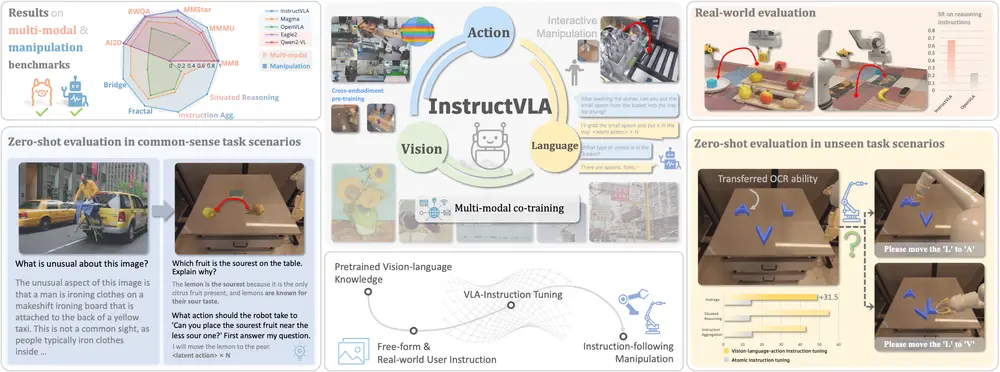
端到端的 VLA 模型InstructVLA:让机器人真正“听懂”指令并准确执行要让机器人走进真实世界,完成诸如“把苹果放进桌上的红碗”这样的任务,仅靠预设程序远远不够。它必须具备两项关键能力: 理解复杂语义——分辨“红碗”是颜色还是材质?“桌上”是否包含边缘? 生成精确动作...多模态模型# InstructVLA# VLA 模型8个月前02270
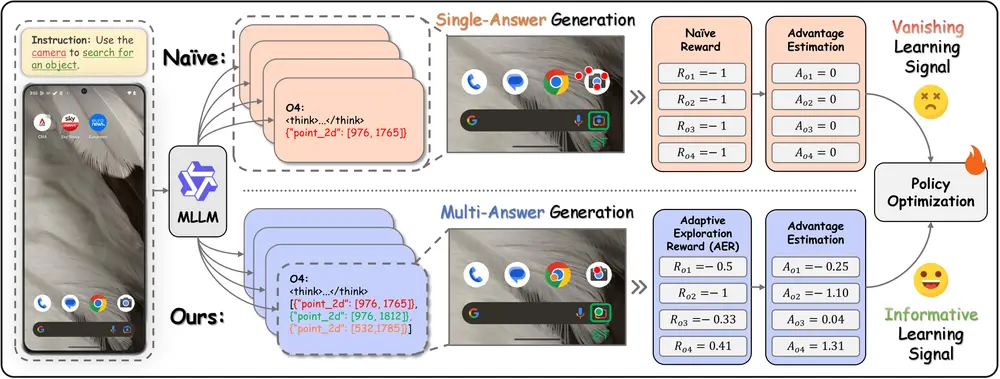
让大模型真正“看懂”界面:InfiGUI-G1提升 GUI 操作中的语义理解能力在图形用户界面(GUI)自动化任务中,让多模态大语言模型(MLLM)准确执行自然语言指令,远不只是“点击坐标”那么简单。真正的挑战在于:既要精准定位界面上的元素(空间对齐),又要正确理解指令背后的意图...多模态模型# InfiGUI-G18个月前02350
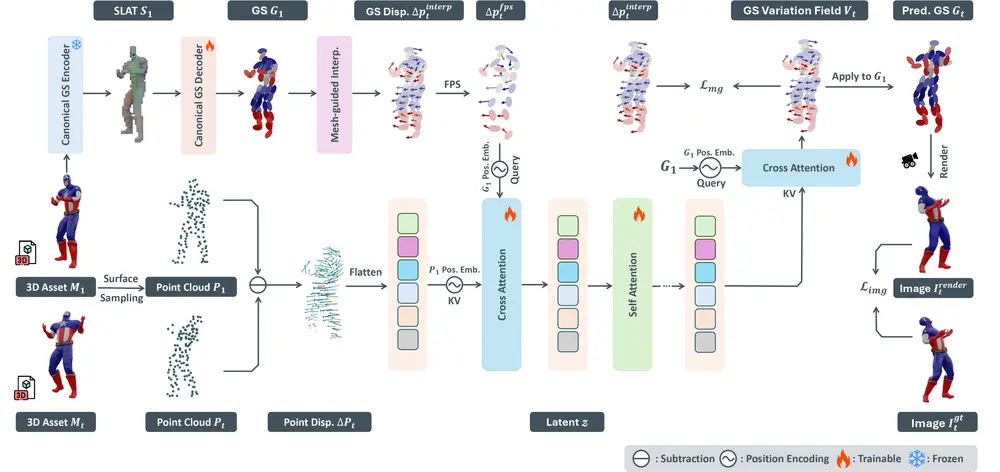
中科大&微软提出GVFDiffusion:从单个视频生成动态3D,实现高效4D生成你有没有想过: 仅凭一段手机拍摄的旋转物体视频,就能重建出一个可自由操控、动态连贯的3D模型? 这不是特效,而是AI正在实现的能力。 中国科学技术大学与微软的研究团队近日提出 GVFDiffusion...3D模型# GVFDiffusion8个月前01560
