PixNerd:无需 VAE,用神经场实现端到端像素级图像生成在图像生成领域,扩散模型已成主流,但其典型架构依赖变分自编码器(VAE)将图像压缩至低维潜在空间,再在该空间进行生成。这种“两阶段”范式虽能降低计算负担,却也带来了解码伪影与信息损失等固有缺陷。 为突...图像模型# PixNerd8个月前03440
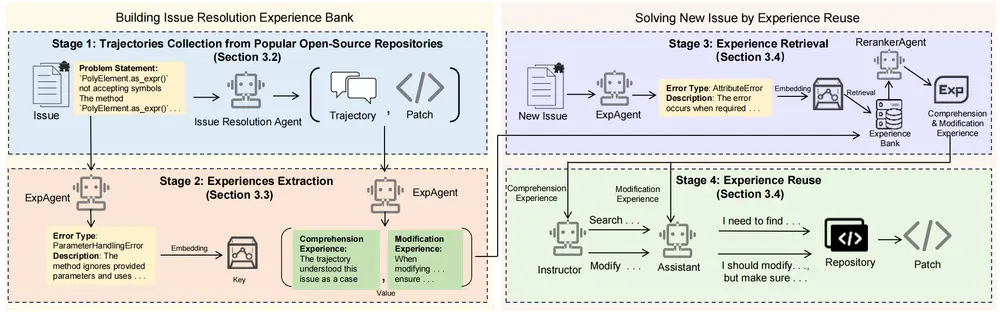
面向代码修复与优化任务的经验驱动型实验框架SWE-Exp在自动化软件工程领域,一个长期存在的挑战是:如何让 AI 代理不仅“能修代码”,还能“会总结、能举一反三”? 上海交通大学、华为、加州大学圣地亚哥分校与西安电子科技大学的联合研究团队近日提出 SWE...大语言模型# SWE-Exp# 软件工程8个月前02310
阿里 Qwen 项目组发布 Qwen-Image:首个 20B 级 MMDiT 图像生成基础模型阿里 Qwen 项目组正式推出 Qwen-Image,这是通义千问系列中首个专注于图像生成的基础大模型。基于 20B 参数的 MMDiT(Multimodal Diffusion Transforme...图像模型# Qwen-Image# 图像生成模型8个月前04830
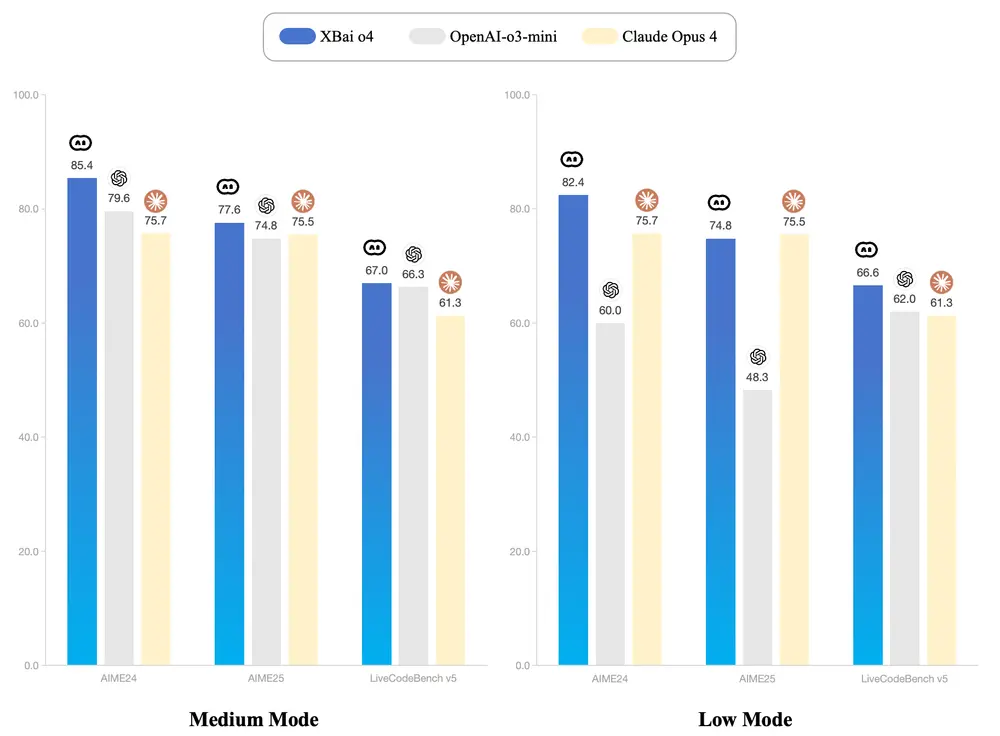
问小白开源基于反思型生成范式训练的推理模型XBai o4问小白发布了XBai o4,o=open,o4代表其开源的第四代大模型技术。XBai o4在复杂推理能力方面表现出色,在Medium模式下,XBai o4 现已全面超越OpenAI-o3-mini。 ...大语言模型# XBai o4# 问小白8个月前02350
