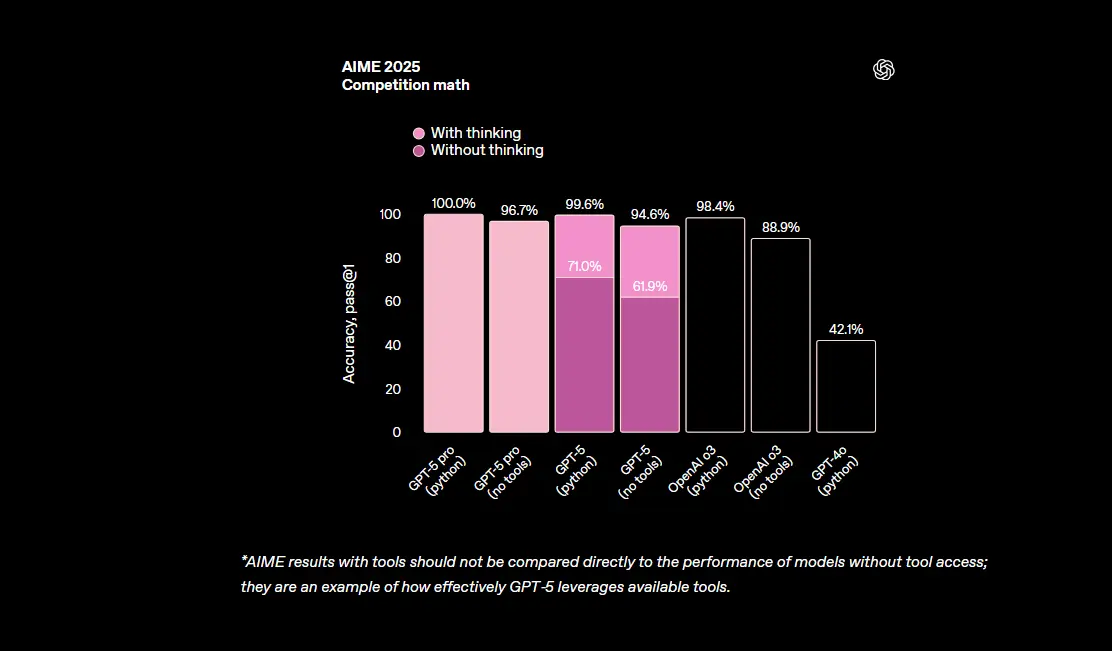
OpenAI 发布 GPT-5:更智能、更诚实、更实用的统一模型OpenAI在今天发布了其最新模型GPT-5,这是它们迄今为止最智能、快速和实用的模型,内置思考能力,将专家级智能赋予每个人。(官方博文介绍) OpenAI隆重推出 GPT-5,这是penAI迄今最好...大语言模型# GPT-5# OpenAI8个月前03720
昆仑万维天工项目组推出多模态模型Skywork UniPic:能够统一处理图像理解、文本到图像生成和图像编辑等多种任务昆仑万维天工项目组推出多模态模型Skywork UniPic,它是一个参数量为15亿的自回归模型,能够统一处理图像理解、文本到图像生成和图像编辑等多种任务,而无需针对每个任务单独适配或连接模块。 Gi...多模态模型# Skywork UniPic# 多模态模型8个月前03930
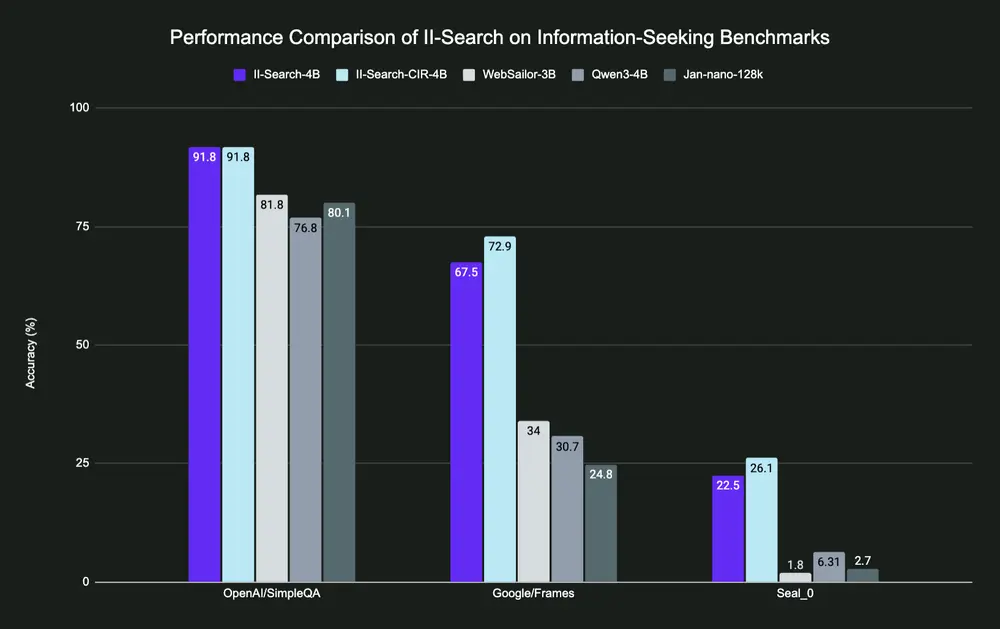
Intelligent Internet 发布两款新型搜索推理模型:II-Search-4B 与 II-Search-CIR 4BIntelligent Internet(II)正式推出两款专注于信息检索与复杂推理的开源语言模型: II-Search-4B:面向多跳检索与事实验证的高效4B级模型 II-Search-CIR 4B...大语言模型# II-Search-4B# II-Search-CIR 4B# Intelligent Internet8个月前02280
面壁智能发布高效多模态模型 MiniCPM-V 4.0:4B 模型,超越 GPT-4.1-mini面壁智能正式推出 MiniCPM-V 4.0 —— MiniCPM-V 系列中最新的高效多模态模型,参数总量仅 4.1B,却在图像理解能力上实现显著突破。 GitHub:https://github...多模态模型# MiniCPM-V 4.0# 面壁智能8个月前01910