图像质量评估体系HPSv3:用“人类偏好”重新定义图像生成质量评估当AI画出一张“森林中休息的鹿”,我们如何判断它画得好不好? 是看它是否包含“鹿”和“树木”?还是看光影是否自然、构图是否美观、整体是否令人愉悦?显然,后者更贴近人类的真实审美。然而,当前大多数文本到...图像模型# HPSv3# 图像质量评估体系8个月前04670
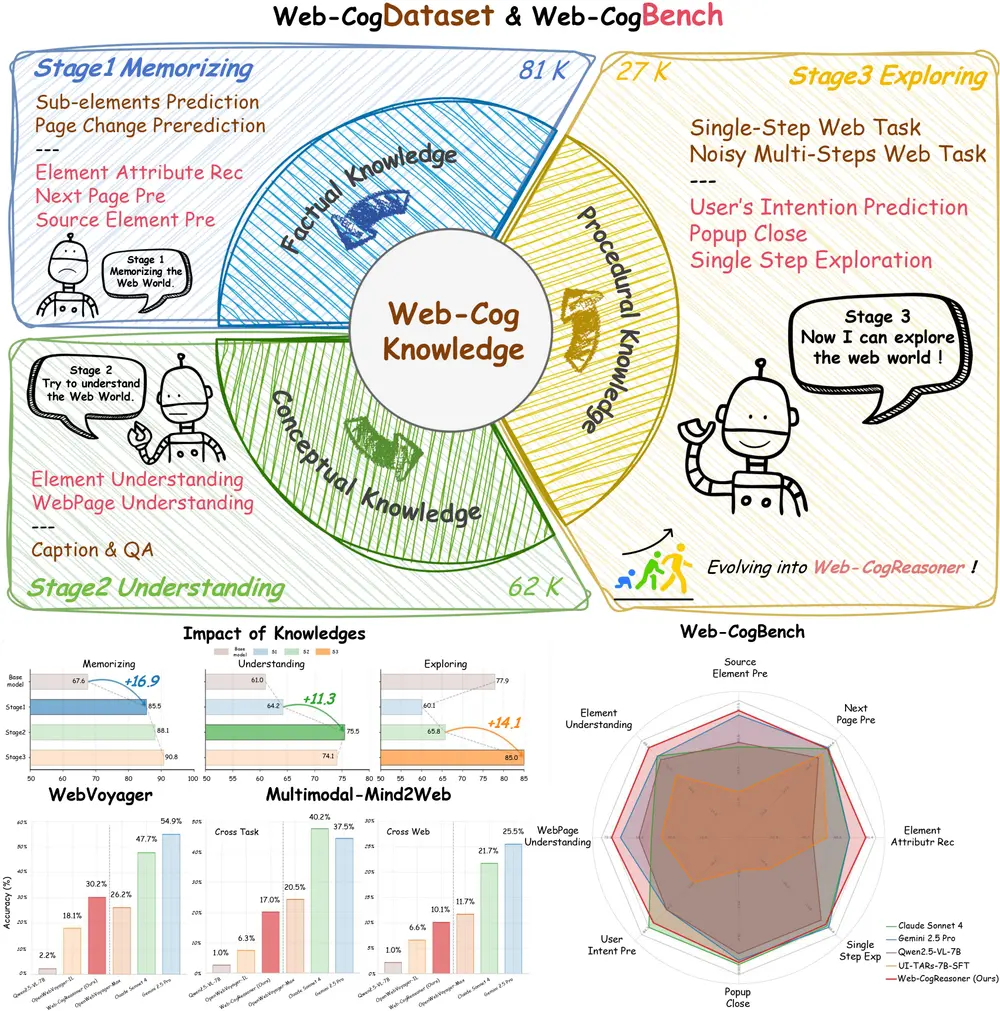
多模态智能体的“认知升级”:Web-CogReasoner 如何让网络代理真正“会思考”联合研究团队:西南财经大学、上海交通大学、中南大学、Hithink研究院、西湖大学、哈尔滨工业大学、曼彻斯特大学、加州大学洛杉矶分校、阿德莱德大学、复旦大学、中国科学院深圳先进技术研究院 当AI开始替...多模态模型# Web-CogReasoner# 多模态智能体8个月前01330
阿里发布 Qwen3-4B 双模型:小参数,大能力,原生支持 256K 上下文在大模型“军备竞赛”愈演愈烈的今天,阿里巴巴通义实验室反其道而行之,推出两款 40 亿参数级别 的小型语言模型: Qwen3-4B-Instruct-2507:面向多语言、高响应速度的通用指令模型 Q...大语言模型# Qwen3-4B-Instruct-2507# Qwen3-4B-Thinking-2507# 通义实验室8个月前04300
