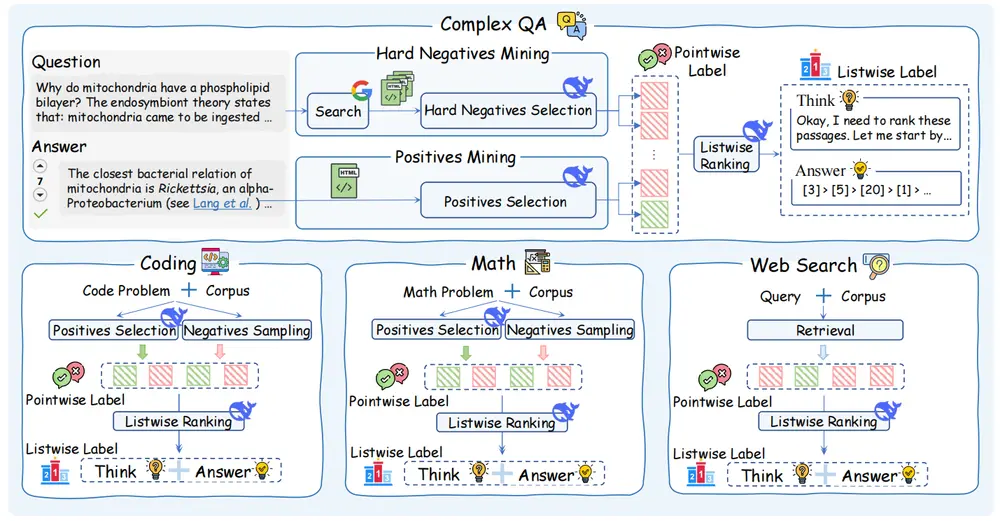
新型段落排序模型 ReasonRank:通过强大的推理能力提升段落排序任务的性能中国人民大学高岭人工智能学院、百度公司和卡内基梅隆大学的研究人员推出新型段落排序模型 ReasonRank,通过强大的推理能力提升段落排序任务的性能。该模型通过引入推理能力,能够更好地理解查询意图,并...大语言模型# ReasonRank# 段落排序模型8个月前03170
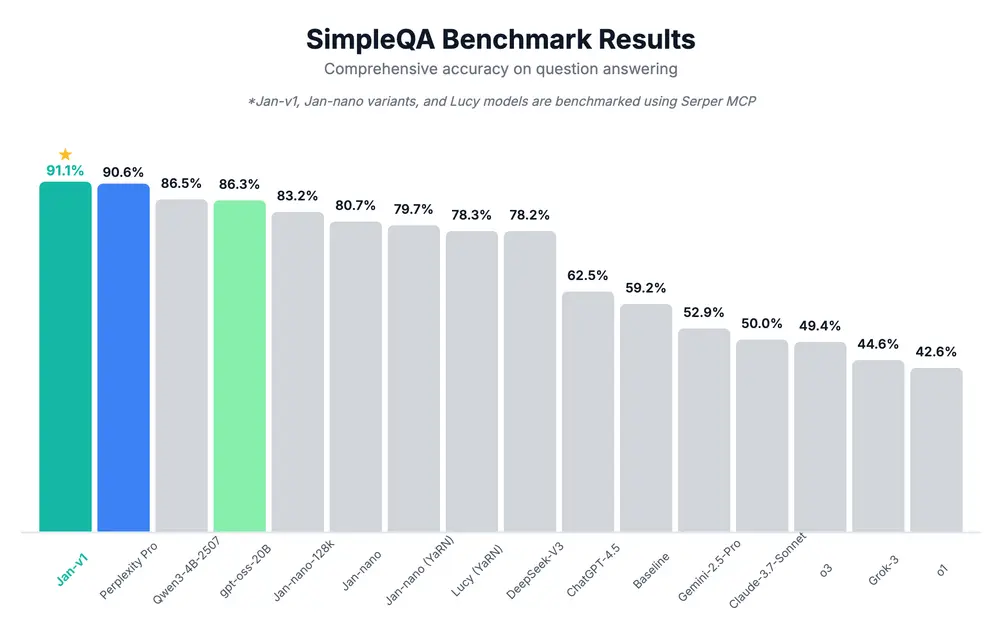
Jan-v1 发布:一个专为本地搜索与深度推理优化的 4B 级开源模型在 AI 搜索领域,闭源商业产品长期占据主导地位。而今天,开源社区迎来了一位强有力的挑战者——Jan-v1。 作为 Jan 模型家族的首个正式版本,Jan-v1 基于 Qwen3-4B-Thinkin...大语言模型# Jan-v1# 搜索8个月前04320
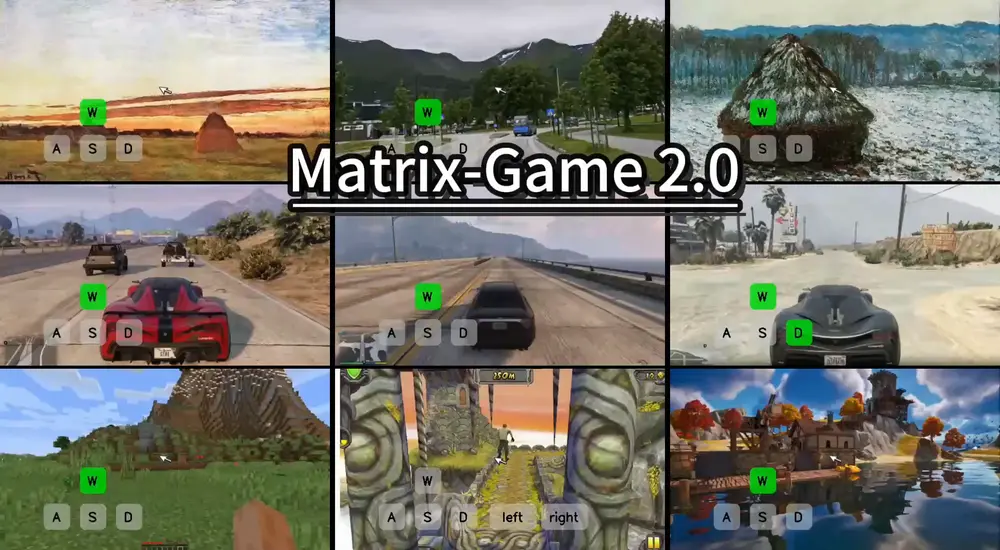