字节跳动Seed项目组推出基于大语言模型(LLM)的自动化定理证明系统 Seed-Prover字节跳动Seed项目组推出基于大语言模型(LLM)的自动化定理证明系统 Seed-Prover,Seed-Prover 通过结合 LLM 的推理能力和形式化语言(如 Lean)的验证能力,实现了对数学...大语言模型# Seed-Prover# 字节跳动# 自动化定理证明8个月前01050
MiniMax-Remover:港中大等联合提出高效视频目标移除新方法在视频编辑中,目标移除是一项关键任务:从视频中删除指定对象(如行人、车辆、水印),同时保持背景的视觉一致性与时间连贯性。然而,现有方法常面临三大挑战: 生成伪影或“幻觉对象” 推理速度慢,依赖高步数采...视频模型# MiniMax-Remover8个月前02030
GPT-IMAGE-EDIT-1.5M:用 GPT-4o 重构开源图像编辑数据集在图像生成领域,闭源模型如 GPT-4o、IDEF-2 和 DALL·E 3 已展现出令人惊叹的指令遵循能力,能够精准执行复杂的文本引导编辑任务。相比之下,开源社区虽有进展,却始终受限于高质量、大规模...图像模型# GPT-Image-Edit# GPT-IMAGE-EDIT-1.5M# 图像编辑模型8个月前01860
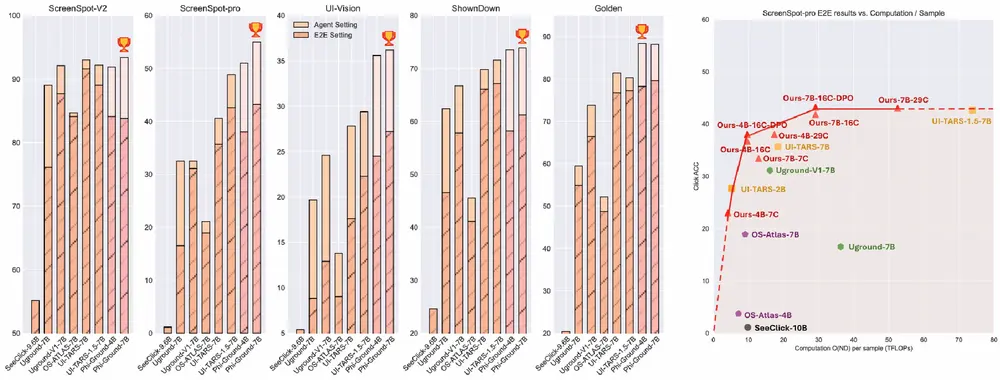
微软推出Phi-Ground:提高计算机界面(GUI)定位(grounding)的准确性微软推出一个名为 Phi-Ground 的模型家族,旨在提高计算机界面(GUI)定位(grounding)的准确性。GUI 定位是计算机使用代理(CUAs)执行实际操作的核心组件,类似于机器人中的机械...大语言模型# Phi-Ground# 微软8个月前02020