腾讯发布混元Large-Vision:支持原生分辨率输入的旗舰级多模态理解模型腾讯正式推出 混元Large-Vision —— 一款面向复杂任务的旗舰级多模态大模型。该模型在文档理解、数学推理、视频分析和三维空间感知等高难度场景中表现突出,同时具备卓越的多语言支持能力,在LMA...多模态模型# Hunyuan-Large-Vision# 混元Large-Vision# 腾讯8个月前06080
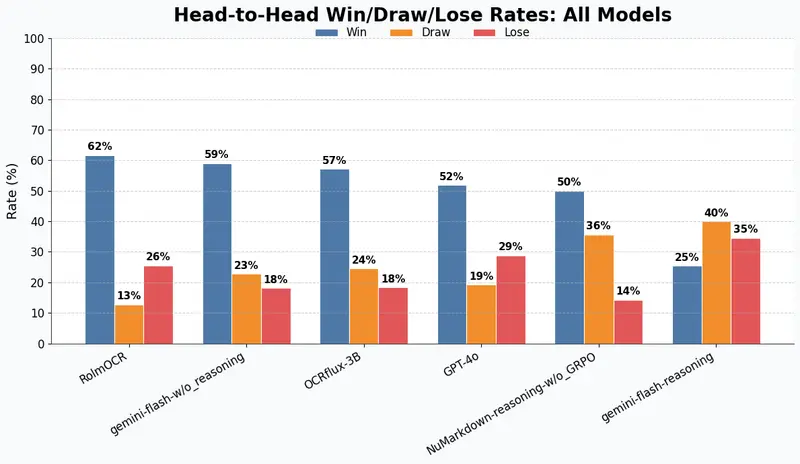
NuMarkdown-8B-Thinking 发布:首个具备推理能力的 OCR 视觉语言模型NuMind 正式推出 NuMarkdown-8B-Thinking —— 据称是首个专为文档理解设计、具备显式推理能力的视觉语言模型(VLM)。该模型专注于将扫描文档或图像中的复杂版式内容,精准转换...多模态模型# NuMarkdown-8B-Thinking# OCR 视觉语言模型8个月前03150
阿里云 PAI发布 Wan2.2-Fun:扩展Wan2.2文生视频与可控视频生成的能力边界阿里云 PAI 团队昨日正式推出 Wan2.2-Fun 系列模型,作为其 VideoX-Fun 项目的重要更新,进一步扩展了文生视频与可控视频生成的能力边界。 模型:https://huggingfa...视频模型# Wan2.2-Fun# 阿里云 PAI8个月前03900