昆仑万维发布 Matrix-Game 2.0:首个开源通用交互式世界模型,把“虚拟世界”推向生产线DeepMind 最近发布的 Genie 3 让世界再次看到了“交互式世界模型”的潜力:一个模型,即可生成可玩、可控、长序列的虚拟环境。用户只需按下方向键,就能在一个由 AI 实时渲染的世界中自由探索...多模态模型# Matrix-Game 2.0# 交互式世界模型# 昆仑万维8个月前03270
阿里发布 Omni-Effects:首个支持空间可控复合特效生成的统一框架在现代电影与视频制作中,视觉特效(VFX)是实现创意表达的核心工具。然而,传统 VFX 制作成本高昂、周期长,依赖专业团队和复杂软件。 近年来,AI 视频生成模型为 VFX 提供了更具成本效益的替代方...视频模型# Omni-Effects# 视觉特效8个月前02380
腾讯微信视觉团队发布 Stand-In:轻量级身份保持视频生成新框架在文本到视频(T2V)生成领域,一个长期存在的难题是:如何让生成的视频中的人物始终“长成你想要的样子”? 尽管现有模型能生成流畅、高质量的视频,但在身份一致性(identity-preserving...视频模型# Stand-In# 视频生成框架7个月前05400
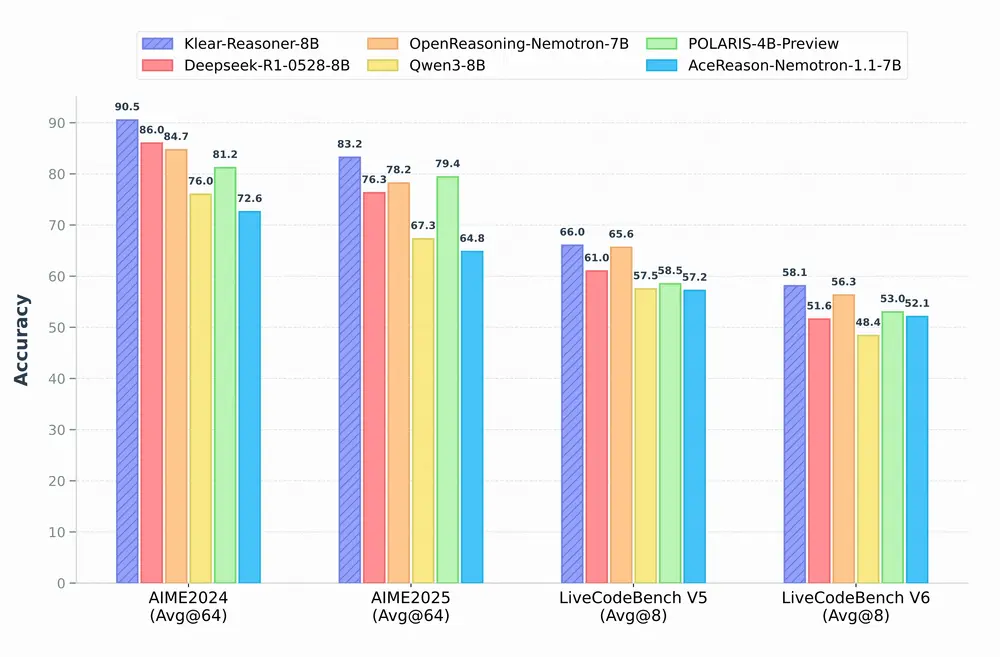
快手Klear项目组推出推理模型 Klear-Reasoner:结合长链推理监督微调和梯度保留剪辑策略优化来提升模型在数学和编程任务中的推理能力快手Klear项目组推出推理模型 Klear-Reasoner,它通过结合长链推理(Long Chain-of-Thought, Long CoT)监督微调和梯度保留剪辑策略优化(Gradient-P...大语言模型# Klear-Reasoner# 快手8个月前01980
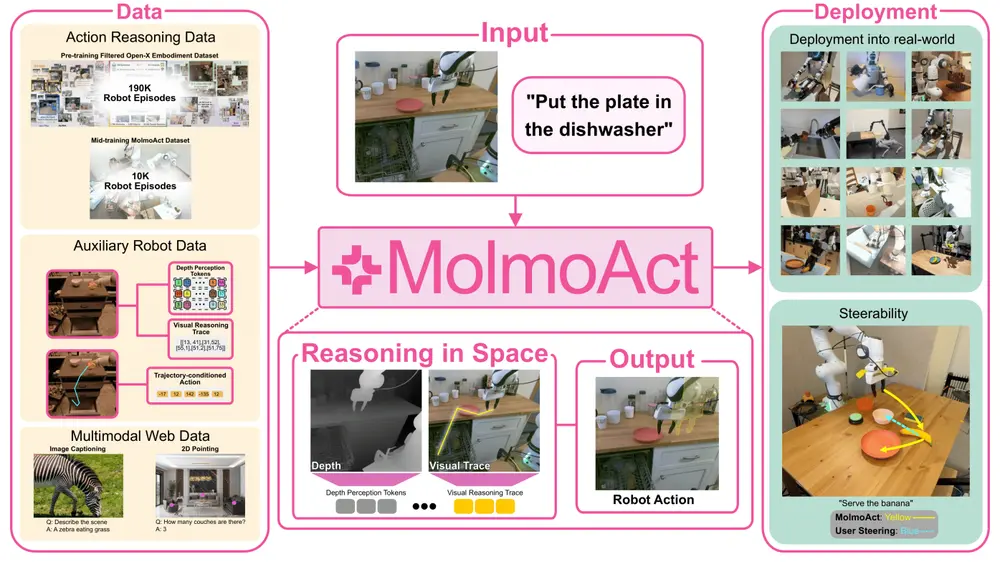
机器人行动推理模型MolmoAct:通过结构化的三阶段推理流程(感知、规划和控制)将视觉、语言和行动相结合,使机器人能够更智能地执行任务艾伦AI研究所和华盛顿大学的研究人员推出机器人行动推理模型MolmoAct ,它通过结构化的三阶段推理流程(感知、规划和控制)将视觉、语言和行动相结合,使机器人能够更智能地执行任务。MolmoAct ...多模态模型# MolmoAct# 机器人行动推理模型8个月前01920