KittenML推出一个仅 25MB 的开源文本转语音模型Kitten TTSKittenML推出一款名为 Kitten TTS 的新型文本转语音(TTS)模型,它以极小体积、无需 GPU 和高质量语音合成能力为特点,专为边缘设备和轻量级部署场景设计。 GitHub:https...语音模型# Kitten TTS# 文本转语音模型8个月前05910
Anthropic发布 Claude Opus 4.1:代理任务、现实世界编码和推理的升级Anthropic今天发布了 Claude Opus 4.1,这是对 Claude Opus 4 在代理任务、现实世界编码和推理方面的升级。我们计划在未来几周发布对模型的更大改进。 Claude Op...大语言模型# Anthropic# Claude Opus 4.18个月前03850
OpenAI 发布两款高性能模型免费可商用开源大模型gpt-oss-120b 与 gpt-oss-20b,在本地运行接近 o4-mini 的模型OpenAI 今日正式发布两款开放权重语言模型:gpt-oss-120b 和 gpt-oss-20b。 这是自 GPT-2 以来,OpenAI 首次向公众开放其语言模型权重,标志着公司在开放性与透明度...大语言模型# gpt-oss-120b# gpt-oss-20b# OpenAI8个月前01630
Mistral AI宣布推出 Codestral 25.08 和完整的 Mistral 企业编码栈Mistral AI 今日宣布推出 Codestral 25.08,并同步发布其完整的 Mistral 企业编码栈(Mistral Coding Stack for Enterprise)。 这不是一...大语言模型# Codestral 25.08# Mistral AI8个月前02450
