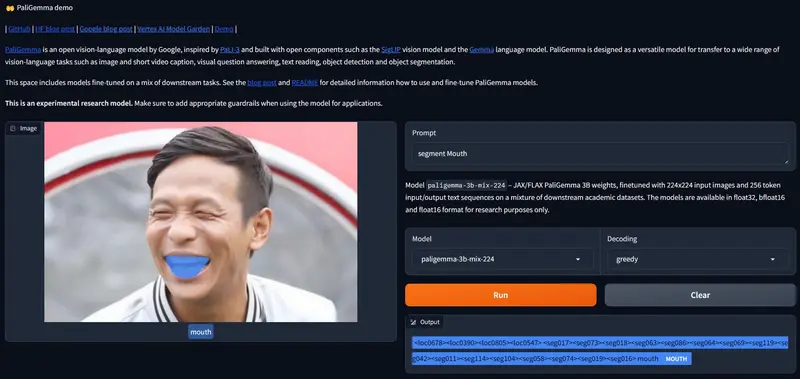
设计灵感来源于PaLI-3!谷歌推出开源视觉语言模型PaliGemmaPaliGemma 是谷歌推出的新一代视觉语言模型家族,其设计灵感来源于PaLI-3,能够接收图像与文本输入并生成文本输出。PaliGemma建立在包括SigLIP视觉模型和Gemma语言模型在内的开...多模态模型# PaliGemma# 谷歌12个月前06530
Black Forest Labs 推出新一代上下文感知图像生成模型FLUX.1 Kontext,支持图像生成及编辑继 FLUX.1 系列大获成功后,Black Forest Labs(黑森林实验室) 在今天正式发布其最新力作 —— FLUX.1 Kontext。 这是一套全新的上下文流匹配生成模型(Context...图像模型# Black Forest Labs# FLUX.1 Kontext# 黑森林实验室8个月前06510
多语言、多任务 ASR 模型Dolphin:支持东亚、南亚、东南亚和中东地区的 40 种东方语言,同时也支持 22 种中国方言近年来,自动语音识别(ASR)技术取得了显著进展,这主要得益于模型架构的改进和大规模数据集的可用性。然而,现有的多语言 ASR 模型(如 Whisper)在处理东方语言时表现不佳,且存在可重复性问题 ...语音模型# ASR 模型# Dolphin# 语音识别10个月前06500
新型框架Diffusion-KTO:用于调整文生图模型,使其生成的图像更符合人类的偏好加州大学洛杉矶分校、松下人工智能研究中心和 Salesforce 人工智能研究中心的研究人员推出新型框架Diffusion-KTO,它专门用于调整文生图模型,使其生成的图像更符合人类的偏好。这个过程不...图像模型# Diffusion-KTO# 文生图模型12个月前06480
Stability AI推出Stable Diffusion 3Stability AI推出Stable Diffusion 3模型的早期预览版本,这是我们迄今为止功能最为强大的文生图模型,在处理多主题提示、图像质量和拼写能力方面都有显著的提升。 Prompt: ...图像模型# Stability AI# Stable Diffusion 312个月前06460
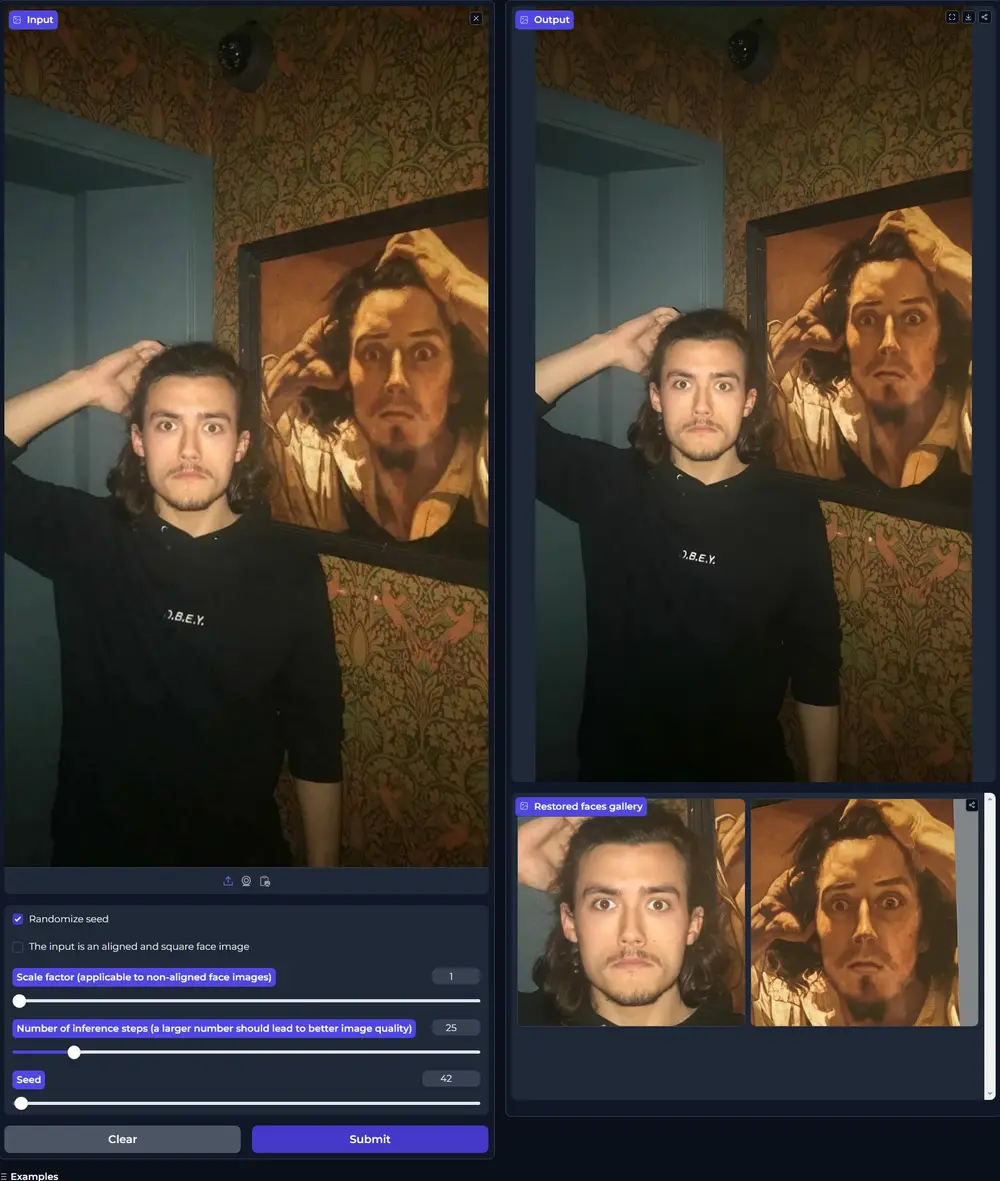
图像恢复算法PMRF:改善从损坏的图像中恢复出高质量、逼真图像以色列理工学院的研究人员推出图像恢复算法PMRF(Posterior-Mean Rectified Flow,后验均值校正流),这个算法的目标是改善从损坏的图像中恢复出高质量、逼真图像的方法。具体来说...图像模型# PMRF# 图像恢复算法12个月前06440

![LibreFLUX:基于FLUX.1 [schnell]的免费、开源、去蒸馏FLUX 模型](https://pic.sd114.wiki/wp-content/uploads/2024/10/1729674970-LibreFLUX.webp~tplv-o4t1hxlaqv-image.image)