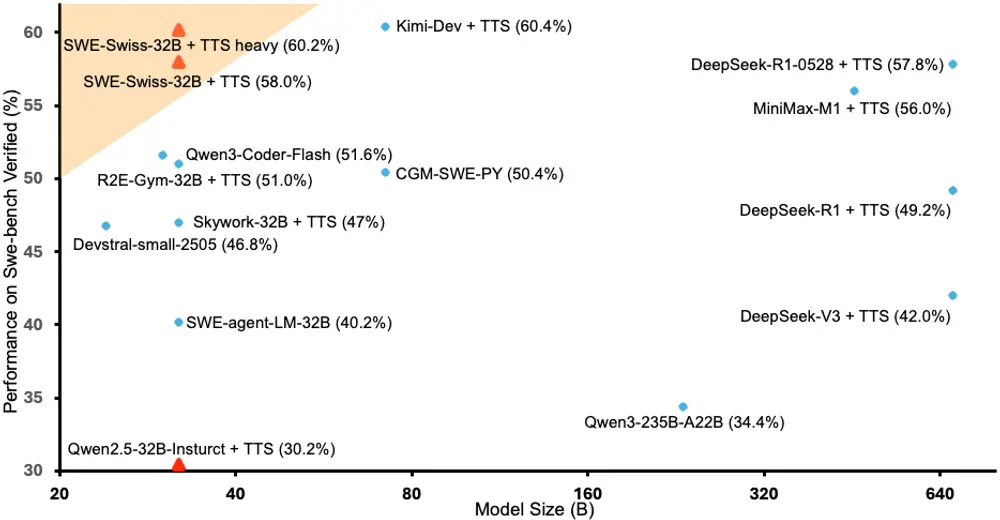
SWE-Swiss-32B 发布:一个在软件修复任务上达到顶尖水平的 32B 开源模型由北京大学、字节跳动 SEED 团队与香港大学联合研发的 SWE-Swiss-32B 正式亮相。 该模型在 SWE-bench Verified 基准测试中取得 60.2% 的通过率,不仅在同规模开源...大语言模型# SWE-Swiss# SWE-Swiss-32B8个月前05610
小红书 hi lab 开源首个视觉-语言模型:dots.vlm1小红书 hi lab 团队正式发布 dots.vlm1 ——这是“dots”模型家族中的首款视觉-语言模型(VLM),标志着其在多模态理解方向上的重要突破。 GitHub:https://github...多模态模型# dots.vlm1# 小红书8个月前03740
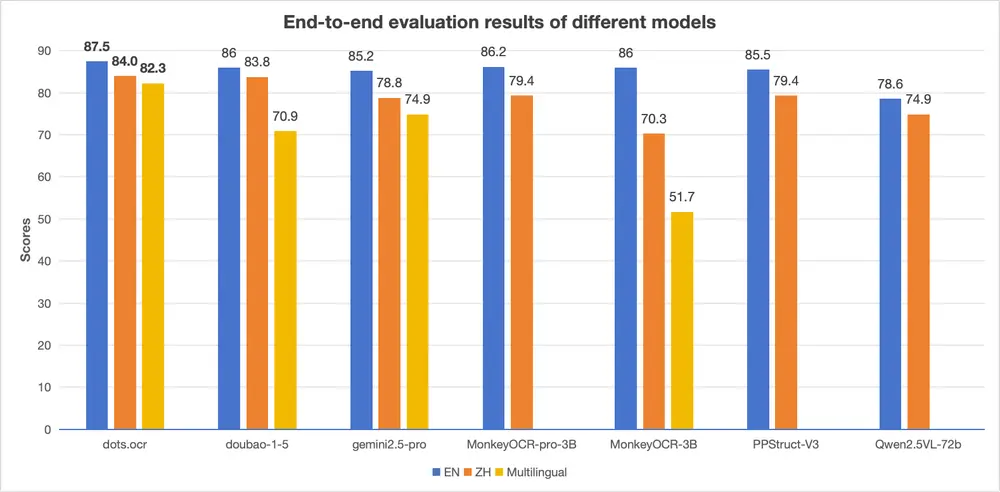
小红书 hi lab 推出 dots.ocr:一个更高效、更统一的文档解析方案小红书 hi lab 团队近期发布了一款名为 dots.ocr 的多语言文档解析模型。它不是传统OCR工具的简单升级,而是一次架构层面的重构——将布局检测与内容识别统一在一个视觉-语言模型(VLM)中...多模态模型# dots.ocr# 小红书8个月前01,1420