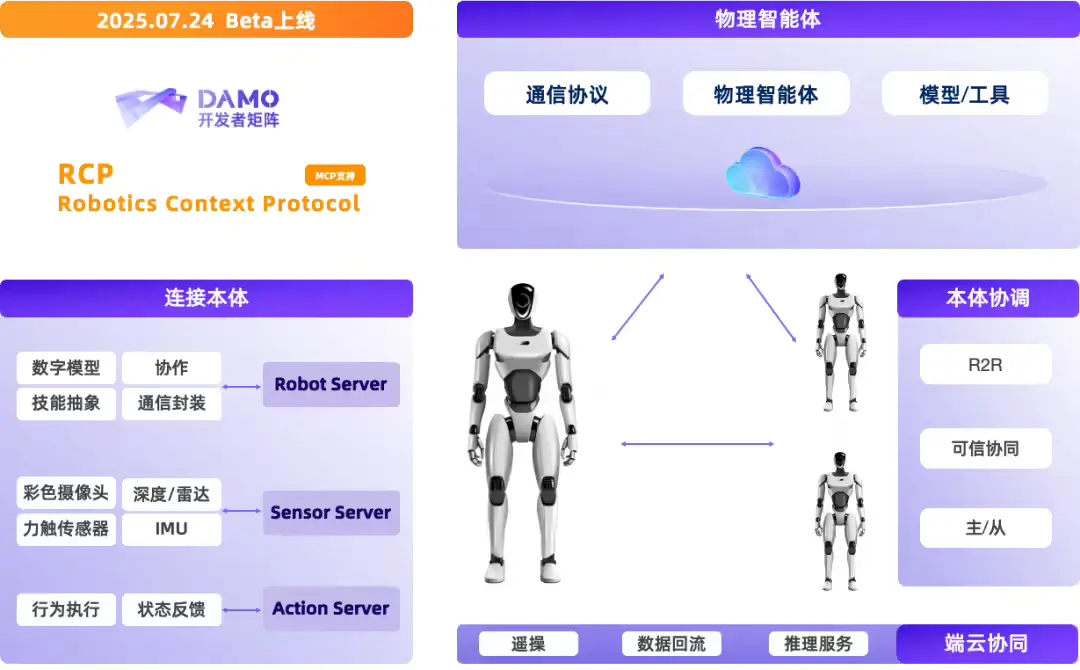
阿里达摩院开源 Rynn 系列:从协议到模型,打通具身智能“最后一公里”在上周开幕的 2025 世界机器人大会上,阿里达摩院宣布开源一套完整的具身智能技术体系,包括: 视觉-语言-动作模型 RynnVLA-001-7B 世界理解模型 RynnEC 机器人上下文协议 Ryn...多模态模型# RynnEC# RynnRCP# RynnVLA-001-7B8个月前04000
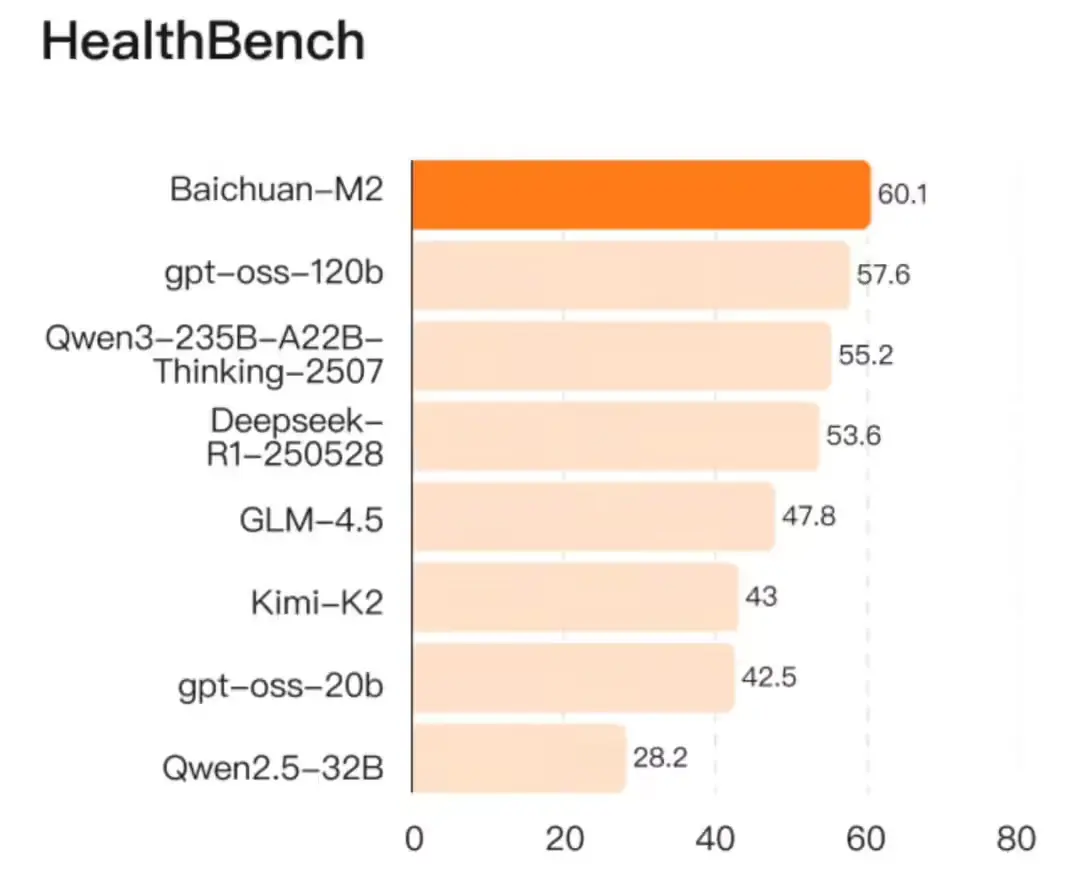
百川智能发布 Baichuan-M2:小模型,大医疗,单卡可部署的开源医疗大模型8 月 6 日,OpenAI 开源两款大模型,主打“低成本部署”与“医疗能力突破”。仅仅五天后,百川智能推出 Baichuan-M2 ——一款在更小参数规模下实现医疗能力反超的开源模型。 模型:htt...大语言模型# Baichuan-M2# 医疗大模型# 百川智能8个月前06920
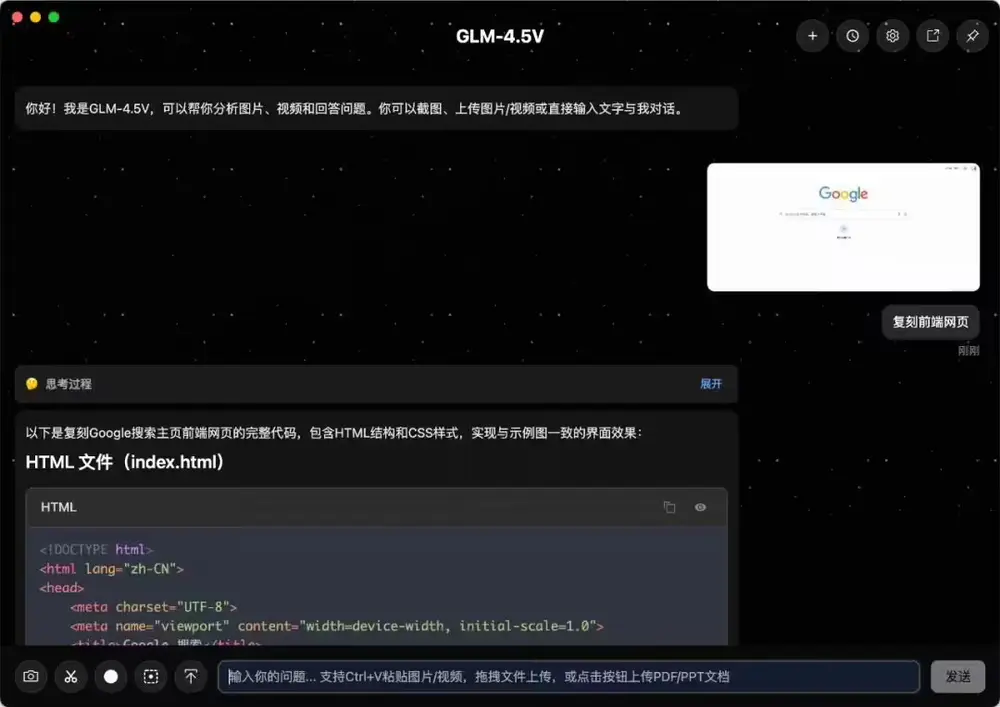
智谱AI发布GLM-4.5V:106B参数的开源视觉推理模型,支持“思考模式”切换今日,智谱 AI 正式推出其新一代开源视觉语言模型 GLM-4.5V,并在魔搭社区与 Hugging Face 同步开源。该模型总参数达 106B,采用 MOE(Mixture of Experts...多模态模型# GLM-4.5V# 智谱AI8个月前01730
LIA-X:一种可解释的肖像动画方法,让面部动作“看得见、控得住”上海人工智能实验室和蔚蓝海岸大学的研究人员推出一种新颖的可解释肖像动画器LIA-X,旨在将驱动视频中的面部动态转移到源肖像上,并实现精细控制。 项目主页:https://wyhsirius.githu...视频模型# LIA-X# 肖像动画8个月前04020
EchoMimicV3:用一个13亿参数模型,统一处理音频、文本、图像驱动的人体动画你是否想象过这样的场景? 输入一段语音,AI 自动生成人物说话的视频,唇形精准对齐,表情自然生动; 给一张静态肖像,加上一句“他开始微笑并挥手”,画面立刻动起来; 结合提示词和参考图,生成一段人物动作...视频模型# EchoMimicV3# 人体动画8个月前02450