Deep Cogito发布Cogito v2 预览版:从“思考更多”到“直觉更强”的推理范式跃迁Deep Cogito 今日正式发布 Cogito v2 预览版,推出四款开源混合推理模型: 70B 密集型 109B MoE 405B 密集型 671B MoE 其中,671B MoE 是当前全球最...大语言模型# Cogito v2# Deep Cogito8个月前04730
3D-R1:让大模型真正理解三维空间的统一推理模型上海工程技术大学与北京大学计算机学院联合提出一个开源通用模型 3D-R1,旨在提升3D视觉-语言模型(3D Vision-Language Models, 3D-VLMs)在复杂场景中的推理能力,推动...3D模型# 3D-R1# 推理模型8个月前01360
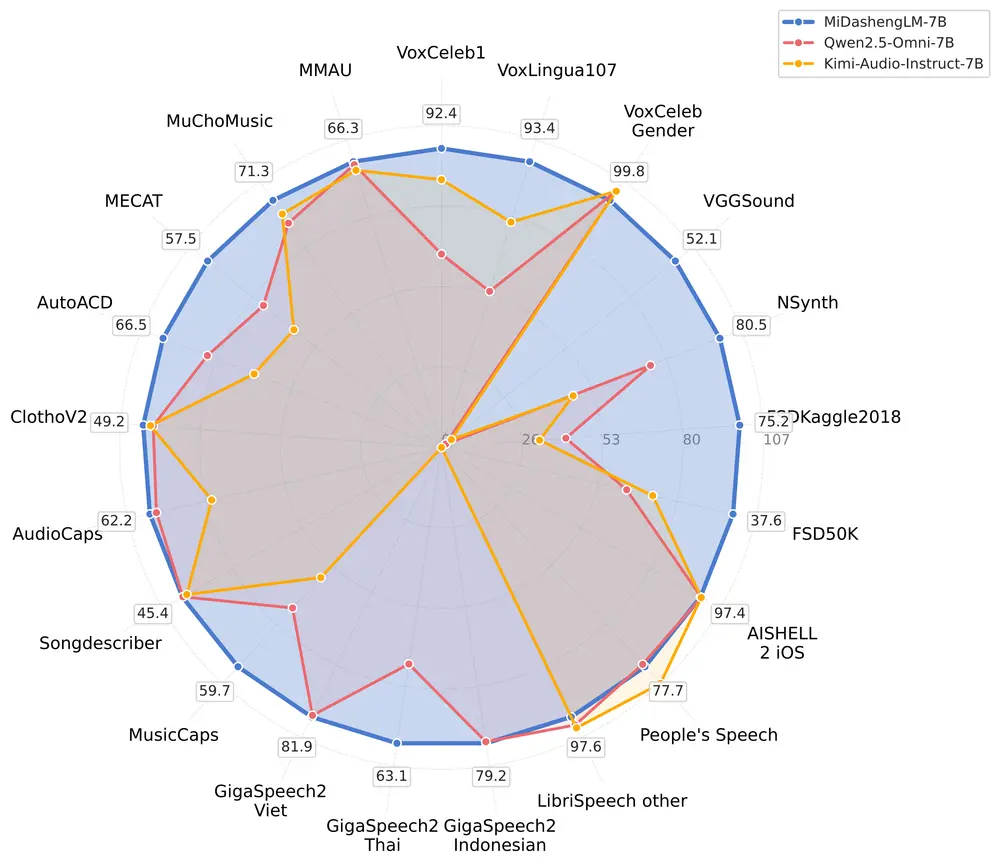
小米自研声音理解大模型 MiDashengLM-7B 正式开源小米正式发布并全量开源其自研声音理解大模型 —— MiDashengLM-7B。该模型在性能与效率上实现双重突破,标志着小米在多模态AI领域,尤其是声音理解方向的又一次重要进展。 GitHub 主页...语音模型# MiDashengLM-7B# 声音理解大模型# 小米8个月前03030
腾讯混元发布四款小尺寸开源模型,端侧 AI 应用迎来新选择继此前开源大尺寸模型后,腾讯混元团队近日推出四款全新小尺寸开源模型,参数量分别为 0.5B、1.8B、4B 和 7B。这些模型专为低功耗、资源受限场景设计,可在消费级显卡、笔记本电脑、手机、智能座舱及...大语言模型# 腾讯混元8个月前03790