DreamScene:用 GPT-4 规划 + 3D 高斯建模,实现端到端文本生成 3D 场景从一句“现代客厅,带沙发和挂墙电视”,到一个完整、一致、可编辑的 3D 场景——这曾是 3D 内容创作的理想。如今,中国科学技术大学、南洋理工大学、香港科技大学(广州)与奥胡斯大学联合提出的 Drea...3D模型# 3D 场景# DreamScene8个月前02550
腾讯混元项目组联合北京大学提出新框架MixGRPO:用混合微分方程提升图像对齐效率在图像生成领域,如何让模型输出更符合人类审美与偏好,已成为对齐研究的核心目标。基于流匹配(Flow Matching)的生成模型近年来展现出强大潜力,而 Group Relative Policy O...图像模型# MixGRPO8个月前03720
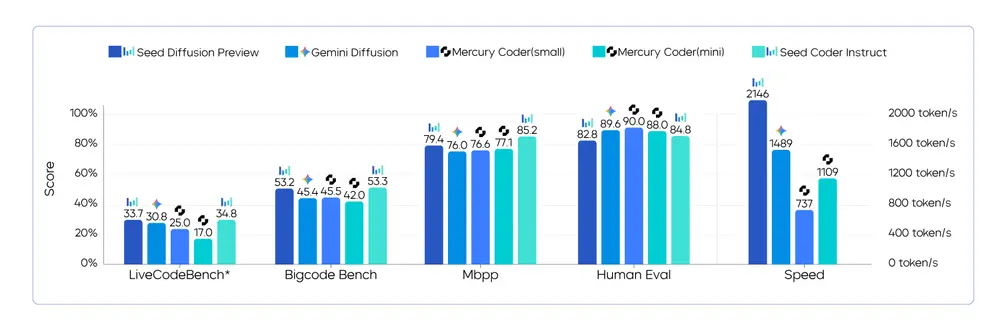
字节跳动 Seed 团队推出Seed Diffusion:打破自回归瓶颈,实现 5.4 倍代码生成加速字节跳动 Seed 团队近期发布了一款实验性语言模型——Seed Diffusion 预览版,它采用离散状态扩散机制,专注于代码生成任务,在推理速度上实现了显著突破:最高可达 2,146 token...大语言模型# Seed Diffusion# 字节跳动8个月前01500
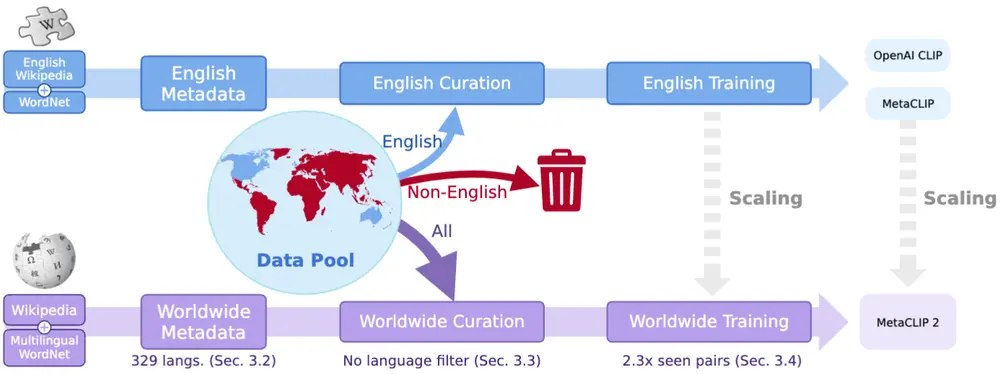
Meta发布新型多语言对比语言-图像预训练(CLIP)模型MetaCLIP 2MetaCLIP 2 是一种新型的多语言对比语言-图像预训练(CLIP)模型,旨在从全球范围内的网络数据中学习图像和文本的表示。传统的 CLIP 模型主要基于英语数据进行训练,而 MetaCLIP 2...大语言模型# Meta# MetaCLIP 28个月前01500