视觉语言模型ClipTagger-12B:开源视频理解新标杆,性能对标 GPT-4.1,成本低至 1/15程序化视频理解正在成为构建智能视觉系统的基础设施。从内容审核到自动化标注,从辅助功能到视频搜索引擎,开发者需要一种高效、可靠的方式,将原始视频帧转化为结构化、可搜索、可操作的数据。 为此,Infere...多模态模型# ClipTagger-12B# 视觉语言模型8个月前05180
基于多模态大语言模型的高性能UI智能体UI-Venus蚂蚁集团推出基于多模态大语言模型(MLLM)的高性能UI智能体(UI Agent)UI-Venus,它仅以屏幕截图作为输入,通过强化微调(Reinforcement Fine-Tune, RFT)技术...多模态模型# UI-Venus# UI智能体8个月前03340
Nunchaku发布量化版Qwen-Image模型,支持高效图像生成Nunchaku 官方宣布,其基于Qwen-Image的四个量化版本模型已正式上线 Hugging Face和魔塔!这些模型专为高效文本到图像生成而优化,尤其在复杂文本渲染方面表现突出。 Huggin...图像模型# Nunchaku# Qwen-Image8个月前06310
Meta AI 发布 DINOv3:无需微调、无需标注的下一代视觉模型Meta AI 正式推出 DINOv3 —— 一项在计算机视觉领域具有里程碑意义的自监督学习模型。它不仅刷新了密集预测任务的性能上限,更首次证明:一个通用、冻结的视觉骨干,可以在无需微调的情况下,在多...图像模型# DINOv3# 视觉模型8个月前05780
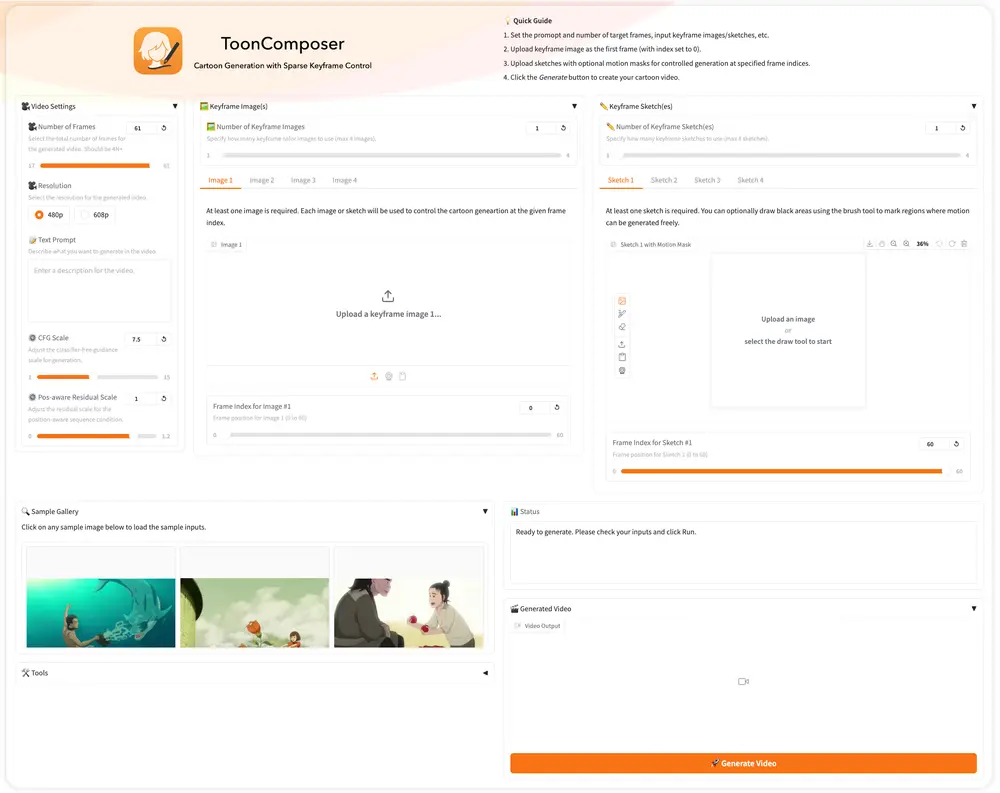
ToonComposer:通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程香港中文大学、腾讯PCG ARC Lab和北京大学的研究人员推出 ToonComposer ,通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程。传统的卡通和动画制作涉及关键帧绘...视频模型# ToonComposer# 卡通制作8个月前01,1620
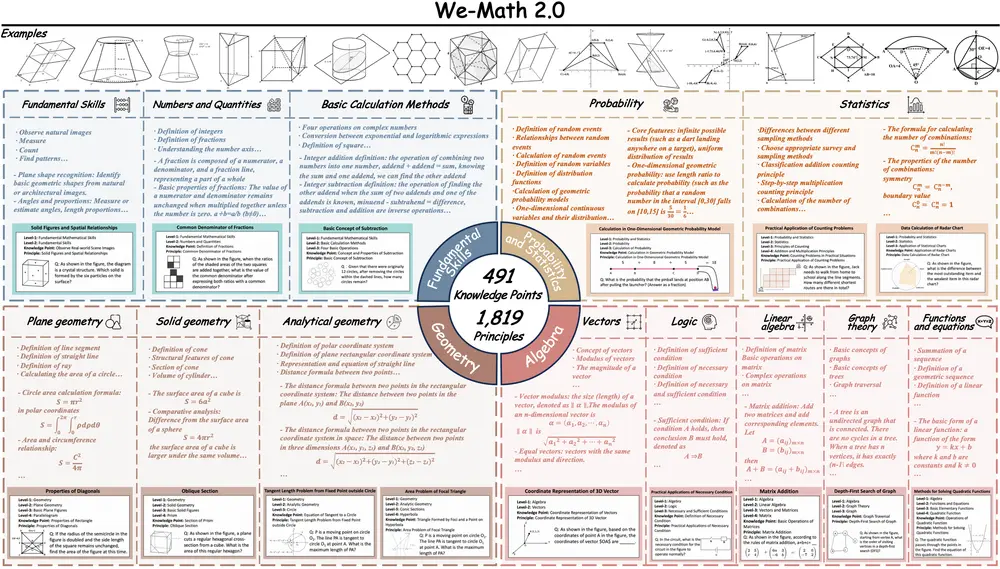
北邮、清华、腾讯联合推出 We-Math 2.0:构建有“知识体系”的数学推理智能体在当前多模态大模型(MLLM)普遍依赖数据驱动“试错式”解题的背景下,北京邮电大学、清华大学与腾讯的研究团队提出了一条不同的技术路径:让模型真正理解数学。 他们联合发布了 We-Math 2.0 ...多模态模型# We-Math 2.0# 数学推理智能体8个月前05580
