来自韩国首尔国立大学的研究团队推出创新图像生成框架BeyondScene,它能够生成高分辨率(超过8K)、以人为中心的场景图像。这个框架特别擅长处理包含多个人物和复杂细节的场景,即使这些场景的描述超出了现有预训练扩散模型(SDXL)的文本编码器容量限制。
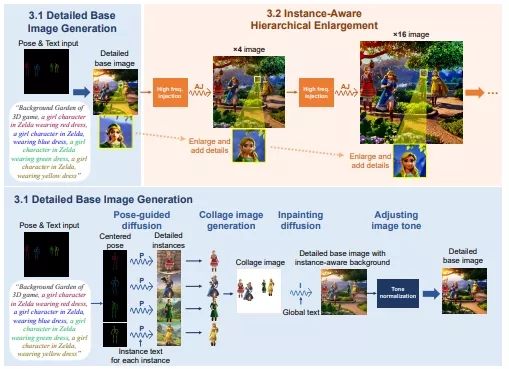
BeyondScene采用分阶段和分层的方法,首先生成一个详细的基础图像,聚焦于多个人物实例创建中的关键元素,并处理超出扩散模型令牌限制的详细描述。接着,它无缝地将基础图像转换为更高分辨率的输出,不仅突破了训练图像的大小限制,还通过创新的实例感知分层放大过程,将文本和实例的细节完美融入。这一过程包括开发团队提出的高频注入前向扩散和自适应联合扩散技术。BeyondScene在文本描述的对应性和自然性方面超越了现有方法,为高级应用开辟了新的道路。这些应用可以在不需要昂贵重新训练的情况下,创建出超出预训练扩散模型能力的高分辨率人类中心场景。

例如,如果你想要创建一个包含多个穿着不同服装的舞者在歌剧院舞台上表演的场景,你可以给BeyondScene提供一个详细的文本描述,它就能生成一个高分辨率的图像,其中每个舞者的姿态、服装和表情都与描述相符,而且整个场景看起来非常自然和逼真。
主要功能和特点:
- 高分辨率输出: BeyondScene能够生成超过8K分辨率的图像,这意味着它能够创建极其细致和清晰的场景图像。
- 文本-图像对应性强: 该框架能够根据详细的文本描述生成图像,确保图像内容与文本描述高度一致。
- 自然逼真: 生成的人物和场景看起来自然,避免了常见的图像生成中的不真实或扭曲的效果。
- 超越标记限制: 它能够处理超出预训练模型标记限制的复杂文本描述,使得可以描述更多的细节和元素。
工作原理:
BeyondScene采用了分阶段的层次化方法。首先,它生成一个详细的基础图像,专注于多个人物的关键元素和超出标记限制的详细描述。然后,通过一种新颖的实例感知层次化放大过程,将这个基础图像转换为更高分辨率的输出,同时保持对文本和实例的敏感性。这个过程包括高频注入的前向扩散和自适应联合扩散,这些技术有助于在放大图像的同时增加细节和清晰度。

具体应用场景:
- 动画和游戏制作: BeyondScene可以用于创建高质量的游戏背景和角色,提供更加丰富和逼真的视觉体验。
- 电影和视觉效果: 在电影制作中,它可以用于生成复杂的场景背景,或者创造特定的视觉效果。
- 虚拟现实和增强现实: 该框架可以用于生成用于虚拟现实或增强现实应用的高分辨率和高度逼真的场景。
- 广告和市场营销: 制作高质量的广告图像,特别是当需要根据详细的文本描述来定制场景时。
- 艺术创作: 艺术家和设计师可以使用BeyondScene来创作独特的数字艺术作品或视觉概念设计。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...