字节跳动推出具备长期记忆的多模态智能体 M3-Agent字节跳动 Seed 团队推出新型多模态智能体框架M3-Agent ,首次实现了以实体为中心、支持长期记忆积累的自主推理能力。 项目主页:https://m3-agent.github.io GitHu...多模态模型# M3-Agent# 多模态智能体# 字节跳动8个月前03540
阶跃星辰发布 NextStep-1:140 亿参数自回归模型,用“连续令牌”重塑图像生成在图像生成领域,自回归模型长期被视作“文本专家,视觉弱项”——它们擅长逐词生成语言,却难以像扩散模型那样精细构建图像。而如今,阶跃星辰(StepFun)正试图打破这一边界。 GitHub:https...图像模型# NextStep-1# 图像生成# 图像编辑8个月前05390
谷歌发布 Gemma 3 270M:专为微调而生的超高效小模型在开源大模型领域持续发力的谷歌,近日为其 Gemma 模型家族再添新成员——Gemma 3 270M。这是一款拥有 2.7 亿参数的紧凑型模型,专为特定任务微调设计,旨在为开发者提供一个高效、节能、生...大语言模型# Gemma 3 270M# 小模型# 谷歌8个月前03950
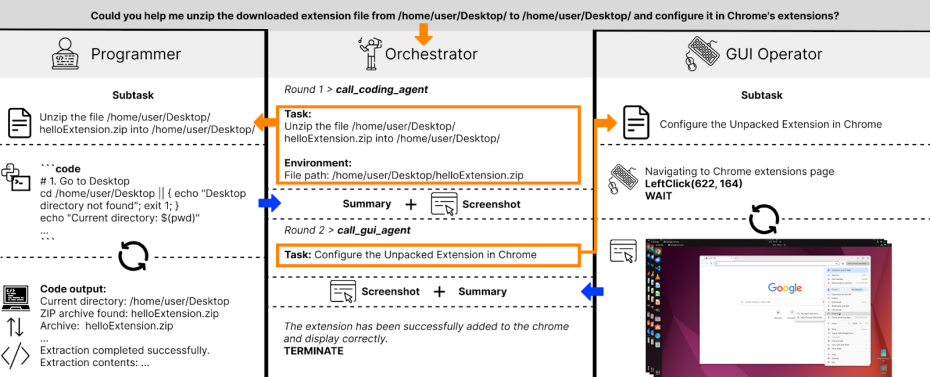
Salesforce 推出 CoAct-1:能写代码的智能体,让自动化迈入新阶段在AI智能体普遍还在“点击屏幕”完成任务的今天,Salesforce 与南加州大学联合研发的 CoAct-1 正在打破这一局限。这款新型计算机操作智能体不仅能识别界面、模拟鼠标点击,更能在任务执行过程...大语言模型# CoAct-1# 智能体8个月前01600
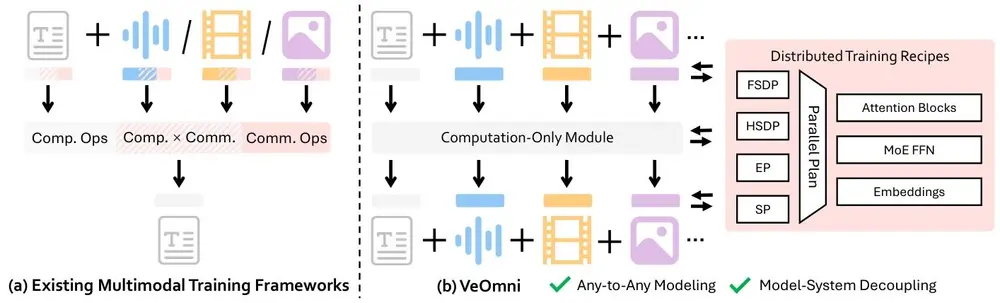
字节跳动开源 VeOmni:一个面向全模态大模型的 PyTorch 原生训练框架在大模型从“能说”向“能看、能听、能理解”演进的当下,多模态统一模型(Omni-Modal LLMs)正成为技术前沿。然而,训练一个同时处理文本、图像、语音和视频的全能模型,仍面临工程复杂、扩展困难...多模态模型# VeOmni# 多模态统一模型# 字节跳动8个月前02170
Pattern Diffusion:专为无缝图案生成而生的扩散模型由开发者 Alex Reid 推出的 Pattern Diffusion,是一个专为生成可平铺(tiling)表面图案而从零训练的扩散模型。它基于 Stable Diffusion 2-Base 架构...图像模型# Pattern Diffusion# 无缝图案8个月前03340